Мало что может быть более раздражающим, чем попытка скрапить сайт, просмотреть результат и не увидеть данные, которые так явно видны в вашем браузере. Или отправка формы, которая должна работать без проблем, но отклоняется веб-сервером. Или когда ваш IP-адрес блокируется сайтом по неизвестным причинам.
Это одни из самых сложных ошибок для решения, не только потому, что они могут быть такими неожиданными (скрипт, который отлично работает на одном сайте, может не работать на другом, казалось бы, идентичном сайте), но и потому, что они, как правило, не выдают явных сообщений об ошибках. Вас идентифицируют как бота, блокируют, и вы не знаете почему.
В этой книге я писал о многих способах выполнения сложных задач на веб-сайтах (отправка форм, извлечение и очистка сложных данных, выполнение JavaScript и т.д.). Эта глава представляет собой сборник различных техник, которые охватывают множество тем (HTTP-заголовки, CSS и HTML-формы, и т.д.). Однако все эти техники объединяет одно: они предназначены для преодоления препятствий, созданных специально для предотвращения автоматического веб-скрапинга сайта.
Независимо от того, насколько полезна эта информация для вас в данный момент, я настоятельно рекомендую хотя бы бегло просмотреть эту статью. Никогда не знаешь, когда она может помочь вам решить сложную ошибку или предотвратить проблему.
Примечание об этике
В первых статьях о скрапинге мы обсуждали правовую неопределенность, связанную с веб-скрапингом, а также некоторые этические принципы, которыми следует руководствоваться. Честно говоря, эта статья, вероятно, самая сложная с этической точки зрения. Мои сайты тоже страдали от ботов, спамеров, веб-скраперов и других нежелательных виртуальных гостей, как возможно и ваши. Так почему же учить людей создавать более эффективных ботов?
Я считаю, что включение этой главы важно по нескольким причинам:
- Существуют совершенно этичные и законные причины для скрапинга некоторых сайтов, которые не хотят быть скрапленными.
- Хотя почти невозможно создать сайт, полностью защищенный от скрапинга (или хотя бы такой, который всё ещё легко доступен для легитимных пользователей), я надеюсь, что информация в этой статье поможет тем, кто хочет защитить свои сайты от вредоносных атак.
- На протяжении всей статьи будут указаны некоторые слабые места в каждой технике веб-скрапинга, которые вы можете использовать для защиты своего сайта. Имейте в виду, что большинство ботов в интернете сегодня просто проводят общий поиск информации и уязвимостей, и использование даже пары простых техник, описанных в этой главе, вероятно, остановит 99% из них. Однако они становятся всё более сложными с каждым месяцем, и лучше быть готовым.
- Как и большинство программистов, я не считаю, что скрытие каких-либо образовательных данных является положительным явлением.
Читая эту статью, помните, что многие из описанных скриптов и техник не следует применять ко всем сайтам, которые вы найдете. Это не только неэтично, но и может привести к тому, что вы получите письмо с требованием прекратить действия или даже что-то хуже. Но я не буду напоминать об этом каждый раз, когда мы будем обсуждать новую технику. Поэтому, как сказал философ Гамп: «Это всё, что я хотел сказать об этом.»
Настройка заголовков
На протяжении всей книги вы использовали библиотеку Python Requests для создания, отправки и получения HTTP-запросов, таких как обработка форм на веб-сайте в главе 10. Requests также отлично подходит для настройки заголовков. HTTP-заголовки — это списки атрибутов или предпочтений, отправляемые вами каждый раз, когда вы делаете запрос к веб-серверу. HTTP определяет десятки редко используемых типов заголовков, большинство из которых не часто применяются. Однако следующие семь полей последовательно используются большинством основных браузеров при установлении соединения (приведены с примерными данными из моего собственного браузера):
- Host: https://www.google.com/
- Connection: keep-alive
- Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
- User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, как Gecko) Chrome/39.0.2171.95 Safari/537.36
- Referrer: https://www.google.com/
- Accept-Encoding: gzip, deflate, sdch
- Accept-Language: en-US,en;q=0.8А вот заголовки, которые может отправлять типичный Python-скрапер, использующий стандартную библиотеку urllib:
- Accept-Encoding: identity
- User-Agent: Python-urllib/3.4Если вы администратор сайта, пытающийся блокировать скрапер, какой из этих запросов вы скорее пропустите?
К счастью, заголовки можно полностью настроить с помощью библиотеки Requests. Веб-сайт https://www.whatismybrowser.com отлично подходит для тестирования свойств браузера, видимых серверам. Вы можете скрапить этот сайт, чтобы проверить настройки ваших заголовков с помощью следующего скрипта:
import requests
from bs4 import BeautifulSoup
session = requests.Session()
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, как Gecko) Chrome',
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8'
}
url = 'https://www.whatismybrowser.com/developers/what-http-headers-is-my-browser-sending'
req = session.get(url, headers=headers)
bs = BeautifulSoup(req.text, 'html.parser')
print(bs.find('table', {'class': 'table-striped'}).get_text())Вывод должен показать, что заголовки теперь соответствуют тем, которые установлены в объекте словаря headers в коде.
Хотя сайты могут проверять «человечность» на основе любого из свойств в HTTP-заголовках, я обнаружил, что обычно единственная настройка, которая действительно имеет значение, — это User-Agent. Хорошей идеей будет всегда устанавливать этот заголовок на что-то менее подозрительное, чем Python-urllib/3.4, независимо от проекта, над которым вы работаете. Кроме того, если вы сталкиваетесь с чрезвычайно подозрительным сайтом, заполнение одного из часто используемых, но редко проверяемых заголовков, таких как Accept-Language, может помочь убедить сайт, что вы человек.
Заголовки могут изменить ваш взгляд на мир
Допустим, вы хотите написать переводчик на основе машинного обучения для исследовательского проекта, но у вас нет большого количества переведённого текста для тестирования. Многие крупные сайты предоставляют разные переводы одного и того же содержимого, в зависимости от указанных в заголовках предпочтений языка. Простое изменение `Accept-Language:en-US` на `Accept-Language:fr` в вашем заголовке может привести к тому, что сайты начнут отвечать вам «Bonjour», если это сайты крупных международных компаний, которые обычно имеют ресурсы и бюджет для поддержки перевода.
Заголовки также могут заставить веб-сайты изменить формат контента, который они предоставляют. Например, мобильные устройства часто видят упрощённые версии сайтов, без баннеров, Flash и других отвлекающих элементов. Если вы попробуете изменить ваш `User-Agent` на что-то вроде следующего, вы можете обнаружить, что сайты становятся проще для сбора данных (скрейпинга)!
User-Agent:Mozilla/5.0 (iPhone; CPU iPhone OS 7_1_2 like Mac OS X)
AppleWebKit/537.51.2 (KHTML, like Gecko) Version/7.0 Mobile/11D257
Safari/9537.53
Пояснения для новичков
1. Заголовки HTTP — это часть HTTP-запроса или ответа, которая содержит дополнительную информацию (метаданные) о запросе или ответе. Например, `Accept-Language` указывает предпочтительные языки контента.
2.
Accept-Language— заголовок, который используется для указания языков, которые предпочтительны для пользователя. Изменение этого значения может привести к тому, что сайт предложит контент на другом языке.3.
User-Agent— строка, которая помогает идентифицировать тип устройства, операционную систему и браузер, который делает запрос. Изменение этого значения может заставить сайт думать, что вы используете другой браузер или устройство (например, мобильное устройство вместо десктопа).4. Машинное обучение — это метод искусственного интеллекта, который позволяет программам учиться на данных и делать предсказания или принимать решения, не будучи явно запрограммированными на выполнение конкретной задачи.
5. Скрейпинг — это техника извлечения данных с веб-сайтов. Изменение
User-Agentможет помочь обойти некоторые ограничения сайтов, предназначенные для блокирования скрейпинга.
Работа с cookies в JavaScript
Правильное обращение с cookies может значительно облегчить веб-скрапинг, хотя куки могут быть палкой о двух концах. Веб-сайты, которые отслеживают ваши действия на сайте с помощью куки, могут попытаться заблокировать скраперы, демонстрирующие необычное поведение, например, слишком быстрое заполнение форм или посещение слишком большого количества страниц. Хотя такое поведение можно замаскировать, закрывая и снова открывая соединения с сайтом или даже меняя свой IP-адрес, если ваши куки выдают вашу личность, ваши усилия по маскировке могут оказаться тщетными.
Куки также могут быть необходимы для скрапинга сайта. Как показано в статье про формы и авторизацию, для того, чтобы оставаться в системе на сайте, необходимо иметь возможность хранить и предъявлять куки при переходе со страницы на страницу. Некоторым веб-сайтам даже не требуется, чтобы вы фактически входили в систему и получали новую версию куки каждый раз — достаточно просто хранить старую копию куки «в системе» и посещать сайт.
Если вы занимаетесь скрапингом одного целевого веб-сайта или небольшого количества целевых сайтов, я рекомендую изучить куки, генерируемые этими сайтами, и подумать, с какими из них вы хотели бы, чтобы ваш скрапер работал. Различные плагины для браузера могут показать вам, как устанавливаются куки, когда вы посещаете сайт и перемещаетесь по нему. EditThisCookie, расширение для Chrome, — одно из моих любимых.
Ознакомьтесь с примерами кода в разделе «Обработка логинов и куки» в статье про авторизацию и формы, чтобы получить дополнительную информацию об обработке куки с помощью библиотеки Requests. Конечно, поскольку библиотека Requests не может выполнять JavaScript, она не сможет обрабатывать многие куки, создаваемые современным программным обеспечением для отслеживания, таким как Google Analytics, которые устанавливаются только после выполнения сценариев на стороне клиента (или иногда на основе событий страницы, таких как щелчки кнопок, которые происходят во время просмотра страницы). Чтобы справиться с этим, вам нужно использовать пакеты Selenium и PhantomJS (мы рассмотрели их установку и базовое использование в статье скрапинга с JavaScript).
Вы можете просмотреть куки, посетив любой сайт (в этом примере http://pythonscraping.com) и вызвав get_cookies() в веб-драйвере:
from selenium import webdriver
driver = webdriver.PhantomJS(executable_path='<Путь к Phantom JS>')
driver.get('http://pythonscraping.com')
driver.implicitly_wait(1)
print(driver.get_cookies())В результате получается довольно типичный массив куки Google Analytics:
[{'value': '1', 'httponly': False, 'name': '_gat', 'path': '/', 'expi
ry': 1422806785, 'expires': 'Sun, 01 Feb 2015 16:06:25 GMT', 'secure'
: False, 'domain': '.pythonscraping.com'}, {'value': 'GA1.2.161952506
2.1422806186', 'httponly': False, 'name': '_ga', 'path': '/', 'expiry
': 1485878185, 'expires': 'Tue, 31 Jan 2017 15:56:25 GMT', 'secure':
False, 'domain': '.pythonscraping.com'}, {'value': '1', 'httponly': F
alse, 'name': 'has_js', 'path': '/', 'expiry': 1485878185, 'expires':
'Tue, 31 Jan 2017 15:56:25 GMT', 'secure': False, 'domain': 'pythons
craping.com'}]
Чтобы манипулировать куки, вы можете вызывать функции delete_cookie(), add_cookie() и delete_all_cookies(). Кроме того, вы можете сохранять и хранить куки для использования в других веб-скраперах. Вот пример, который даст вам представление о том, как эти функции работают вместе:
from selenium import webdriver
phantomPath = '<Путь к Phantom JS>'
driver = webdriver.PhantomJS(executable_path=phantomPath)
driver.get('http://pythonscraping.com')
driver.implicitly_wait(1)
savedCookies = driver.get_cookies()
print(savedCookies)
driver2 = webdriver.PhantomJS(executable_path=phantomPath)
driver2.get('http://pythonscraping.com')
driver2.delete_all_cookies()
for cookie in savedCookies:
if not cookie['domain'].startswith('.'):
cookie['domain'] = '.{}'.format(cookie['domain'])
driver2.add_cookie(cookie)
driver2.get('http://pythonscraping.com')
driver.implicitly_wait(1)
print(driver2.get_cookies())В этом примере первый веб-драйвер получает веб-сайт, печатает куки, а затем сохраняет их в переменной savedCookies. Второй веб-драйвер загружает тот же веб-сайт, удаляет свои собственные куки и добавляет куки из первого веб-драйвера.
Несколько технических замечаний
Второй веб-драйвер должен сначала загрузить веб-сайт, прежде чем будут добавлены куки. Это нужно для того, чтобы Selenium знал, к какому домену относятся куки, даже если сам факт загрузки веб-сайта не принесет никакой пользы для скрапера.
Перед загрузкой каждого куки выполняется проверка, начинается ли домен с символа точки (.). Это особенность PhantomJS — все домены в добавленных куки должны начинаться с точки (например, .pythonscraping.com), даже если не все куки в веб-драйвере PhantomJS фактически следуют этому правилу. Если вы используете другой драйвер браузера, например Chrome или Firefox, вам не нужно этого делать.
После этого у второго веб-драйвера должны быть те же куки, что и у первого. Согласно Google Analytics, этот второй веб-драйвер теперь идентичен первому, и они будут отслеживаться одинаково. Если первый веб-драйвер был авторизован на сайте, то и второй веб-драйвер тоже будет авторизован.
Время — это всё
Некоторые хорошо защищённые сайты могут предотвратить отправку форм или взаимодействие с сайтом, если вы делаете это слишком быстро. Даже если такие меры безопасности не используются, скачивание большого объёма информации с сайта значительно быстрее, чем это делал бы обычный человек, — это простой способ привлечь внимание и получить блокировку.
Поэтому, хотя многопоточное программирование может быть отличным способом для более быстрой загрузки страниц — позволяя вам обрабатывать данные в одном потоке и одновременно загружать страницы в другом — это ужасная стратегия для написания эффективных сборщиков данных (скраперов). Вам всегда следует стараться минимизировать количество загрузок страниц и запросов данных. Если возможно, попробуйте делать паузы между запросами хотя бы на несколько секунд, даже если для этого придется добавить:
import time
time.sleep(3)Необходимость этих дополнительных нескольких секунд между загрузками страниц часто определяется экспериментально. Не раз мне приходилось сталкиваться с трудностями при сборе данных с веб-сайтов, когда каждые несколько минут мне приходилось доказывать, что я «не робот» (решая CAPTCHA вручную, вставляя мои новые куки обратно в скрапер, чтобы сайт считал скрапер «доказавшим свою человечность»), но добавление `time.sleep` решило мои проблемы и позволило мне собирать данные бесконечно.
Иногда, чтобы ускориться, нужно замедлиться!
Распространённые меры безопасности форм
За годы использования было применено множество лакмусовых тестов, которые и по сей день используются с разной степенью успеха для различения веб-скраперов и людей, использующих браузеры.
Хотя загрузка некоторых статей и блог-постов ботами не является большой проблемой, если они и так были доступны публично, большая проблема возникает, когда бот создаёт тысячи пользовательских аккаунтов и начинает рассылать спам всем участникам сайта. Веб-формы, особенно формы, связанные с созданием аккаунтов и входом в систему, представляют собой значительную угрозу для безопасности и вычислительных ресурсов, если они уязвимы для бесконтрольного использования ботами. Поэтому многие владельцы сайтов считают (или, по крайней мере, так думают), что в их интересах пытаться ограничить доступ к сайту.
Эти антиботовские меры безопасности, сосредоточенные на формах и логинах, могут представлять значительную проблему для веб-скраперов.
Имейте в виду, что это лишь частичный обзор некоторых мер безопасности, с которыми вы можете столкнуться при создании автоматизированных ботов для этих форм.
Скрытые поля ввода в формах
«Скрытые» поля в HTML-формах позволяют сохранять значения, которые браузер может «видеть», но которые не видны пользователю (если только он не посмотрит исходный код сайта). С увеличением использования куки для хранения переменных и их передачи на сайтах, скрытые поля на время утратили популярность, прежде чем для них было найдено ещё одно отличное применение: предотвращение отправки форм скраперами.
На рисунке показан пример работы этих скрытых полей на странице входа в Яндекс. Хотя форма содержит всего три видимых поля (Имя пользователя, Пароль и кнопку Отправить), она передаёт серверу много информации, которая не видна напрямую.
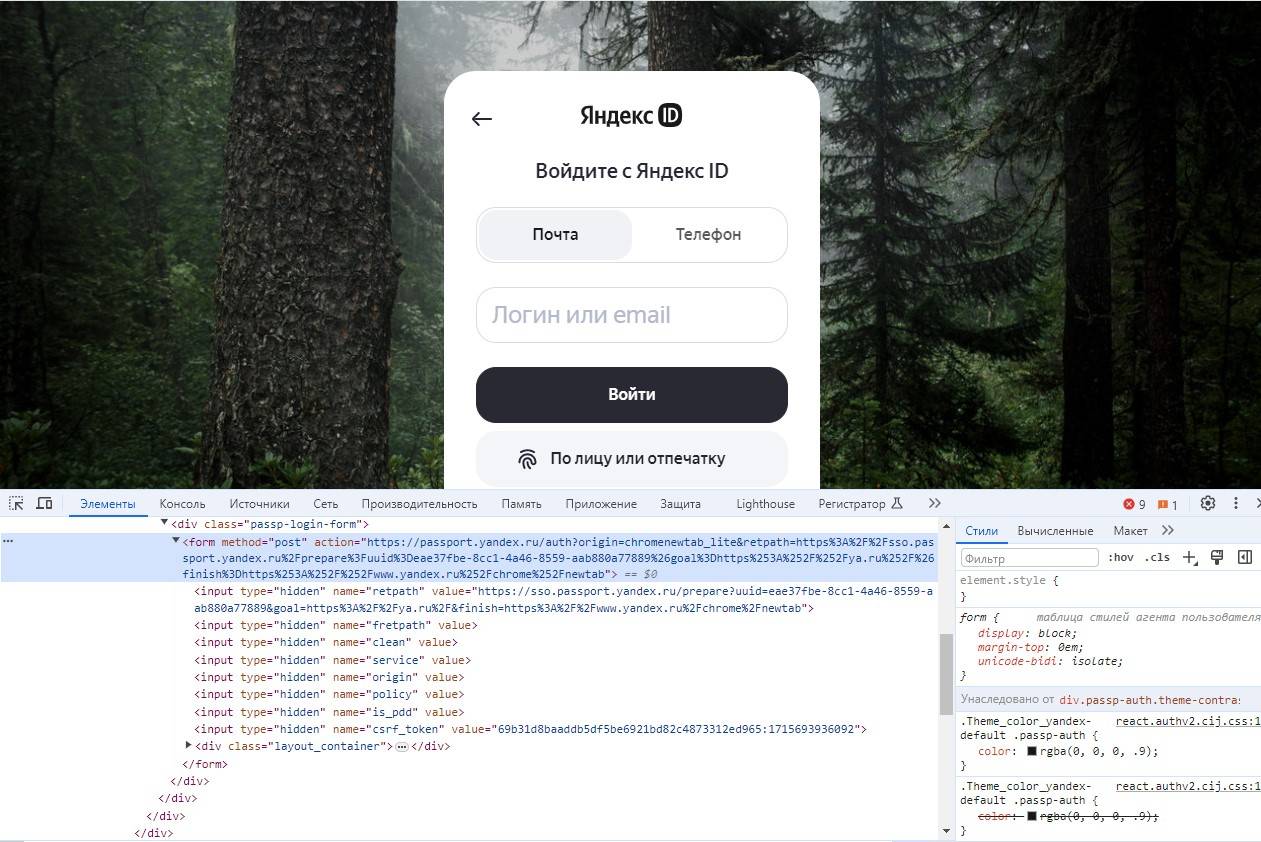
Скрытые поля используются для предотвращения веб-скрапинга двумя основными способами:
- Поле, заполненное случайно сгенерированной переменной: На странице с формой может быть поле, заполненное случайно сгенерированной переменной, которую сервер ожидает получить на странице обработки формы. Если этого значения нет в форме, сервер может с уверенностью предположить, что отправка не произошла органически со страницы с формой, а была выполнена ботом, напрямую обратившимся к странице обработки. Лучший способ обойти эту меру — сначала собрать данные со страницы с формой, получить случайно сгенерированную переменную, а затем отправить её на страницу обработки.
- Метод «медового горшка»: Если форма содержит скрытое поле с безобидным названием, например, Имя пользователя или Электронный адрес, плохо написанный бот может заполнить это поле и попытаться отправить его, несмотря на то, что оно скрыто для пользователя. Любые скрытые поля с реальными значениями (или значениями, отличными от их значений по умолчанию на странице отправки формы) следует игнорировать, и пользователь может даже быть заблокирован на сайте.
В заключение: Иногда необходимо проверить страницу с формой, чтобы увидеть, не упустили ли вы что-то, что сервер может ожидать. Если вы видите несколько скрытых полей, часто с большими случайно сгенерированными строковыми переменными, веб-сервер, вероятно, будет проверять их наличие при отправке формы. Кроме того, могут быть и другие проверки, чтобы убедиться, что переменные формы использовались только один раз, были сгенерированы недавно (что исключает возможность их сохранения в скрипте и многократного использования со временем) или оба эти условия выполнены.
Избегание ловушек «медового горшка»
Хотя CSS в большинстве случаев значительно упрощает процесс выделения полезной информации из ненужной (например, с помощью чтения тегов id и class), иногда он может создавать проблемы для веб-скраперов. Если поле веб-формы скрыто от пользователя с помощью CSS, можно разумно предположить, что обычный пользователь, посещающий сайт, не сможет его заполнить, так как оно не отображается в браузере. Если форма заполнена, скорее всего, это дело рук бота, и отправленные данные будут отброшены.
Это касается не только форм, но и ссылок, изображений, файлов и любых других элементов на сайте, которые бот может прочитать, но которые скрыты от обычного пользователя, посещающего сайт через браузер. Переход по «скрытой» ссылке на сайте может легко активировать серверный скрипт, который заблокирует IP-адрес пользователя, выведет его из системы или предпримет какие-то другие действия для предотвращения дальнейшего доступа. Фактически, многие бизнес-модели основаны именно на этой концепции.
Возьмем, к примеру, страницу, расположенную по адресу http://pythonscraping.com/pages/itsatrap.html. Эта страница содержит две ссылки, одна из которых скрыта с помощью CSS, а другая видима. Кроме того, на ней есть форма с двумя скрытыми полями:
<html>
<head>
<title>A bot-proof form</title>
</head>
<style>
body {
overflow-x:hidden;
}
.customHidden {
position:absolute;
right:50000px;
}
</style>
<body>
<h2>A bot-proof form</h2>
<a href="http://pythonscraping.com/dontgohere" style="display:none;">Go here!</a>
<a href="http://pythonscraping.com">Click me!</a>
<form>
<input type="hidden" name="phone" value="valueShouldNotBeModified"/><p/>
<input type="text" name="email" class="customHidden" value="intentionallyBlank"/><p/>
<input type="text" name="firstName"/><p/>
<input type="text" name="lastName"/><p/>
<input type="submit" value="Submit"/><p/>
</form>
</body>
</html>Эти три элемента скрыты от пользователя тремя способами:
- Первая ссылка скрыта с помощью атрибута CSS
display:none. - Поле
phoneявляется скрытым полем ввода. - Поле
emailскрыто путем его смещения на 50,000 пикселей вправо (предположительно за пределы экрана всех мониторов), и скрытие полосы прокрутки, которая могла бы это выдать.
К счастью, поскольку Selenium рендерит страницы, которые он посещает, он может различать элементы, которые визуально присутствуют на странице, и те, которых нет. Наличие элемента на странице можно определить с помощью функции is_displayed().
Например, следующий код получает ранее описанную страницу и ищет скрытые ссылки и поля ввода формы:
from selenium import webdriver
from selenium.webdriver.remote.webelement import WebElement
driver = webdriver.PhantomJS(executable_path='<Путь к Phantom JS>')
driver.get('http://pythonscraping.com/pages/itsatrap.html')
links = driver.find_elements_by_tag_name('a')
for link in links:
if not link.is_displayed():
print('Ссылка {} - это ловушка'.format(link.get_attribute('href')))
fields = driver.find_elements_by_tag_name('input')
for field in fields:
if not field.is_displayed():
print('Не изменяйте значение {}'.format(field.get_attribute('name')))
Selenium обнаруживает каждое скрытое поле, выводя следующий результат:
Ссылка http://pythonscraping.com/dontgohere - это ловушка
Не изменяйте значение phone
Не изменяйте значение email
Хотя вы, вероятно, не захотите переходить по скрытым ссылкам, которые найдете, вам все равно захочется убедиться, что вы отправляете любые предварительно заполненные скрытые значения формы (или заставить Selenium отправить их за вас) вместе с остальной формой. В итоге, опасно просто игнорировать скрытые поля, хотя нужно быть осторожным при взаимодействии с ними.
Чеклист для человека
В этой статье, а также в комплексе статей по скрапингу в целом, содержится много информации о том, как создать скрейпер, который выглядит менее как скрейпер и больше как человек. Если вы постоянно сталкиваетесь с блокировкой на веб-сайтах и не знаете, почему, вот чеклист, который вы можете использовать для решения проблемы:
- Проблема с пустыми или неполными страницами.
Если страница, которую вы получаете от веб-сервера, пуста, неполна или отличается от ожидаемой (или той, что вы видели в своем браузере), это скорее всего связано с выполнением JavaScript на сайте для генерации содержимого страницы. Обратитесь к статье по скрапингу с JavaScript для более подробной информации. - Проверка данных формы при отправке.
Если вы отправляете форму или делаете POST-запрос на веб-сайт, проверьте, что все данные, которые сайт ожидает от вас, действительно отправляются и в правильном формате. Используйте инструменты вроде панели Inspector в Chrome, чтобы просмотреть фактический POST-запрос, отправленный на сайт, и убедитесь, что ваш запрос выглядит так же, как «органический» запрос от обычного пользователя. - Проблемы с входом на сайт и сохранением состояния.
Если у вас возникают проблемы с входом на сайт или сайт демонстрирует странные проблемы с «состоянием» (например, сессия не сохраняется), проверьте свои cookies. Убедитесь, что cookies корректно сохраняются между загрузками страниц и что cookies отправляются на сайт с каждым запросом. - Обработка HTTP-ошибок, особенно 403 Forbidden.
Если вы получаете HTTP-ошибки, особенно ошибку 403 (Forbidden), это может указывать на то, что сайт определил ваш IP-адрес как бота и отказывается принимать запросы. Вам нужно будет подождать, пока ваш IP-адрес не будет удален из списка, или получить новый IP-адрес (например, перейти в другое место с новым IP, как в кафе). Чтобы избежать повторной блокировки, попробуйте следующее:- Управление скоростью скрапинга
Убедитесь, что ваши скраперы не перемещаются по сайту слишком быстро. Быстрый скрапинг нагружает серверы и может привести к юридическим проблемам и блокировке. Добавьте задержки в работу скраперов и позвольте им работать ночью. Помните: спешка в сборе данных — признак плохого управления проектами; планируйте заранее, чтобы избежать проблем. - Изменение заголовков HTTP
Измените свои HTTP-заголовки! Некоторые сайты блокируют все, что объявляет себя скрапером. Скопируйте заголовки вашего собственного браузера, если не уверены в подходящих значениях. - Избегание подозрительных действий
Убедитесь, что вы не кликаете и не обращаетесь к чему-то, что обычный человек не смог бы (смотрите раздел «Избегание ловушек» на странице 223 для дополнительной информации). - Связаться с админом.
Если вы сталкиваетесь с множеством трудных препятствий для получения доступа, подумайте о том, чтобы связаться с администратором сайта, чтобы сообщить ему, что вы делаете. Попробуйте отправить электронное письмо на webmaster@<имя домена> или admin@<имя домена> с запросом на разрешение использовать ваши скрейперы. Администраторы тоже люди, и вы можете удивиться, насколько они готовы делиться своими данными.
- Управление скоростью скрапинга
Индивидуальное и групповое обучение «Аналитик данных»
Если вы хотите стать экспертом в аналитике, могу помочь. Запишитесь на мой курс «Аналитик данных» и начните свой путь в мир ИТ уже сегодня!
Контакты
Для получения дополнительной информации и записи на курсы свяжитесь со мной:
Телеграм: https://t.me/Vvkomlev
Email: victor.komlev@mail.ru
Объясняю сложное простыми словами. Даже если вы никогда не работали с ИТ и далеки от программирования, теперь у вас точно все получится! Проверено десятками примеров моих учеников.
Гибкий график обучения. Я предлагаю занятия в мини-группах и индивидуально, что позволяет каждому заниматься в удобном темпе. Вы можете совмещать обучение с работой или учебой.
Практическая направленность. 80%: практики, 20% теории. У меня множество авторских заданий, которые фокусируются на практике. Вы не просто изучаете теорию, а сразу применяете знания в реальных проектах и задачах.
Разнообразие учебных материалов: Теория представлена в виде текстовых уроков с примерами и видео, что делает обучение максимально эффективным и удобным.
Понимаю, что обучение информационным технологиям может быть сложным, особенно для новичков. Моя цель – сделать этот процесс максимально простым и увлекательным. У меня персонализированный подход к каждому ученику. Максимальный фокус внимания на ваши потребности и уровень подготовки.