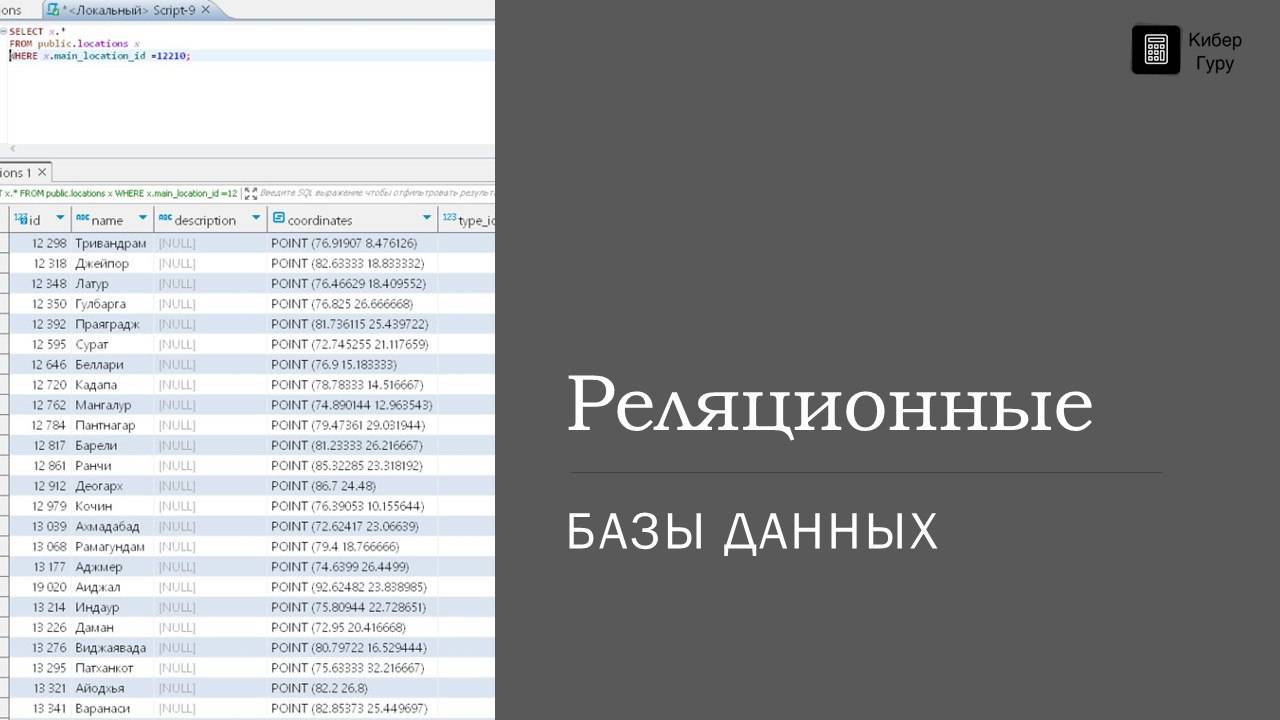
Реляционные базы данных — это способ организации и хранения информации в компьютерных системах. Они основаны на концепции таблиц, где данные разделены на строки и столбцы, подобно клеткам в тетради. Каждая строка представляет собой отдельную запись, а каждый столбец — определенное свойство или атрибут записи.
Реляционные базы данных позволяют нам эффективно организовывать, хранить и извлекать информацию, используя структурированные запросы на языке SQL (Structured Query Language). Это очень важный инструмент для работы с данными, который используется во многих сферах нашей жизни, от банковского дела до социальных сетей.
Давайте совершим небольшой временной переход и представим, что вы путешествуете в прошлое, когда хранение данных было похоже на бескрайний лабиринт, полный бумажных документов и магии «где же моя запись?».

Теперь представьте себе решение, способное превратить этот хаос в организованный мир, где каждая информация имеет свое место и легко находится. В этой магической стране реляционных баз данных, данные стали податливыми, как глина в руках скульптора. Здесь вся информация взаимосвязана, создавая простор для умного анализа и выявления тайн, которые раньше скрывались в темных уголках ваших данных.

История развития баз данных
Плоские файлы и Картотеки (с начала появления компьютеров до 1960-х)
В начале истории компьютеров, данные хранились в плоских файлах или картотеках.
Плоский файл представляет собой простой текстовый файл, где данные хранятся линейно, без какой-либо структуры или организации. Каждая строка содержит запись, а значения разделяются определенным символом (например, пробелом или запятой).
В чем плюсы
- Простота Записи: Запись данных в плоский файл — это простая операция. Просто добавьте новую строку с данными.
- Простота Чтения: Данные можно прочитать последовательно, используя стандартные инструменты для чтения файлов.
- Плоские файлы могут быть легко созданы и изменены с помощью стандартных текстовых редакторов или программ обработки данных
Минусы
Ограниченная Структура:
- Пример: Представьте, что у вас есть файл с информацией о продуктах в магазине. Каждая строка содержит информацию о продукте, но нет четкой структуры, определяющей, где находится имя продукта, а где — его цена.
Отсутствие Связей:
- Пример: В плоском файле с информацией о заказах нет явных связей между заказами и клиентами. Таким образом, для поиска заказов конкретного клиента необходимо просматривать весь файл.
Сложности с Обновлением:
- Пример: Если вам нужно внести изменения в информацию о продукте, это может потребовать изменения в нескольких местах файла. Ошибки при обновлении могут привести к потере или искажению данных.
Затрудненный Поиск:
- Пример: Попробуйте найти все заказы, сделанные в определенный период времени, в текстовом файле. Это требует тщательного просмотра каждой строки, что неэффективно и затруднительно.
Совместный доступ:
- Проблема: В среде, где плоские файлы используются для хранения данных, совместный доступ может быть проблематичным. Если несколько пользователей пытаются одновременно изменять файл, это может привести к потере данных или конфликтам.
- Пример: Представим, что несколько сотрудников одновременно пытаются редактировать файл с информацией о продуктах в магазине. В результате возникают конфликты изменений, и становится трудно определить, какая версия файла является актуальной.
Разграничение доступа:
- Проблема: Плоские файлы обычно не предоставляют средств для эффективного разграничения доступа к информации. Это может привести к тому, что сотрудники имеют доступ ко всем данным, даже если им необходим доступ только к определенной части.
- Пример: В организации с одним плоским файлом данных о сотрудниках, каждый сотрудник имеет доступ к полной базе данных, включая личные данные коллег. Отсутствие механизма разграничения доступа может нарушить приватность и безопасность данных.
Иерархические и сетевые системы (1960-е — 1970-е)
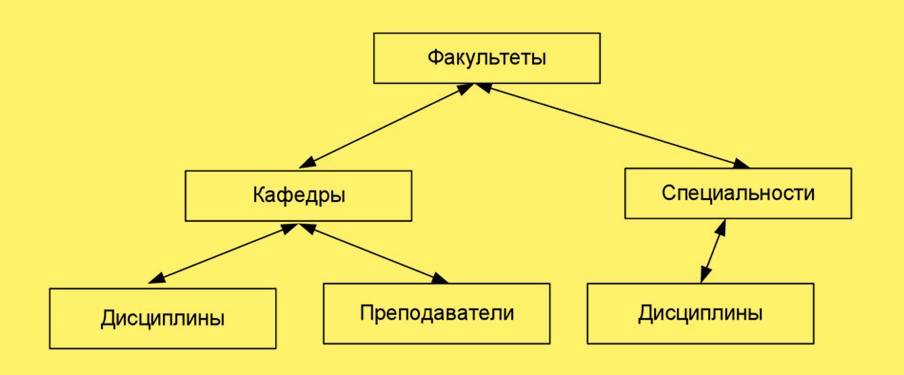
- Иерархические Базы Данных:
- Определение: Иерархическая база данных представляет собой структуру, в которой данные организованы в виде древовидной иерархии. Вершины дерева представляют собой «родительские» записи, а ветви и листья — их «дочерние» записи.
- Особенности:
- Записи организованы в структуру древовидного графа.
- Каждая запись может иметь одного родителя, но несколько детей.
- Пример: Система учета сотрудников в организации, где у каждого руководителя есть подчиненные.
- Сетевые Базы Данных:
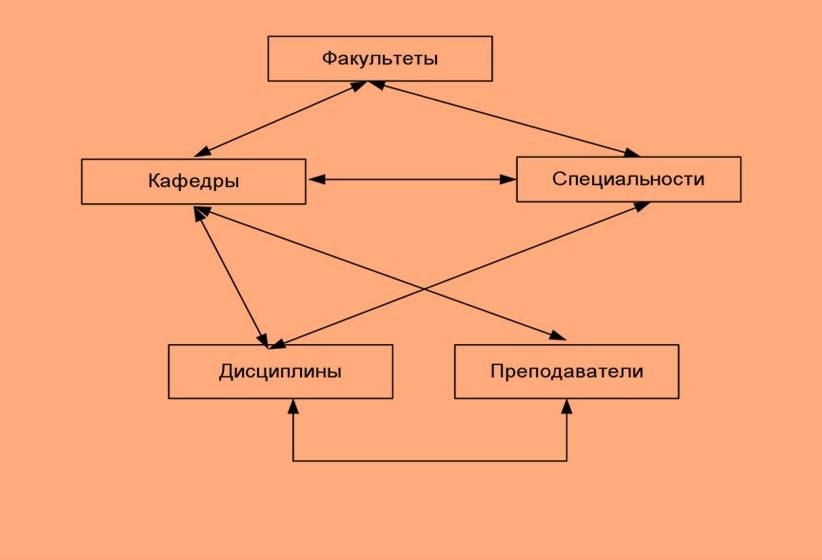
- Определение: Сетевая база данных расширяет идею иерархической модели, позволяя записям иметь несколько «родителей», создавая более сложные взаимосвязи и структуры.
- Особенности:
- Записи могут иметь несколько «родителей» и «детей».
- Взаимосвязи представляются в виде сети, а не древовидной иерархии.
- Пример: Система учета заказов в магазине, где товар может быть связан с несколькими заказами и категориями.
Достоинства и недостатки иерархических и сетевых баз данных:
Достоинства:
- Быстрый доступ к данным:
- В случае жесткой структуры иерархии быстро можно найти нужные данные.
- Эффективность для определенных сценариев:
- Подходят для сценариев, где данные естественным образом организованы в виде древовидной или сетевой структуры.
Недостатки:
- Жесткая структура:
- Неудобство при изменении структуры данных и добавлении новых типов записей.
- Ограниченность в возможностях запросов:
- Запросы могут быть сложными и ограниченными в сравнении с реляционными БД.
- Сложности при масштабировании:
- Сложности в масштабировании и адаптации к изменяющимся требованиям.
Эволюция к реляционным базам данных:
- Гибкость реляционных моделей:
- Реляционные базы данных предлагают более гибкую модель данных, где информация хранится в виде таблиц с явными связями между записями.
- Большая простота запросов:
- SQL запросы в реляционных базах данных обеспечивают легкий и мощный способ извлечения данных, что делает их более привлекательными для разработчиков.
- Удобство обновления и расширения:
- Возможность легко обновлять, добавлять и изменять данные без необходимости изменения всей структуры.
Итак, хотя иерархические и сетевые базы данных имели свои преимущества, реляционные базы данных предложили более гибкую и простую модель данных, что сделало их более предпочтительными для широкого спектра приложений и сценариев.
Примеры реализаций сетевых и иерархических коммерческих СУБД
- Иерархические базы данных:
- IMS (Information Management System): Разработана компанией IBM. Использовалась для хранения и управления данными в банковских системах, системах учета, а также для сбора и анализа информации.
- XML-базы данных: Хотя XML (eXtensible Markup Language) не является чисто иерархической моделью, многие приложения используют XML для представления данных в иерархической форме. Например, базы данных, использующие XML-ориентированные языки запросов, такие как XQuery.
- Сетевые базы данных:
- IDMS (Integrated Database Management System): Разработана Cullinane Database Systems (затем подразделение компании CA Technologies). Использовалась в приложениях для управления данными в банковской сфере, страховании, здравоохранении и т. д.
- CODASYL DBTG (Conference on Data Systems Languages Database Task Group): Сетевая модель данных, разработанная в рамках CODASYL, была широко использована в различных приложениях, включая библиотечные системы и системы управления предприятием.
- Эволюция к реляционным Базам Данных:
- IBM DB2: Начав с использования сетевой модели в IMS, IBM позднее перешла к реляционной модели с появлением системы управления базами данных DB2, ставшей одной из наиболее широко используемых реляционных СУБД.
- Oracle Database: Исходно создана как система управления базами данных на основе сетевой модели (Oracle Version 2). С появлением Oracle Database 7, Oracle стала предоставлять реляционную модель, которая сейчас является одной из самых распространенных реляционных СУБД.
Появление реляционных систем (1970-е)
Реляционная модель данных:
- Эдгар Кодд: В начале 1970-х годов, Эдгар Кодд, работник IBM, представил реляционную модель данных в своей работе «A Relational Model of Data for Large Shared Data Banks». Это стало переломным моментом в истории баз данных.
- Основные идеи:
- Данные представляются в виде таблиц (отношений).
- В таблицах используются строки (кортежи) и столбцы (атрибуты).
- Взаимосвязи между таблицами строятся на основе ключей.
- Реляционная алгебра и реляционный язык запросов (SQL) использовались для запросов и управления данными.
2. Таблицы, строки и столбцы:
- Таблицы (Отношения): Основная структура данных в реляционной модели. Представляют собой двумерные матрицы, где каждая строка — запись, а каждый столбец — атрибут (поле).
- Строки (Кортежи): Каждая строка в таблице представляет собой набор данных, соответствующих конкретной записи.
- Столбцы (Атрибуты): Каждый столбец содержит данные одного типа, представляя собой конкретный аспект информации.
3. Преимущества реляционных баз данных:
- Простота:
- Простота структуры таблиц и их взаимосвязей делает реляционные базы данных легкими для понимания и использования.
- Удобство запросов:
- Использование SQL позволяет легко формулировать запросы для получения нужной информации.
- Структурированность:
- Данные структурированы и организованы, что упрощает управление и обработку.
- Гибкость:
- Возможность добавления, изменения и удаления данных без необходимости изменения всей структуры базы данных.
- Независимость данных и приложений:
- Данные могут изменяться, а приложения, использующие эти данные, остаются независимыми от изменений в базе данных.
- Многопользовательская поддержка:
- Возможность одновременного доступа нескольких пользователей к базе данных.
4. Практические примеры:
- IBM System R: Первая коммерческая реализация реляционной базы данных, разработанная в IBM в конце 1970-х.
- Oracle RDBMS: Первая версия Oracle Database, выпущенная в 1979 году, использовала реляционную модель данных.
- Microsoft SQL Server: Система управления базами данных, разработанная Microsoft, выпущена в конце 1980-х и основана на реляционной модели.
Реляционные базы данных оказались эффективными, гибкими и простыми в использовании, что привело к широкому распространению этой технологии и стала основой для многих современных систем управления базами данных.
Реляционная алгебра
Реляционная алгебра — это математическая система, предложенная Эдгаром Коддом в 1970 году, для описания и манипулирования реляционными данными в реляционных базах данных. Реляционная алгебра представляет собой набор операций, аналогичных операциям в математике, которые позволяют выполнять различные операции с данными в таблицах.
В реляционной алгебре используются следующие основные операции:
- Выбор (Selection):
- Обозначается символом σ (сигма).
- Используется для выбора строк из таблицы, удовлетворяющих определенному условию.
Пример:
- Проекция (Projection):
- Обозначается символом π (пи).
- Используется для выбора определенных столбцов из таблицы.
Пример:
- Объединение (Union):
- Обозначается символом ∪.
- Объединяет две таблицы, удаляя при этом дубликаты.
Пример:
- Пересечение (Intersection):
- Обозначается символом ∩.
- Возвращает только те строки, которые присутствуют в обеих таблицах.
Пример:
- Разность (Difference):
- Обозначается символом -.
- Возвращает все строки из первой таблицы, которые не присутствуют во второй таблице.
Пример:
- Произведение (Cartesian Product):
- Обозначается символом ×.
- Возвращает все возможные комбинации строк из двух таблиц.
Пример:
Реляционная алгебра обеспечивает формальный способ описания запросов к данным в реляционных базах данных. Операции этой алгебры часто используются в языке SQL (Structured Query Language), который является стандартным языком запросов к реляционным базам данных.
Реализация решения задачи в различных моделях данных
Рассмотрим пример магазина: информация о продуктах, клиентах, и заказах. Нужно узнать, какие товары покупают чаще всего определенные клиенты.
- Плоские файлы:
- Структура данных: Одним текстовым файлом, где каждая строка представляет собой запись о продукте, клиенте или заказе, разделенные определенным символом.
- Решение задачи:
- Неэффективный способ выполнения запроса. Необходимо сканировать весь файл для поиска данных о продуктах, клиентах и заказах.
- Процесс: Чтение файла, разделение данных, поиск по клиентам, анализ заказов.
- Иерархическая модель:
- Структура данных: Иерархия с уровнями продуктов, клиентов и заказов, где каждый уровень содержит связанные записи.
- Решение задачи:
- Неудобный для запросов. Необходимо следовать структуре иерархии, переходя от продуктов к заказам через клиентов.
- Процесс: Навигация по дереву, поиск соответствующих клиентов, анализ заказов.
- Неудобный для запросов. Необходимо следовать структуре иерархии, переходя от продуктов к заказам через клиентов.
- Сетевая модель:
- Структура данных: Записи о продуктах, клиентах и заказах связаны друг с другом в виде сети, позволяя более сложные взаимосвязи.
- Решение задачи:
- Хотя сетевая модель поддерживает более сложные связи, отсутствие возможности создания запросов реляционной алгебры на языке SQL могут потребовать более сложных структур, чтобы найти нужные данные.
- Процесс:
- Проекция:
- Извлечение данных о клиентах и продуктах.
Пример:
- Соединение (Join):
- Получение информации о продуктах в заказе.
Пример:
- Выбор:
- Нахождение заказов, сделанных определенным клиентом.
Пример:
- Проекция:
- Реляционная модель:
- Структура данных: Три таблицы — «Продукты», «Клиенты» и «Заказы», связанные ключами (например, ID продукта, ID клиента).
- Решение задачи:
- Эффективный для запросов. Простой SQL запрос с использованием операции JOIN может найти необходимую информацию.
SELECT products.name FROM orders JOIN customers ON orders.customer_id = customers.id WHERE customers.name = 'имя_клиента'" - Процесс: Выполнение SQL запроса, объединение таблиц, фильтрация результатов.
- Эффективный для запросов. Простой SQL запрос с использованием операции JOIN может найти необходимую информацию.
- Структура данных: Записи о продуктах, клиентах и заказах связаны друг с другом в виде сети, позволяя более сложные взаимосвязи.
Эволюция реляционной модели
- Стандарт SQL (1986):
- Что: В 1986 году был принят стандарт SQL (Structured Query Language) как язык запросов к реляционным базам данных. SQL стал стандартом, что обеспечило единый и универсальный способ взаимодействия с реляционными СУБД.
- Преимущества:
- Универсальность: SQL стал универсальным языком запросов, что упростило взаимодействие с различными СУБД.
- Стандартизация: Стандарт SQL способствовал переносимости кода между разными реляционными базами данных.
- SQL-92 (1992):
- Что: Обновление стандарта SQL, известное как SQL-92, было введено в 1992 году. Оно внесло ряд улучшений и расширений в язык.
- Преимущества:
- Дополнительные возможности: Введение новых возможностей, таких как поддержка внешних ключей, обновления данных через представления и другие.
- Появление реляционных СУБД. Еще одним важным нововведением было внедрение хранилищ данных и систем управления базами данных (СУБД). Хранилища данных предоставляют централизованное место для хранения и управления большими объемами данных. СУБД обеспечивают удобный интерфейс для работы с данными и поддерживают различные функции, такие как транзакции, контроль целостности данных и журналирование.
- Объектно-реляционные СУБД (1990-е):
- Что: В конце 1980-х и более активно в 1990-е годы начали развиваться объектно-реляционные СУБД, которые комбинировали преимущества реляционной модели с объектно-ориентированным программированием.
- Преимущества:
- Управление Объектами: Способность хранить и управлять объектами программного кода, что особенно полезно для современных приложений.
- Оптимизация запросов (1980-1990):
- Что: Развитие технологий оптимизации запросов, включая появление индексов, статистических методов, планов выполнения запросов.
- Преимущества:
- Повышение эффективности: Оптимизация запросов сделала выполнение запросов более эффективным и быстрым.
- Параллельная обработка и кластеры БД (1980-1990):
- Что: Внедрение технологий параллельной обработки данных и кластеров баз данных.
- Преимущества:
- Ускорение обработки: Использование параллельных вычислений и кластеров для более быстрой обработки больших объемов данных.
- Стандарты ACID (Atomicity, Consistency, Isolation, Durability):
- Что: Стандарты ACID, определенные для обеспечения надежности и целостности транзакций в реляционных базах данных.
- Преимущества:
- Надежность транзакций: Обеспечение надежности при выполнении транзакций, что важно для бизнес-приложений.
- Объектно-реляционные СУБД (1990-2000):
- Что: Развитие и распространение объектно-реляционных СУБД (ORDBMS), таких как Oracle 8, Informix Universal Server, Microsoft SQL Server.
- Преимущества:
- Управление объектами: Более эффективное управление объектами и связями между ними.
- Совмещение ООП и реляционной модели: Объединение преимуществ объектно-ориентированного программирования и реляционной модели данных.
- Развитие языка SQL (1990-2000):
- Что: Расширение функциональности SQL и появление новых возможностей, таких как хранимые процедуры, триггеры, представления.
- Преимущества:
- Больше возможностей: Расширение языка SQL позволило программистам более эффективно работать с базами данных, включая создание сложных бизнес-логик и обработку данных.
- Системы управления большими данными (Big Data) (1990-2000):
- Что: Начало работы с системами, способными обрабатывать и хранить огромные объемы данных, такие как Apache Hadoop.
- Преимущества:
- Обработка огромных объемов данных: Возможность обработки данных, не поддающихся традиционным реляционным базам данных.
- Горизонтальное масштабирование: Возможность горизонтального масштабирования для обработки больших объемов данных.
- Распределенные реляционные базы данных (1990-2000):
- Что: Развитие технологий для работы с распределенными базами данных, такими как Oracle Parallel Server.
- Преимущества:
- Высокая доступность: Обеспечение высокой доступности данных за счет их распределения по разным узлам.
- Балансировка нагрузки: Распределение нагрузки между узлами для повышения производительности.
- XML-ориентированные решения (1990-2000):
- Что: Распространение XML как формата для обмена данными и появление баз данных, специально ориентированных на работу с XML (например, XML-базы данных).
- Преимущества:
- Удобство обмена данными: Использование универсального формата (XML) для обмена и хранения данных.
- Поддержка иерархических данных: XML-базы данных обеспечивают поддержку иерархических структур данных.
- Интернет и развитие веб-базированных баз данных (1990-2000):
- Что: Расширение роли баз данных в веб-приложениях, развитие технологий веб-базированных СУБД (например, MySQL, PostgreSQL).
- Преимущества:
- Динамичные веб-приложения: Возможность создания динамичных и интерактивных веб-приложений с использованием баз данных.
- Широкое распространение: Веб-базированные СУБД стали широко распространенными и доступными.
- Стандарт SQL-99 (1999):
- Что: Обновление стандарта SQL, известное как SQL-99, внесло ряд улучшений в структуру языка и функциональность.
- Преимущества:
- Дополнительные возможности: Введение новых возможностей, таких как оконные функции, расширенная поддержка типов данных.
- Новые методы оптимизации производительности
- Что: индексирование полнотекстовых запросов и аналитические запросы.
- Преимущества:
- Индексирование полнотекстовых запросов позволяет эффективно выполнять запросы, содержащие ключевые слова или фразы. Аналитические запросы позволяют выполнять сложные аналитические операции, такие как агрегация и группировка данных, что особенно полезно для бизнес-аналитики и отчетности.
- Облачные базы данных (2000-2010):
- Что: Развитие технологий облачных вычислений привело к появлению облачных баз данных, таких как Amazon RDS, Google Cloud SQL.
- Преимущества:
- Масштабируемость: Легкость масштабирования баз данных в облаке в зависимости от потребностей.
- Доступность и управление: Высокая доступность и управление обслуживанием данных.
- NoSQL движки баз данных (2000-2010):
- Что: Появление NoSQL-баз данных (MongoDB, Cassandra, CouchDB) для обработки и хранения данных, которые не подходят под схему реляционных баз.
- Преимущества:
- Гибкость схемы: Возможность работы с неструктурированными и полуструктурированными данными.
- Масштабируемость: Хорошая масштабируемость для больших объемов данных.
- Inmemory базы данных (2000-2010):
- Что: Ин-Memory технологии (SAP HANA, Oracle TimesTen) для хранения данных в оперативной памяти компьютера.
- Преимущества:
- Быстродействие: Оперативный доступ к данным в памяти, что ускоряет выполнение запросов.
- Аналитика в реальном времени: Возможность проведения аналитики в режиме реального времени.
- Широкие возможности хранилища данных (2000-2010):
- Что: Возникновение широких возможностей хранилищ данных (Data Warehousing), таких как Amazon Redshift, Google BigQuery.
- Преимущества:
- Аналитика больших данных: Поддержка хранения и анализа больших объемов данных.
- Сквозной анализ: Способность проведения сквозного анализа данных из различных источников.
- Базы данных с поддержкой графов (2000-2010):
- Что: Появление баз данных, специально предназначенных для работы с графами (Neo4j, Amazon Neptune).
- Преимущества:
- Обработка графовых структур: Эффективная обработка и анализ данных с графовой структурой.
- Сетевая Навигация: Поддержка запросов, связанных с графовой навигацией.
- Развитие бизнес-интеллекта (BI) (2000-2010):
- Что: Интеграция баз данных с инструментами бизнес-аналитики (Tableau, Power BI).
- Преимущества:
- Улучшенные инструменты анализа: Интеграция с современными инструментами для бизнес-аналитики и визуализации.
- Расширенные возможности отчетности: Больше возможностей создания отчетов и анализа данных.
- Улучшенная оптимизация запросов (2000-2010):
- Что: Развитие алгоритмов оптимизации запросов и планов выполнения запросов. Индексирование геоданных
- Преимущества:
- Эффективность запросов: Улучшенная эффективность выполнения запросов за счет оптимизации.
- Автоматическая оптимизация: Развитие методов автоматической оптимизации запросов.
- Индексирование геоданных позволяет эффективно выполнять запросы, связанные с географическими данными, такими как местоположение или координаты.
- Стандарт SQL:2003 (2003):
- Что: Обновление стандарта SQL, известное как SQL:2003, внесло новые возможности и уточнения в язык SQL.
- Преимущества:
- Богатство возможностей: Введение новых конструкций и расширение возможностей для работы с данными.
- БД с открытым исходным кодом.
- Преимущества.
- Базы данных с открытым исходным кодом предоставляют доступ к исходному коду программы, что позволяет пользователям вносить изменения и модифицировать базу данных под свои потребности. Это обеспечивает большую гибкость и контроль над системой управления данными.
- Преимущества.
- Новые СУБД и расширенные возможности существующих (2010-настоящее время):
- Что: Появление новых СУБД и расширение функциональности существующих (PostgreSQL, MySQL, Microsoft SQL Server, Oracle).
- Преимущества:
- Расширенные возможности: Внедрение новых возможностей, таких как поддержка JSON, улучшенные инструменты аналитики, повышенная производительность.
- Технологии искусственного интеллекта (ИИ) и машинного обучения (МО) (2010-настоящее время):
- Что: Интеграция технологий искусственного интеллекта и машинного обучения в базы данных.
- Преимущества:
- Анализ больших данных: Использование ИИ и МО для анализа больших объемов данных и выявления паттернов.
- Персонализированные решения: Создание персонализированных решений на основе данных и обучения моделей.
- Расширенная поддержка геоданных (2010-настоящее время):
- Что: Улучшенная поддержка геоданных в реляционных базах данных.
- Преимущества:
- Геоаналитика: Возможность проведения геоаналитики и обработки геоданных.
- Разнообразные приложения: Использование в различных приложениях, связанных с геолокацией.
- Развитие облачных технологий и сервисов (2010-настоящее время):
- Что: Постоянное развитие облачных технологий и появление новых облачных сервисов для хранения и обработки данных.
- Преимущества:
- Гибкость и масштабируемость: Возможность быстрого масштабирования и использования вычислительных ресурсов по мере необходимости.
- Высокая доступность: Обеспечение высокой доступности данных в облаке.
- Большие данные и системы обработки стримов (2010-настоящее время):
- Что: Развитие технологий обработки больших данных и стримов (Apache Kafka, Apache Flink).
- Преимущества:
- Обработка реального времени: Возможность обработки и анализа данных в режиме реального времени.
- Способность работы с большими объемами данных: Обработка и хранение больших объемов данных.
- Интеграция с различными типами данных (2010-настоящее время):
- Что: Усиление интеграции с различными типами данных, включая неструктурированные данные и медиа-ресурсы.
- Преимущества:
- Универсальная обработка данных: Обработка данных различных типов в рамках единой платформы.
- Богатые возможности хранения и поиска: Хранение и поиск данных различных форматов.
- Автоматизированный мониторинг и оптимизация (2010-настоящее время):
- Что: Использование автоматизированных средств мониторинга и оптимизации производительности баз данных.
- Преимущества:
- Эффективное управление ресурсами: Автоматическое управление ресурсами и оптимизация запросов для повышения производительности.
- Снижение риска ошибок: Снижение риска человеческих ошибок при настройке баз данных.
Выбор базы данных для своих потребностей
- Реляционные СУБД (RDBMS):
- Популярные решения:
- PostgreSQL:
- Преимущества: Мощная, открытая система с широкими возможностями и активным сообществом.
- Применение: Подходит для различных проектов, от небольших веб-приложений до больших корпоративных систем.
- MySQL:
- Преимущества: Легковесная, быстрая и простая в использовании, широко распространена.
- Применение: Используется в веб-приложениях, CMS, корпоративных системах.
- Oracle Database:
- Преимущества: Высокая производительность, широкие возможности, поддержка крупных корпоративных систем.
- Применение: Крупные предприятия, банки, телекоммуникации.
- Microsoft SQL Server:
- Преимущества: Интеграция с другими продуктами Microsoft, удобство в использовании.
- Применение: Корпоративные приложения, системы бизнес-аналитики.
- PostgreSQL:
- Характеристики:
- Структурированные данные в виде таблиц с отношениями между ними.
- SQL как язык запросов.
- ACID-совместимость.
- Подходит для:
- Бизнес-приложений с жесткой схемой данных.
- Транзакционных систем, где важна надежность и целостность данных.
- Аналитических систем, где требуется выполнение сложных запросов.
- Не подходит для:
- Проектов с большим объемом неструктурированных данных.
- Высоконагруженных систем, где важна максимальная производительность.
- Популярные решения:
- NoSQL СУБД:
- Популярные решения:
- MongoDB:
- Преимущества: Гибкая схема данных, хорошая масштабируемость, поддержка JSON.
- Применение: Веб-приложения, аналитика, проекты с изменяющейся схемой данных.
- Cassandra:
- Преимущества: Высокая производительность при больших объемах данных, горизонтальное масштабирование.
- Применение: Распределенные системы, IoT, аналитика.
- Redis:
- Преимущества: Высокая производительность в оперативной памяти, поддержка различных структур данных.
- Применение: Кэширование, сессионное хранение данных, очереди сообщений.
- CouchDB:
- Преимущества: Гибкая структура документов, мастер-мастер репликация.
- Применение: Мобильные приложения, веб-проекты, синхронизация данных.
- MongoDB:
- Характеристики:
- Гибкая схема данных или отсутствие фиксированной схемы.
- Различные модели данных: документы, ключ-значение, столбцовые, графы.
- Ориентированы на горизонтальное масштабирование.
- Подходит для:
- Проектов с большим объемом неструктурированных данных.
- Высоконагруженных систем, требующих гибкости схемы данных.
- Проектов, где важна гибкость в выборе модели данных.
- Не подходит для:
- Транзакционных систем, где требуется ACID-совместимость.
- Проектов, где важна строгая схема данных.
- Популярные решения:
- In-Memory СУБД:
- Популярные решения:
- SAP HANA:
- Преимущества: Обработка данных в оперативной памяти, высокая производительность, аналитика в реальном времени.
- Применение: Аналитика, корпоративные приложения.
- MemSQL:
- Преимущества: Ин-Memory обработка данных, горизонтальное масштабирование.
- Применение: Реальное время аналитика, обработка транзакций.
- VoltDB:
- Преимущества: Высокая производительность, ACID-совместимость, обработка данных в режиме реального времени.
- Применение: Финансовые услуги, телекоммуникации, аналитика.
- SAP HANA:
- Характеристики:
- Хранение данных в оперативной памяти для быстрого доступа.
- Оптимизированы для аналитики и обработки больших объемов данных.
- Подходит для:
- Систем, требующих максимальной производительности и оперативного доступа к данным.
- Аналитических приложений в режиме реального времени.
- Не подходит для:
- Проектов с ограниченными ресурсами оперативной памяти.
- Транзакционных систем, где требуется постоянное сохранение данных на долгосрочный срок.
- Популярные решения:
- Графовые Базы Данных:
- Популярные решения:
- Neo4j:
- Преимущества: Эффективная обработка графовых структур, дружественный язык запросов.
- Применение: Социальные сети, рекомендательные системы.
- Amazon Neptune:
- Преимущества: Управление связями в данных, поддержка графовых и RDF данных.
- Применение: Рекомендательные системы, анализ социальных связей.
- ArangoDB:
- Преимущества: Многомодельная, гибкость модели данных.
- Применение: Веб-проекты, геоаналитика.
- Neo4j:
- Характеристики:
- Оптимизированы для хранения и обработки графовых структур данных.
- Концентрируются на отношениях и связях между данными.
- Подходит для:
- Социальных сетей и анализа связей между сущностями.
- Проектов, где важна навигация по сложным графовым структурам.
- Не подходит для:
- Проектов с преимущественно табличной структурой данных.
- Проектов, где нет выраженной графовой структуры.
- Популярные решения:
- Базы данных с Поддержкой Геоданных:
- Популярные решения:
- PostGIS (расширение PostgreSQL):
- Преимущества: Мощное геопространственное расширение для PostgreSQL, поддерживает сложные геооперации.
- Применение: Геоаналитика, картография, пространственные приложения.
- MongoDB с геоиндексацией:
- Преимущества: Встроенная поддержка геоиндексации, возможность выполнения запросов с использованием геоданных.
- Применение: Геоаналитика, местоположенные приложения, IoT.
- Oracle Spatial and Graph:
- Преимущества: Мощные средства обработки геоданных, интеграция с другими возможностями Oracle.
- Применение: Геоаналитика, системы управления местоположением.
- Microsoft SQL Server с пространственными типами:
- Преимущества: Встроенная поддержка пространственных типов данных и геоиндексации.
- Применение: Геоаналитика, системы управления местоположением, картография.
- PostGIS (расширение PostgreSQL):
- Характеристики:
- Специализированы для хранения и обработки географических данных.
- Поддерживают геоспецифичные запросы.
- Подходит для:
- Геолокационных приложений и сервисов.
- Анализа географических данных.
- Не подходит для:
- Проектов, не требующих обработки геоданных.
- Популярные решения:
- Аналитические СУБД:
- Популярные решения:
- IBM Db2:
- Преимущества: Масштабируемость, поддержка аналитики и искусственного интеллекта (ИИ).
- Применение: Крупные предприятия, системы бизнес-аналитики, использование ИИ.
- IBM Watson Discovery:
- Преимущества: Использование искусственного интеллекта для анализа неструктурированных данных.
- Применение: Анализ текстов, распознавание образов, поиск информации.
- Apache Spark:
- Преимущества: Высокая производительность в обработке больших данных, поддержка многозадачности.
- Применение: Обработка и анализ больших данных, машинное обучение, потоковая обработка.
- Apache Hadoop (Hive, HBase):
- Преимущества: Обработка и хранение больших объемов данных в распределенной среде.
- Применение: Обработка и анализ структурированных и неструктурированных данных.
- Databricks (на основе Apache Spark):
- Преимущества: Управление циклом разработки данных, облегченная работа с Apache Spark.
- Применение: Анализ данных, машинное обучение, исследование данных.
- Snowflake:
- Преимущества: Облачная платформа для хранения и анализа данных с поддержкой SQL.
- Применение: Хранение и анализ данных в облаке, работа с большими объемами данных.
- Tableau:
- Преимущества: Визуализация данных, поддержка подключения к различным источникам данных.
- Применение: Визуализация и анализ данных, создание дашбордов.
- Qlik Sense:
- Преимущества: Интерактивный анализ данных, создание гибких отчетов.
- Применение: Анализ данных, бизнес-интеллект, визуализация.
- Splunk:
- Преимущества: Обработка и анализ машинных данных, мониторинг логов.
- Применение: Мониторинг, анализ логов, безопасность.
- IBM Db2:
- Характеристики:
- Предназначены для обработки и анализа больших объемов данных. Аналитические СУБД обеспечивают высокую производительность и эффективность при выполнении сложных аналитических запросов и операций.
- Подходит для:
- задач, связанных с машинным обучением
- задач, связанных с анализом данных
- Не подходит для:
- задач, требующих оперативного доступа к данным
- Популярные решения:
Задания для подбора платформы БД
- Задача: Разработка системы управления крупным интернет-магазином.
- Требования: Обработка тысяч заказов в режиме реального времени, управление огромным ассортиментом товаров, сложные аналитические запросы.
- Платформа: Реляционная база данных с поддержкой горизонтального масштабирования, такая как PostgreSQL или MySQL с использованием индексации и кэширования.
- Задача: Разработка приложения для анализа и прогнозирования погоды.
- Требования: Хранение больших объемов географических данных, высокая производительность при выполнении сложных пространственных запросов.
- Платформа: База данных с поддержкой геоданных, такая как PostGIS (расширение PostgreSQL) или MongoDB с геоиндексацией.
- Задача: Разработка системы мониторинга и анализа больших данных для телекоммуникационной компании.
- Требования: Обработка и анализ больших объемов данных, реальное время обновления, поддержка многозадачности.
- Платформа: Распределенная система обработки данных, такая как Apache Spark или Databricks.
- Задача: Разработка приложения для учета и анализа медицинских записей пациентов.
- Требования: Сохранение конфиденциальных медицинских данных, строгая структура данных, поддержка транзакций и безопасность.
- Платформа: Реляционная база данных с повышенным уровнем безопасности, такая как Microsoft SQL Server или Oracle Database.
- Задача: Разработка системы машинного обучения для анализа поведения пользователей в социальных сетях.
- Требования: Обработка и хранение данных в формате графа, эффективная навигация по сложным графовым структурам.
- Платформа: Графовая база данных, такая как Neo4j или Amazon Neptune, способная эффективно обрабатывать и анализировать социальные графы.
- Задача: анализ больших объемов неструктурированных данных, таких как текстовые документы, изображения или аудиофайлы.
- Подходящая платформа: аналитическая СУБД, такая как Apache Spark или IBM Watson. Аналитические базы данных предназначены для обработки и анализа больших объемов данных и обеспечивают высокую производительность при выполнении сложных аналитических запросов.
Индивидуальное и групповое обучение «Аналитик данных»
Если вы хотите стать экспертом в аналитике, могу помочь. Запишитесь на мой курс «Аналитик данных» и начните свой путь в мир ИТ уже сегодня!
Контакты
Для получения дополнительной информации и записи на курсы свяжитесь со мной:
Телеграм: https://t.me/Vvkomlev
Email: victor.komlev@mail.ru
Объясняю сложное простыми словами. Даже если вы никогда не работали с ИТ и далеки от программирования, теперь у вас точно все получится! Проверено десятками примеров моих учеников.
Гибкий график обучения. Я предлагаю занятия в мини-группах и индивидуально, что позволяет каждому заниматься в удобном темпе. Вы можете совмещать обучение с работой или учебой.
Практическая направленность. 80%: практики, 20% теории. У меня множество авторских заданий, которые фокусируются на практике. Вы не просто изучаете теорию, а сразу применяете знания в реальных проектах и задачах.
Разнообразие учебных материалов: Теория представлена в виде текстовых уроков с примерами и видео, что делает обучение максимально эффективным и удобным.
Понимаю, что обучение информационным технологиям может быть сложным, особенно для новичков. Моя цель – сделать этот процесс максимально простым и увлекательным. У меня персонализированный подход к каждому ученику. Максимальный фокус внимания на ваши потребности и уровень подготовки.




