Оператор SELECT в SQL — это мощный инструмент, который позволяет извлекать и выбирать данные из базы данных. Это ключевое средство для получения нужной информации и осуществления поиска в базе данных. Основные моменты, которые следует подчеркнуть для новичков:
- Выбор данных: Оператор SELECT позволяет выбирать данные из таблицы или таблиц в базе данных. Вы можете выбрать все данные (все столбцы) или конкретные столбцы.
- Фильтрация данных: Вы можете использовать оператор WHERE, чтобы указать условия, которые должны быть выполнены для выборки данных. Это позволяет фильтровать данные и выбирать только нужные записи.
- Использование выражений: SELECT позволяет использовать различные типы выражений, такие как математические, логические, строковые, для вычисления значений и форматирования вывода.
- Группировка и агрегация: Вы можете группировать данные и использовать агрегатные функции (например, SUM, AVG, COUNT) для вычисления сумм, средних значений и других агрегированных данных.
- Сортировка данных: Вы можете сортировать результаты с помощью оператора ORDER BY, чтобы упорядочить их по заданным столбцам.
- Алиасы: Вы можете присваивать алиасы столбцам и выражениям, чтобы изменить имена столбцов в результатах запроса.
- Вложенные запросы: SELECT может использоваться для создания подзапросов, которые могут быть включены в основной запрос для сложных условий и фильтраций.
- Обработка ошибок и исключений: SELECT позволяет обрабатывать ошибки и исключения, что полезно при запросах к данным.
- Использование временных таблиц и CTE: Вы можете создавать временные таблицы и общие табличные выражения (CTE), чтобы улучшить организацию запросов и уменьшить дублирование кода.
Синтаксис select
Синтаксис оператора SELECT в PostgreSQL очень похож на стандартный синтаксис SQL. Оператор SELECT позволяет выбирать данные из таблицы или таблиц, фильтровать их, и возвращать результат в виде набора строк.
SELECT
column1, column2, ...
FROM
table_name
WHERE
condition
GROUP BY
column1, column2, ...
HAVING
aggregate_function(column) condition
ORDER BY
column1, column2, ...
LIMIT
number;
Давайте разберемся с каждой частью синтаксиса:
SELECT: Это ключевое слово, которое указывает, какие столбцы или данные вы хотите выбрать. Вы можете выбрать конкретные столбцы, использовать агрегатные функции или даже вычислять выражения.column1, column2, ...: Это перечисление столбцов или выражений, которые вы хотите выбрать. Можно использовать символ*, чтобы выбрать все столбцы.FROM: Это ключевое слово, за которым следует имя таблицы или таблиц, из которых вы хотите выбирать данные.WHERE: Это ключевое слово, которое используется для задания условия, по которому будут выбраны строки из таблицы. Это необязательная часть запроса.GROUP BY: Это ключевое слово, которое используется для группировки результатов по определенным столбцам.HAVING: Это ключевое слово, которое позволяет фильтровать группы результатов, полученных с использованием GROUP BY.ORDER BY: Это ключевое слово, которое используется для сортировки результатов по одному или нескольким столбцам.LIMIT: Это ключевое слово, которое ограничивает количество возвращаемых строк результатов.
Примеры использования оператора SELECT в PostgreSQL:
- Выбор всех столбцов из таблицы «employees»:
SELECT * FROM employees; - Выбор только имен и фамилий из таблицы «customers», удовлетворяющих условию:
SELECT first_name, last_name FROM customers WHERE city = 'New York'; - Группировка заказов по клиентам и подсчет количества заказов для каждого клиента:
SELECT customer_id, COUNT(order_id) as order_count FROM orders GROUP BY customer_id; - Выбор продуктов, отсортированных по цене в убывающем порядке, и ограничение результатов первыми 10 записями:
SELECT product_name, price FROM products ORDER BY price DESC LIMIT 10;
Ключевое слово SELECT
Ключевое слово SELECT в SQL используется для выбора данных из таблицы или таблиц. SELECT может быть использован с различными выражениями, столбцами и функциями для формирования вывода.
- Выбор конкретных столбцов таблицы. Этот запрос выбирает только столбцы
first_nameиlast_nameиз таблицыemployees.SELECT first_name, last_name FROM employees; - Вывод всех столбцов таблицы. Этот запрос выбирает все столбцы из таблицы
products.SELECT * FROM products; - Математические выражения. Этот запрос вычисляет общую стоимость (
total_price) как произведение столбцовquantityиpriceв таблицеorder_details.SELECT quantity * price AS total_price FROM order_details; - Логические выражения. Этот запрос использует CASE WHEN для создания выражения
availability, которое зависит от значенияstock_quantity.SELECT product_name, CASE WHEN stock_quantity > 0 THEN 'В наличии' ELSE 'Нет в наличии' END AS availability FROM products; - Строковые выражения. Этот запрос объединяет столбцы
first_nameиlast_nameв единое строковое выражениеfull_name.SELECT CONCAT(first_name, ' ', last_name) AS full_name FROM employees; - Вычисление агрегатных функций. Этот запрос вычисляет среднюю цену продуктов в таблице
productsс использованием функции AVG и присваивает ей имяaverage_price.SELECT AVG(price) AS average_price FROM products; - Использование алиасов (псевдонимов). Здесь алиасы «Product Name» и «discounted_price» применяются к столбцам для удобства чтения вывода.
SELECT product_name AS "Product Name", price * 0.9 AS discounted_price FROM products; - Соединение нескольких столбцов. В данном запросе используется оператор конкатенации
||, чтобы объединить столбцыfirst_nameиlast_nameв одно строковое выражениеfull_name.SELECT first_name || ' ' || last_name AS full_name FROM employees; - Использование математических операций. Здесь выполняется вычисление с использованием умножения и вычитания для получения конечной цены
final_price.SELECT (price * 1.1) - discount AS final_price FROM products; - Функции и выражения. В этом запросе используется функция UPPER для преобразования названия продукта в верхний регистр.
SELECT UPPER(product_name) AS capitalized_name FROM products;
Ключевое слово FROM
Ключевое слово FROM в SQL используется для указания источника данных, из которого будет выбираться информация. FROM может быть использовано с различными выражениями, включая таблицы, несколько таблиц, подзапросы, хранимые процедуры и представления.
- Выбор данных из одной таблицы. В этом запросе данные выбираются из одной таблицы «employees».
SELECT * FROM employees; - Выбор данных из нескольких таблиц. В этом запросе используется метод старой записи с перечислением таблиц после ключевого слова
FROM, и условие объединения таблиц находится в разделеWHERE.SELECT orders.order_id, customers.customer_name FROM orders, customers WHERE orders.customer_id = customers.customer_id; - Выборка с использованием подзапроса во
FROM. В этом запросе подзапрос используется в блокеFROMи затем объединяется с таблицей «products» с использованиемJOIN. Этот подход позволяет выбирать данные из «products» на основе результата подзапроса.SELECT product_name FROM (SELECT category_id FROM categories WHERE category_name = 'Electronics') AS subquery JOIN products ON subquery.category_id = products.category_id; - Выбор данных из хранимой процедуры. Здесь вызывается хранимая процедура «my_stored_procedure» с параметрами «param1» и «param2», и результаты выводятся как набор данных.
SELECT * FROM my_stored_procedure(param1, param2); - Выбор данных из представления. Здесь «my_view» — это представление, которое выглядит и используется как таблица, и вы можете выбирать данные из него так же, как из обычной таблицы.
SELECT * FROM my_view; - Использование алиасов (псевдонимов) для таблиц. Здесь алиасы «o» и «c» используются для представления таблиц «orders» и «customers», соответственно, в запросе.
SELECT o.order_id, c.customer_name FROM orders AS o JOIN customers AS c ON o.customer_id = c.customer_id; - Использование временных таблиц. В этом примере, «#» перед именем таблицы указывает, что это временная таблица, которая используется в запросе.
SELECT * FROM #temp_table; - Использование CTE (Common Table Expression). Здесь CTE используется для создания временной таблицы, которая затем используется в основном запросе.
Ключевое слово WHERE
Ключевое слово WHERE в SQL используется для фильтрации данных, позволяя выбирать только те строки, которые соответствуют определенным условиям. Вот различные выражения, которые могут идти после ключевого слова WHERE:
- Операторы сравнения:
=(равно)!=или<>(не равно)<(меньше чем)>(больше чем)<=(меньше или равно)>=(больше или равно)
Пример с операторами сравнения:
SELECT product_name, price FROM products WHERE price > 50; - Логические операторы.
AND(и)OR(или)NOT(не)
Пример с логическими операторами:
SELECT first_name, last_name FROM employees WHERE department = 'Sales' AND salary > 50000; - Соединения таблиц. Вы можете использовать WHERE для связи таблиц и применения условий для объединения данных из разных таблиц. Пример соединения таблиц:
SELECT customers.customer_name, orders.order_date FROM customers WHERE customers.customer_id = orders.customer_id; - Использование функций. Вы можете использовать функции в условиях WHERE для фильтрации данных на основе вычисленных значений. Пример с функцией:
SELECT order_id, order_date FROM orders WHERE DATE_DIFF(NOW(), order_date) > 30; - Использование BETWEEN:BETWEEN используется для определения диапазона значений. Пример с BETWEEN:
SELECT product_name, price FROM products WHERE price BETWEEN 50 AND 100; - Использование IN:IN позволяет фильтровать данные по множеству значений. Пример с IN:
SELECT product_name, category FROM products WHERE category IN ('Electronics', 'Appliances'); - Использование LIKE:LIKE используется для поиска строк, соответствующих шаблону. Пример с LIKE:
SELECT product_name FROM products WHERE product_name LIKE 'Laptop%'; - Использование IS NULL / IS NOT NULL:IS NULL используется для поиска значений, которые являются NULL.Пример с IS NULL:
SELECT first_name, last_name FROM employees WHERE manager_id IS NULL;
Ключевые слова GROUP BY, HAVING
Ключевые слова GROUP BY и HAVING в SQL используются для группировки данных и применения агрегатных функций и фильтров к этим группам.
GROUP BY:
- Группировка по полям: Вы можете группировать данные по одному или нескольким столбцам таблицы. Пример группировки по полю:
SELECT department, COUNT(*) as employees_count FROM employees GROUP BY department; - Группировка по выражениям: Вы можете создавать выражения для группировки, которые могут быть результатом вычислений или комбинацией столбцов. Пример группировки по выражению:
SELECT YEAR(order_date) as order_year, COUNT(*) as order_count FROM orders GROUP BY YEAR(order_date); - Группировка по аргументам функций: Вы можете использовать функции в аргументах GROUP BY.Пример группировки по аргументу функции:
SELECT EXTRACT(MONTH FROM order_date) as month, COUNT(*) as order_count FROM orders GROUP BY EXTRACT(MONTH FROM order_date);
HAVING
- Фильтрация по результатам агрегатных функций:
HAVINGиспользуется для фильтрации результатов агрегатных функций, которые были вычислены послеGROUP BY.Пример использованияHAVING:SELECT department, AVG(salary) as avg_salary FROM employees GROUP BY department HAVING AVG(salary) > 50000; - Фильтрация по агрегатным функциям с использованием логических операторов: Вы можете комбинировать агрегатные функции с логическими операторами, чтобы задать сложные условия фильтрации. Пример с логическим оператором в
HAVING:SELECT department, AVG(salary) as avg_salary, COUNT(*) as employee_count FROM employees GROUP BY department HAVING AVG(salary) > 50000 AND COUNT(*) > 10; - Использование агрегатных функций в
HAVING:HAVINGтакже может включать агрегатные функции для дополнительной фильтрации. Пример с агрегатной функцией вHAVING:SELECT department, AVG(salary) as avg_salary FROM employees GROUP BY department HAVING AVG(salary) > MIN(salary); - Фильтрация по количеству группировок: Вы можете использовать
HAVINGдля фильтрации группировок на основе количества элементов в каждой группе.Пример фильтрации по количеству группировок:SELECT category, COUNT(*) as product_count FROM products GROUP BY category HAVING COUNT(*) > 5;
Ключевое слово ORDER BY
Ключевое слово ORDER BY в SQL используется для сортировки результатов запроса в определенном порядке. Вот различные выражения, которые могут идти после ключевого слова ORDER BY:
- Сортировка по полям БД: Вы можете сортировать результаты запроса по одному или нескольким столбцам таблицы в возрастающем (ASC) или убывающем (DESC) порядке. Пример сортировки по столбцу:
SELECT product_name, price FROM products ORDER BY price ASC; - Сортировка по убыванию: Если вы хотите выполнить сортировку в убывающем порядке, используйте ключевое слово DESC.Пример с сортировкой по убыванию:
SELECT customer_name, order_date FROM orders ORDER BY order_date DESC; - Сортировка по нескольким столбцам: Вы можете использовать выражения для сортировки, которые могут быть результатом вычислений или комбинацией столбцов. Пример сортировки по нескольким столбцам:
SELECT first_name, last_name FROM employees ORDER BY last_name, first_name; - Сортировка по функциям: Вы можете использовать функции в выражениях ORDER BY для упорядочивания данных. Пример сортировки с использованием функции:
SELECT product_name, LENGTH(product_name) as name_length FROM products ORDER BY name_length; - Сортировка по агрегатным функциям: Вы также можете сортировать результаты, используя агрегатные функции. Пример сортировки с использованием агрегатной функции:
SELECT department, AVG(salary) as avg_salary FROM employees GROUP BY department ORDER BY avg_salary DESC; - Сортировка по случайному порядку: Если вы хотите случайный порядок, вы можете использовать функцию RANDOM() (или другую, в зависимости от СУБД).Пример с сортировкой в случайном порядке:
SELECT product_name FROM products ORDER BY RANDOM(); - Сортировка по частоте: Вы можете сортировать данные по количеству вхождений значения с помощью COUNT и GROUP BY.Пример сортировки по частоте:
SELECT category, COUNT(*) as product_count FROM products GROUP BY category ORDER BY product_count DESC;
Ключевое слово LIMIT
Ключевое слово LIMIT в SQL используется для ограничения количества строк, возвращаемых в результате запроса SELECT. Это полезное средство для выбора определенного количества наиболее релевантных или первых строк из результата запроса. Вот примеры его использования:
- Ограничение количества строк: Вы можете использовать LIMIT, чтобы ограничить количество возвращаемых строк. Например, следующий запрос вернет только первые 10 записей из таблицы:
SELECT * FROM employees LIMIT 10; - Ограничение с определенной позиции: Вы также можете указать начальную позицию для выборки с помощью OFFSET, что особенно полезно, если вам нужны записи, начиная с определенного места. Пример с OFFSET и LIMIT. Этот запрос вернет строки с шестой по пятнадцатую включительно из таблицы «products».
SELECT * FROM products OFFSET 5 LIMIT 10; - Использование LIMIT с ORDER BY:LIMIT часто используется с ORDER BY для выбора наиболее релевантных или первых записей в отсортированных результатах. Пример с LIMIT и ORDER BY. Этот запрос вернет пять записей с наибольшей ценой из таблицы «products».
SELECT product_name, price FROM products ORDER BY price DESC LIMIT 5; - Использование LIMIT для пагинации:LIMIT также часто используется для пагинации результатов, разбивая их на более мелкие части. Пример с LIMIT для пагинации. Этот запрос вернет 10 записей, начиная с двадцатой, что обеспечит пагинацию результатов.
SELECT * FROM orders LIMIT 10 OFFSET 20;
Ключевое слово INTO
Ключевое слово INTO в SQL используется в запросах SELECT, чтобы сохранить результаты запроса в новую таблицу или временную таблицу. Это может быть полезным, когда вы хотите сохранить результаты запроса для дальнейшей обработки или анализа.
- Создание новой таблицы на основе результатов запроса: Вы можете использовать INTO для создания новой таблицы и сохранения результатов запроса в эту таблицу. В этом примере результаты запроса (наименования продуктов и цены) сохраняются в новую таблицу «new_product_prices».
SELECT product_name, price INTO new_product_prices FROM products WHERE price > 100; - Создание временной таблицы: Вы также можете использовать INTO для создания временной таблицы, которая существует только в пределах текущей сессии. Здесь результаты запроса сохраняются во временной таблице «#temp_orders», которая будет доступна только в рамках текущей сессии.
SELECT customer_name, order_date INTO #temp_orders FROM orders WHERE order_date > '2023-01-01'; - Создание таблицы с использованием алиасов: Вы также можете задать алиас для таблицы, которая создается при использовании INTO. В этом примере создается временная таблица «new_prices», и результаты запроса сохраняются в нее.
SELECT product_name, price INTO TEMPORARY TABLE new_prices FROM products WHERE price > 200;
Ключевое слово INTO позволяет сохранять результаты запроса в новую таблицу для последующей обработки или анализа. При использовании INTO, убедитесь, что вы имеете соответствующие права доступа для создания новых таблиц в базе данных.
Ключевое слово JOIN
Ключевое слово JOIN в SQL используется для объединения данных из двух или более таблиц на основе определенных условий. Соединения позволяют вам объединять данные из разных таблиц для выполнения сложных запросов. В PostgreSQL существуют различные типы соединений. Вот примеры разных видов соединений:
- INNER JOIN (Внутреннее соединение):INNER JOIN выбирает только те строки, которые имеют соответствующие значения в обеих таблицах. В этом примере мы соединяем таблицы «employees» и «departments» по полю «department_id» и выбираем имена сотрудников и названия их отделов.
SELECT employees.employee_id, employees.first_name, departments.department_name FROM employees INNER JOIN departments ON employees.department_id = departments.department_id; - LEFT JOIN (Левое соединение):LEFT JOIN возвращает все строки из левой таблицы и соответствующие строки из правой таблицы. Если соответствия в правой таблице нет, то будут возвращены NULL значения. Этот запрос вернет список клиентов и даты их заказов, если заказы существуют, и NULL, если заказов нет.
SELECT customers.customer_name, orders.order_date FROM customers LEFT JOIN orders ON customers.customer_id = orders.customer_id; - RIGHT JOIN (Правое соединение):RIGHT JOIN возвращает все строки из правой таблицы и соответствующие строки из левой таблицы. Если соответствия в левой таблице нет, то будут возвращены NULL значения. Этот запрос вернет список заказов и имена клиентов, если клиенты существуют, и NULL, если клиентов нет.
SELECT orders.order_id, customers.customer_name FROM orders RIGHT JOIN customers ON orders.customer_id = customers.customer_id; - FULL OUTER JOIN (Полное внешнее соединение):FULL OUTER JOIN возвращает все строки из обеих таблиц, а если соответствия нет, то будут возвращены NULL значения. В этом запросе будут возвращены все сотрудники и их отделы, включая тех, у кого отдел не указан (NULL), и отделы, в которых нет сотрудников.
SELECT employees.employee_id, employees.first_name, departments.department_name FROM employees FULL OUTER JOIN departments ON employees.department_id = departments.department_id; - SELF JOIN (Соединение с самим собой):SELF JOIN позволяет соединить таблицу с самой собой. Это полезно, когда в таблице есть связи между записями. Этот запрос позволяет найти руководителей и их подчиненных.
SELECT e1.employee_name, e2.employee_name FROM employees e1 JOIN employees e2 ON e1.manager_id = e2.employee_id; - CROSS JOIN (Кросс-соединение):CROSS JOIN возвращает декартово произведение строк из двух таблиц, то есть каждая строка из левой таблицы будет объединена с каждой строкой из правой таблицы. Это соединение не использует условия сопоставления, и результатом является полный набор возможных комбинаций строк.CROSS JOIN полезен, когда вам необходимо выполнить полное объединение всех строк из двух таблиц, и он может привести к большому количеству строк в результате, поэтому его следует использовать осторожно и обдуманно. В этом примере каждый продукт будет объединен с каждой категорией, что приведет к созданию всех возможных комбинаций продуктов и категорий.
SELECT products.product_name, categories.category_name FROM products CROSS JOIN categories;
Простой вывод данных с помощью SELECT SQL
Рассмотрим простые примеры получения данных с помощью SELECT
- Выбор всех полей из таблицы: Для выбора всех полей из таблицы используйте символ звездочки (*).Этот запрос выберет все строки и все столбцы из таблицы «employees».
SELECT * FROM employees; - Вывод произвольного текста: Вы можете вывести произвольный текст в результатах запроса, заключив его в одинарные или двойные кавычки. Этот запрос вернет строку «Привет, мир!».
SELECT 'Привет, мир!'; - Математическое выражение: Вы можете выполнять математические операции в запросах. Например, вычислить сумму или разность чисел. Этот запрос вернет результат математической операции: 15.
SELECT 10 + 5; - Вывод произвольных полей: Вы можете выбирать только те столбцы, которые вам нужны, и изменять их порядок в результатах. Этот запрос вернет имена сотрудников и их зарплату, но без других полей.
SELECT first_name, last_name, salary FROM employees;
Получение уникальных значений с помощью DISTINCT
Ключевое слово DISTINCT в SQL используется для выбора уникальных значений в столбцах запроса.
Это полезное средство, когда вам нужно извлечь только разные значения из столбцов, исключив дубликаты. Вот как оно работает и как его использовать:
Предположим, у вас есть таблица «orders», и вы хотите вывести список уникальных городов, в которых живут клиенты:
SELECT DISTINCT city
FROM orders;
В результате этого запроса будут выведены только уникальные значения из столбца «city». Если в исходной таблице есть несколько записей с одним и тем же значением «city», DISTINCT позволит вывести это значение только один раз.
Важные моменты использования DISTINCT:
- DISTINCT применяется к столбцам, и вы можете указать несколько столбцов для выбора уникальных комбинаций значений. Этот запрос вернет уникальные комбинации имен и фамилий среди сотрудников.
SELECT DISTINCT first_name, last_nameFROM employees; - DISTINCT работает только на том столбце (или комбинации столбцов), к которому он применяется. Другие столбцы в результирующем наборе данных могут содержать дубликаты.
- DISTINCT может быть использован совместно с другими операторами, такими как ORDER BY или WHERE, для более точной фильтрации и сортировки уникальных значений.
Применение DISTINCT может быть полезно при выполнении анализа данных, создании отчетов или извлечении уникальных значений из больших наборов данных.
Использование псевдонимов (алиасов) в SELECT
Псевдонимы (или алиасы) в блоке SELECT используются для присвоения временных имен столбцам или выражениям в результатах запроса.
Их главное назначение — улучшить читаемость и ясность SQL-запросов. Вот некоторые случаи, когда их использование может быть полезным:
- Улучшение читаемости запросов: Псевдонимы позволяют давать столбцам и выражениям более информативные и понятные имена, что делает SQL-запросы более понятными для разработчиков и обслуживающего персонала. Пример:
SELECT first_name AS "Имя", last_name AS "Фамилия" FROM employees; - Избегание дублирования столбцов: Если в запросе используются вычисления или функции, то псевдонимы позволяют избежать дублирования выражений в результате запроса. В этом примере «total_price» — это псевдоним для выражения «product_price * quantity», что делает результат более читаемым.
SELECT order_date, product_price, quantity, product_price * quantity AS total_price FROM order_details; - Избегание конфликта имен: Если имена столбцов в разных таблицах совпадают, псевдонимы позволяют избежать конфликта имен и однозначно указать, из какой таблицы берется каждый столбец. Пример:
SELECT e.first_name AS "Имя сотрудника", d.department_name AS "Название отдела" FROM employees e JOIN departments d ON e.department_id = d.department_id;
Важно понимать, что псевдонимы не являются обязательными, их использование зависит от конкретных потребностей и структуры SQL-запроса. Они приносят пользу, когда нужно улучшить читаемость, ясность и однозначность запросов.
Использование псевдонимов — это хорошая практика, когда:
- Требуется дать более описательные имена столбцам или выражениям.
- Есть вычисления или функции в запросе, и вы хотите сделать результат более понятным.
- В запросе присутствуют таблицы с одинаковыми именами столбцов.
Псевдонимы делают SQL-запросы более ясными, а результаты читаемыми.
Работа с числовыми данными в запросах SELECT
Работа с числами в SQL запросах в PostgreSQL включает в себя различные аспекты, такие как арифметические операции, использование скобок в арифметических выражениях, преобразование типов и использование функций для работы с числовыми данными.
- Основные арифметические операции: В PostgreSQL, вы можете выполнять стандартные арифметические операции:
- Сложение:
+ - Вычитание:
- - Умножение:
* - Деление:
/ - Взятие остатка:
%
Пример:
SELECT 5 + 3 AS sum, 10 - 4 AS difference, 6 * 7 AS product, 20 / 4 AS division, 15 % 4 AS remainder; - Сложение:
- Использование скобок в арифметических выражениях: Вы можете использовать скобки для определения приоритета выполнения операций в арифметических выражениях.Пример:
SELECT (5 + 3) * (10 - 4) AS result; - Преобразование типов: Вы можете преобразовывать числовые значения из одного типа данных в другой с помощью приведения типов. Например, преобразование целого числа (integer) в число с плавающей запятой (double precision):Пример:
SELECT CAST(5 AS double precision) AS float_number; - Основные функции для работы с числовыми типами данных: В PostgreSQL есть множество встроенных функций для работы с числовыми данными. Некоторые из них включают
ABS(абсолютное значение),ROUND(округление),CEIL(округление в большую сторону),FLOOR(округление в меньшую сторону),POWER(возведение в степень) и многие другие.Пример:SELECT ABS(-5) AS absolute_value, ROUND(3.1415926535, 2) AS rounded_value, CEIL(3.5) AS ceil_value, FLOOR(3.5) AS floor_value, POWER(2, 3) AS power_result; - Работа с NULL значениями: В SQL, при выполнении арифметических операций с NULL значениями, результат также будет NULL. Вы можете использовать функции, такие как
COALESCEилиIS NULLдля обработки NULL значений.Пример:SELECT COALESCE(column1, 0) AS value_with_default FROM some_table;
Какие основные типы числовых данных есть в Postgres?
В PostgreSQL существует несколько основных типов числовых данных, которые позволяют хранить разные виды чисел. Вот некоторые из них:
- integer, int4, int (целое число): Тип данных
integerиспользуется для хранения целых чисел без десятичных знаков. Этот тип данных имеет фиксированный размер и обычно занимает 4 байта памяти.Пример:42,-123,0. - bigint, int8 (длинное целое число): Тип данных
bigintпредназначен для хранения очень больших целых чисел. Он имеет больший размер по сравнению сintegerи обычно занимает 8 байт памяти.Пример:1234567890123456789,-9876543210987654321. - numeric (число с фиксированной точностью): Тип данных
numericиспользуется для хранения чисел с фиксированной точностью, что позволяет точное представление чисел с десятичными знаками.Пример:3.1415926535,12345.67,-0.005. - real (число с плавающей запятой): Тип данных
realиспользуется для хранения чисел с плавающей запятой одинарной точности (с плавающей точкой). Этот тип данных подходит для большинства вычислений, но имеет ограниченную точность.Пример:3.14,-0.01,12345.678. - double precision (число с плавающей запятой двойной точности): Тип данных
double precisionпредназначен для хранения чисел с плавающей запятой двойной точности. Он имеет более высокую точность по сравнению сreal.Пример:3.141592653589793,-0.000000001,98765432.10987654321. - smallint, int2 (малое целое число): Тип данных
smallintиспользуется для хранения небольших целых чисел. Он имеет фиксированный размер и обычно занимает 2 байта памяти.Пример:5,-10,0. - serial и bigserial (автоинкрементные целые числа): Эти типы данных используются для автоматической генерации уникальных целых чисел.
serialиспользуется для создания 4-байтовых чисел, аbigserial— для 8-байтовых чисел.Пример: Вам не нужно вводить примеры для этих типов, так как они генерируются автоматически.
Какие типы данных используются для работы с денежными величинами?
В PostgreSQL для работы с денежными величинами существует специальный числовой тип данных, который называется «money.» Тип данных «money» предназначен для хранения и обработки финансовых значений, таких как цены, бюджеты, суммы денег и другие связанные с деньгами данные. Этот тип данных обеспечивает точное представление и арифметику для денежных операций.
Пример объявления столбца с типом данных «money» в таблице:
CREATE TABLE transactions (
transaction_id serial PRIMARY KEY,
transaction_date date,
amount money
);
С использованием типа данных «money,» вы можете легко выполнять арифметические операции с денежными значениями, такие как сложение, вычитание и умножение. Вот примеры:
-- Сложение денежных значений
SELECT (10.50::money + 5.25::money) AS total_amount;
-- Вычитание денежных значений
SELECT (100.75::money - 20.25::money) AS remaining_balance;
-- Умножение денежного значения на коэффициент
SELECT (15.00::money * 0.1) AS discount_amount;
Важно отметить, что для корректной работы с денежными значениями в PostgreSQL рекомендуется использовать явное приведение типов, как показано в примерах выше (например, 10.50::money). Это позволяет избежать потери точности в арифметических операциях. Тип данных «money» обеспечивает точное хранение и обработку денежных величин в рамках вашей базы данных.
Преобразование типов в PostgreSQL
В PostgreSQL есть несколько способов приведения типов данных
- Функции приведения типов: PostgreSQL предоставляет функции приведения типов, которые могут использоваться для изменения типа данных значения. Например, функция
CAST:SELECT CAST('42' AS integer) AS integer_value; - Использование функций преобразования: PostgreSQL предоставляет функции преобразования типов, такие как
::int,::text,::date, и другие. Например:SELECT '2023-10-13'::date AS date_value;
Функции PostgreSQL для работы с числами
PostgreSQL предоставляет множество встроенных функций для работы с числами. Эти функции позволяют выполнять различные математические операции, округление, нахождение абсолютного значения и многое другое. Давайте рассмотрим некоторые из этих функций и их примеры использования:
- ABS() — абсолютное значение: Функция
ABS()возвращает абсолютное значение числа, то есть значение без учета его знака.Результат:5SELECT ABS(-5) AS absolute_value; - ROUND() — округление: Функция
ROUND()используется для округления числа до определенного количества знаков после запятой.Результат:3.14SELECT ROUND(3.1415926535, 2) AS rounded_value; - CEIL() — округление в большую сторону: Функция
CEIL()выполняет округление числа до ближайшего большего целого значения.Результат:4SELECT CEIL(3.5) AS ceil_value; - FLOOR() — округление в меньшую сторону: Функция
FLOOR()выполняет округление числа до ближайшего меньшего целого значения.Результат:3SELECT FLOOR(3.5) AS floor_value; - POWER() — возведение в степень: Функция
POWER()используется для возведения числа в заданную степень.Результат:8SELECT POWER(2, 3) AS power_result; - SQRT() — квадратный корень: Функция
SQRT()вычисляет квадратный корень числа.Результат:4SELECT SQRT(16) AS square_root; - MOD() — остаток от деления: Функция
MOD()вычисляет остаток от деления двух чисел.Результат:1SELECT MOD(10, 3) AS remainder;
В СУБД PosgreSQL существует множество других функций, включая тригонометрические функции, логарифмы, экспоненты и так далее.
Значения NULL
Значение NULL в базах данных представляет собой особую концепцию, которая обозначает отсутствие данных в определенном столбце или поле.
- Отсутствие значения: NULL означает, что в данной ячейке данных нет конкретного значения. Это не то же самое, что ноль, пустая строка или какое-либо другое конкретное значение. Это говорит о том, что данные отсутствуют или неизвестны.
- Гибкость и допустимость: NULL дает возможность столбцам в таблицах иметь гибкую структуру. Например, вы можете иметь столбец для даты рождения, и не все записи обязательно должны иметь эту дату. Может быть, у вас нет информации о дате рождения некоторых людей, и NULL позволяет вам указать это.
- Примеры использования:
- Данные о клиентах: В таблице клиентов некоторые клиенты могут указать свой номер телефона, а некоторые — нет. В этом случае для тех клиентов, у которых номер неизвестен, можно использовать NULL в соответствующем столбце.
- Данные о заказах: В таблице заказов можно иметь столбец для даты доставки. Если заказ еще не доставлен, то это поле можно оставить пустым (NULL) до момента доставки.
- Отсутствие данных: Если вы собираете статистику о посещаемости вашего веб-сайта, и некоторые страницы не посещались, то можно использовать NULL для отметки отсутствия данных.
Операторы и функции для работы с NULL.
- IS NULL: Оператор
IS NULLиспользуется для проверки, является ли значение NULL. Он возвращаетtrue, если значение NULL, иfalse, если не NULL.Этот запрос выбирает имена сотрудников, у которых не указан отдел.SELECT name FROM employees WHERE department IS NULL; - IS NOT NULL: Оператор
IS NOT NULLиспользуется для проверки, не является ли значение NULL. Он возвращаетtrue, если значение не NULL, иfalse, если NULL.Этот запрос выбирает названия продуктов, у которых есть дата истечения срока годности.SELECT product_name FROM products WHERE expiration_date IS NOT NULL; - COALESCE(): Функция
COALESCE()используется для выбора первого ненулевого значения из заданных аргументов. Она принимает список значений и возвращает первое ненулевое значение.SELECT COALESCE(primary_phone, secondary_phone, emergency_phone) AS contact_number FROM contacts; - NULLIF(): Функция
NULLIF()используется для сравнения двух значений. Если значения равны, она возвращает NULL; в противном случае, она возвращает первое значение. Этот запрос возвращает зарплату сотрудников, и если зарплата равна 0, она заменяется NULLSELECT NULLIF(salary, 0) AS valid_salary FROM employees; - CASE WHEN: Оператор
CASE WHENпозволяет создавать условные выражения. Вы можете использовать его для обработки NULL значений и определения, какие значения использовать в зависимости от условия. В этом примере, если у клиента нет номера телефона, вместо NULL выводится текст «Нет телефона».SELECT name, CASE WHEN phone_number IS NULL THEN 'Нет телефона' ELSE phone_number END AS contact_info FROM customers;
Работа с текстовыми (строковыми) данными в PostgreSQL
В PostgreSQL есть множество возможностей для работы с текстовыми данными. Давайте рассмотрим основные типы данных, операторы и функции для работы с текстом:
Типы данных для текста.
- CHAR(N) и VARCHAR(N): Эти типы данных предназначены для хранения строк фиксированной и переменной длины соответственно.
CHAR(N)хранит строку фиксированной длины, гдеN— максимальное количество символов, в то время какVARCHAR(N)хранит строку переменной длины, гдеN— максимальное количество символов. Пример:CREATE TABLE employees ( employee_id serial PRIMARY KEY, first_name VARCHAR(50), last_name VARCHAR(50) ); - TEXT: Тип данных
TEXTиспользуется для хранения строк переменной длины без ограничений на размер. Этот тип данных подходит для хранения длинных текстовых данных.CREATE TABLE articles ( article_id serial PRIMARY KEY, title TEXT, content TEXT );
Текстовые операторы
- Конкатенация строк: Для объединения строк используется оператор
||. Например, для объединения имени и фамилии. Этот запрос объединяет имя и фамилию с пробелом.SELECT first_name || ' ' || last_name AS full_name FROM employees; - Проверка значений. LIKE: Оператор
LIKEиспользуется для выполнения поиска подстроки в строке с использованием шаблона.%соответствует любой подстроке, а_соответствует одному символу.SELECT name FROM products WHERE name LIKE 'Apple%';
Основные функции для работы с текстом
- LENGTH(): Функция
LENGTH()возвращает длину строки в символах. Результат:13SELECT LENGTH('Hello, world!') AS string_length; - LOWER() и UPPER(): Функции
LOWER()иUPPER()используются для преобразования текста в нижний или верхний регистр соответственно. Результат:helloиWORLDSELECT LOWER('Hello') AS lower_case, UPPER('World') AS upper_case; - SUBSTRING(): Функция
SUBSTRING()позволяет извлечь подстроку из текста на основе заданных начального и конечного индексов. Результат:is a samSELECT SUBSTRING('This is a sample text', 6, 9) AS extracted_text; - TRIM(): Функция
TRIM()удаляет пробелы или другие символы из начала и конца строки. Результат:Trim thisSELECT TRIM(' ' FROM ' Trim this ') AS trimmed_text; - CONCAT(): Функция
CONCAT()используется для конкатенации строк. Результат:Hello, world!SELECT CONCAT('Hello, ', 'world!') AS concatenated_text; - POSITION(): Функция
POSITION()находит позицию подстроки в строке. Результат:7SELECT POSITION('world' IN 'Hello, world!') AS position; - TO_CHAR(): Функция
TO_CHAR()используется для форматирования чисел, дат и времени в текстовые строки. Результат:1234.57SELECT TO_CHAR(1234.567, '9999.99') AS formatted_number; - SPLIT_PART(): Функция
SPLIT_PART()разделяет строку на подстроки с заданным разделителем и возвращает указанную подстроку. Результат:bananaSELECT SPLIT_PART('apple|banana|cherry', '|', 2) AS second_fruit; - REPLACE(): Функция
REPLACE()используется для замены всех вхождений подстроки на другую подстроку в строке. Результат:This is a replacement textSELECT REPLACE('This is a sample text', 'sample', 'replacement') AS replaced_text;
Работа с кодировками и способами сортировки
В контексте текстовых типов данных в PostgreSQL кодировка и способ сортировки играют важную роль:
- Кодировка (Character Encoding): Кодировка определяет, как символы (буквы, цифры, символы пунктуации и другие) представляются в бинарной форме в базе данных. Каждая кодировка представляет символы разными последовательностями байтов. PostgreSQL поддерживает различные кодировки, включая UTF-8 (Unicode), LATIN1, KOI8-R и многие другие.
- UTF-8 (Unicode): Это самая распространенная кодировка, которая поддерживает множество символов, включая символы различных языков и эмодзи. UTF-8 является стандартом для многих приложений, поддерживающих многоязычные данные.
- LATIN1: Эта кодировка используется для поддержки символов латинского алфавита и поддерживает ограниченное количество символов.
Выбор кодировки важен при создании базы данных, так как это определяет, как данные будут храниться и отображаться. Он также влияет на производительность и экономию места.
- Способ сортировки (Collation): Способ сортировки определяет порядок, в котором текстовые значения сравниваются и сортируются. Разные языки и регионы могут иметь различные правила сортировки.
- По умолчанию: В PostgreSQL, если не указан способ сортировки, используется «C» (POSIX) способ сортировки, который может не подходить для некоторых языков и культур.
- Локальные способы сортировки: PostgreSQL поддерживает различные локальные способы сортировки, которые учитывают правила сортировки для конкретного языка или региона. Например, «fr_FR» — для французского, «ru_RU» — для русского и т. д.
Выбор правильного способа сортировки важен, чтобы данные отображались и сортировались корректно для конкретной локали.
При создании базы данных или таблицы в PostgreSQL, вы можете указать как кодировку, так и способ сортировки, чтобы удовлетворить потребности конкретной задачи. Неправильный выбор кодировки и способа сортировки может привести к неправильному отображению данных и некорректной сортировке, поэтому это важно учитывать при разработке баз данных, особенно для многоязычных приложений.
Функции для работы с кодировками и способами сортировки.
- CONVERT(): Функция
CONVERT()используется для преобразования текста из одной кодировки в другую. Этот запрос преобразует текст из кодировки UTF-8 в LATIN1.SELECT CONVERT('Привет, мир!', 'UTF8', 'LATIN1') AS converted_text; - COLLATE: С помощью оператора
COLLATEвы можете задать специфическую коллацию для сортировки, что полезно, например, при сортировке текста на разных языках. Этот запрос сортирует имена клиентов, используя французскую коллацию.SELECT customer_name FROM customers ORDER BY customer_name COLLATE "fr_FR";
Использование регулярных выражений в запросах
В PostgreSQL, для использования регулярных выражений для поиска и замены информации в полях БД, вы можете использовать операторы ~ (соответствие) и ~* (соответствие без учета регистра). Рассмотрим примеры:
Пример 1: Поиск с использованием оператора ~
-- Найти все строки, где столбец column_name содержит слово 'apple'
SELECT *
FROM your_table
WHERE column_name ~ 'apple';
Пример 2: Поиск с использованием оператора ~* (без учета регистра)
-- Найти все строки, где столбец column_name содержит слово 'apple' независимо от регистра
SELECT *
FROM your_table
WHERE column_name ~* 'apple';
Функция regexp_matches
regexp_matches — это функция PostgreSQL, которая возвращает массив текстовых значений, соответствующих регулярному выражению. Давайте рассмотрим примеры применения этой функции:
- Первое соответствие: Вернем первое соответствие в столбце
text_column, начинающееся с буквы «A»:SELECT text_column, (regexp_matches(text_column, 'A.*?'))[1] AS first_match FROM your_table;Этот запрос возвращает текстовый столбец и первое соответствие, начинающееся с «A».
- Все соответствия: Вернем все соответствия в столбце
text_column, начинающиеся с буквы «A»:SELECT text_column, unnest(regexp_matches(text_column, 'A.*?')) AS all_matches FROM your_table;Здесь мы используем
unnest, чтобы преобразовать массив в ряд значений и вернуть все соответствия, начинающиеся с «A». - Получение групп из соответствий: Допустим, у нас есть регулярное выражение с группой захвата для извлечения даты в формате «гггг-мм-дд». Мы можем использовать
regexp_matchesдля извлечения даты:SELECT text_column, (regexp_matches(text_column, '(\d{4}-\d{2}-\d{2})'))[1] AS extracted_date FROM your_table;Здесь мы используем группу захвата
(\d{4}-\d{2}-\d{2})для извлечения даты в формате «гггг-мм-дд».[1]обозначает первую группу захвата в результатах.
Замена с помощью регулярных выражений.
- Простая замена: Заменим все пробелы на дефисы в столбце
text_column:SELECT text_column, regexp_replace(text_column, ' ', '-') AS replaced_text FROM your_table;В этом запросе мы используем функцию
regexp_replace, чтобы заменить все пробелы на дефисы в столбцеtext_column. - Замена с использованием групп: Допустим, у нас есть столбец, содержащий строки в формате «Фамилия, Имя». Мы хотим поменять местами фамилию и имя с использованием регулярного выражения:
SELECT full_name, regexp_replace(full_name, '([^,]+),\s([^,]+)', '\2 \1') AS swapped_names FROM your_table;В этом запросе мы используем группы захвата
([^,]+)для извлечения фамилии и имени. Затем в функцииregexp_replaceмы меняем местами группы, используя\2для второй группы (имени) и\1для первой группы (фамилии).
Работа с датой и временем в PostgreSQL
В PostgreSQL есть множество возможностей для работы с датой и временем. Давайте рассмотрим основные типы данных, операторы и функции для работы с датой и временем:
Основные типы данных для даты и времени
- DATE: Тип данных
DATEиспользуется для хранения календарных дат (год, месяц, день) без времени. Пример:CREATE TABLE events ( event_id serial PRIMARY KEY, event_date DATE, event_description TEXT ); - TIME: Тип данных
TIMEиспользуется для хранения времени с точностью до миллисекунд. Пример:CREATE TABLE appointments ( appointment_id serial PRIMARY KEY, appointment_time TIME, appointment_description TEXT ); - TIMESTAMP: Тип данных
TIMESTAMPиспользуется для хранения даты и времени с точностью до миллисекунд. Пример:CREATE TABLE orders ( order_id serial PRIMARY KEY, order_date TIMESTAMP, order_total DECIMAL(10, 2) ); - TIMESTAMP WITH TIME ZONE: Тип данных
TIMESTAMP WITH TIME ZONEхранит дату и время с учетом часового пояса. Пример:CREATE TABLE flights ( flight_id serial PRIMARY KEY, departure_time TIMESTAMP WITH TIME ZONE, destination TEXT );
Операторы для работы с датой и временем.
- CURRENT_DATE и CURRENT_TIME: Операторы
CURRENT_DATEиCURRENT_TIMEвозвращают текущую дату и текущее время соответственно. Пример:SELECT CURRENT_DATE AS current_date, CURRENT_TIME AS current_time; - NOW(): Функция
NOW()возвращает текущую дату и время. Пример:SELECT NOW() AS current_datetime;
Основные функции для работы с датой и временем:
- EXTRACT(): Функция
EXTRACT()позволяет извлекать части даты и времени, такие как год, месяц, день, час и другие. Этот запрос извлекает год из столбцаorder_date.SELECT EXTRACT(YEAR FROM order_date) AS order_year FROM orders; - DATE_TRUNC(): Функция
DATE_TRUNC()используется для обрезания времени и оставления только даты. Этот запрос обрезает время и оставляет только дату.SELECT DATE_TRUNC('day', order_date) AS order_date_truncated FROM orders; - AGE(): Функция
AGE()позволяет вычислить возраст на основе даты рождения и текущей даты. Этот запрос вычисляет возраст сотрудников на основе их даты рождения.SELECT AGE(date_of_birth, CURRENT_DATE) AS age FROM employees; - INTERVAL: Вы можете использовать оператор
INTERVALдля выполнения математических операций с датой и временем. Этот запрос добавляет один день к дате заказа.SELECT order_date + INTERVAL '1 day' AS next_day FROM orders; - TO_CHAR(): Функция
TO_CHAR()используется для форматирования даты и времени в текстовую строку. Этот запрос форматирует дату и время в стандартном для США формате.SELECT TO_CHAR(order_date, 'YYYY-MM-DD HH24:MI:SS') AS formatted_datetime FROM orders; - TIMEZONE(): Функция
TIMEZONE()используется для преобразования времени из одного часового пояса в другой. Этот запрос преобразует время вылета из часового пояса по умолчанию в часовой пояс UTC.SELECT departure_time AT TIME ZONE 'UTC' AS utc_time FROM flights;
Работа с JSON
PostgreSQL предоставляет мощные средства для обработки данных в формате JSON (JavaScript Object Notation). JSON — это легковесный формат для обмена данными, и PostgreSQL предлагает несколько возможностей для работы с JSON-данными.
Вот основные способы обработки данных JSON в PostgreSQL:
- Хранение JSON-данных: PostgreSQL позволяет хранить JSON-данные в столбцах типа
jsonилиjsonb. Типjsonхранит JSON-данные как текст, в то время как типjsonbхранит их в бинарной форме, что делает его более эффективным для поиска и анализа.Пример создания таблицы с JSON-столбцом:CREATE TABLE products ( product_id serial PRIMARY KEY, product_info json ); - Извлечение данных из JSON: Вы можете извлекать значения из JSON-данных с помощью различных операторов и функций. Например, оператор
->позволяет получить значение по ключу из JSON-объекта:SELECT product_info->'name' AS product_name FROM products; - Манипулирование JSON: PostgreSQL предоставляет множество функций для добавления, изменения и удаления данных в JSON-структурах. Например, функция
jsonb_setпозволяет вам изменить значение по ключу:UPDATE products SET product_info = jsonb_set(product_info, '{price}', '"19.99"') WHERE product_id = 1; - Фильтрация с использованием JSON: Вы можете использовать JSON-фильтры в операторе
WHEREдля поиска строк, удовлетворяющих определенным условиям. Например, чтобы найти все продукты с ценой менее $20:SELECT * FROM products WHERE (product_info->>'price')::numeric < 20.00; - Агрегация и анализ JSON: PostgreSQL также предоставляет функции для агрегации и анализа JSON-данных. Например, функция
jsonb_array_elementsпозволяет вам разбить JSON-массив на отдельные элементы для дальнейшей обработки.SELECT jsonb_array_elements(product_info->'features') AS feature FROM products;
Инструкция CASE
Инструкция CASE в SQL (включая PostgreSQL) — это способ сделать условные вычисления в вашем запросе SELECT. Она позволяет вам выполнять разные действия на основе условий, и, таким образом, выбирать разные значения для каждой строки в результате запроса.
Давайте рассмотрим инструкцию CASE на примере:
Предположим, у вас есть таблица employees с информацией о сотрудниках, и вы хотите создать запрос, который добавит столбец position_type, который будет указывать на тип должности сотрудника в зависимости от его зарплаты. Вы хотите классифицировать сотрудников на «Менеджеров», «Обычных сотрудников» и «Стажеров» в зависимости от уровня их зарплаты.
SELECT
employee_id,
first_name,
last_name,
salary,
CASE
WHEN salary >= 60000 THEN 'Менеджер'
WHEN salary >= 40000 THEN 'Обычный сотрудник'
ELSE 'Стажер'
END AS position_type
FROM employees;
В этом примере:
- Мы используем
CASE, чтобы начать условное вычисление. - Затем мы устанавливаем условие, используя
WHEN. Если зарплата сотрудника больше или равна 60000, мы называем его «Менеджером». - Если зарплата находится в диапазоне от 40000 до 59999, мы называем сотрудника «Обычным сотрудником».
- В противном случае (если зарплата меньше 40000), мы называем его «Стажером».
- Мы используем
END, чтобы завершить инструкциюCASE.
Таким образом, в результате запроса появится новый столбец position_type, который указывает на тип должности каждого сотрудника на основе его зарплаты.
Инструкция CASE очень полезна, когда вам нужно создавать вычисляемые столбцы на основе условий.
Практическое задание. ПростойSELECT
Дана база данных:
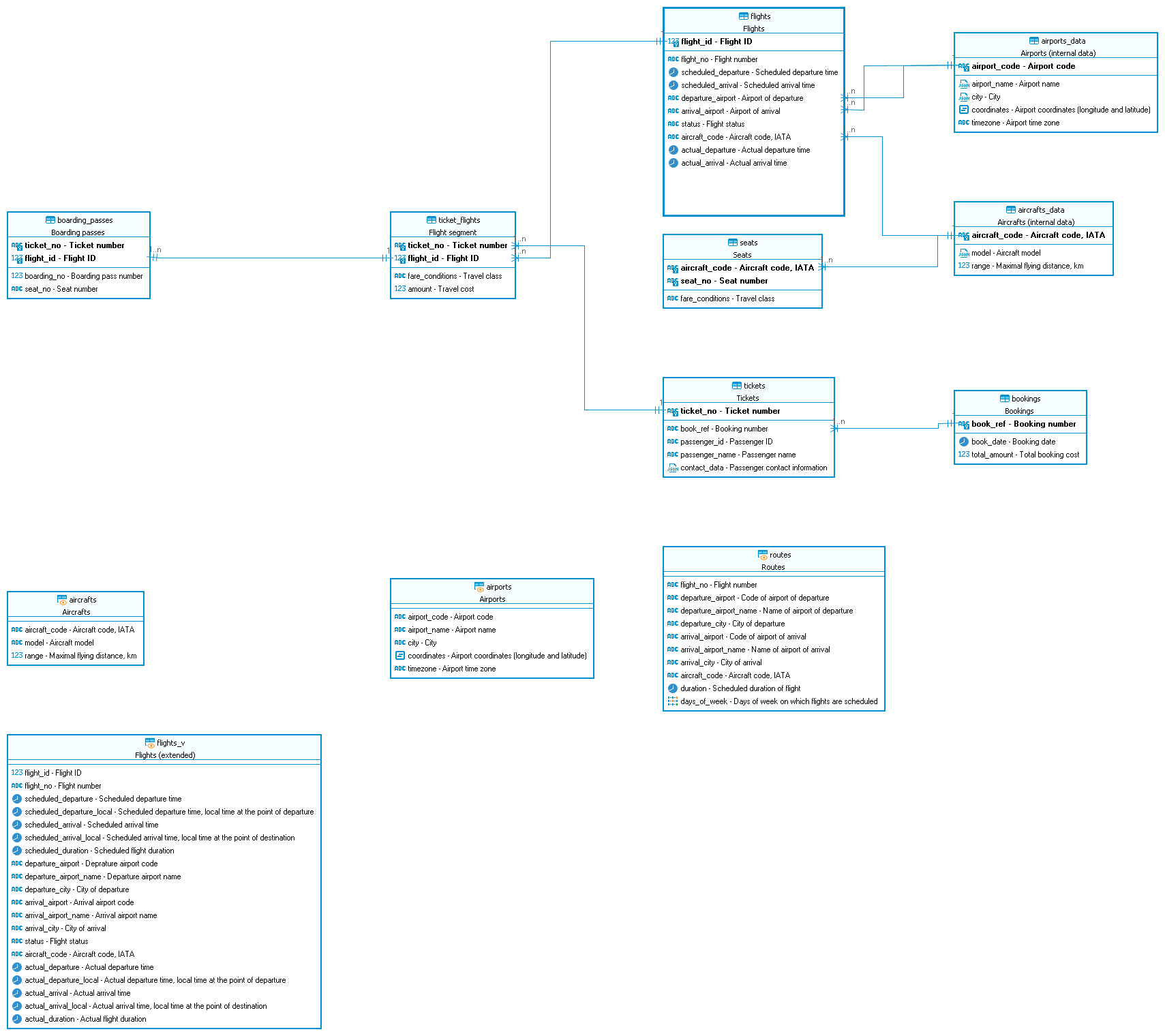
Подробное описание структуры в виде скрипта:
CREATE TABLE aircrafts_data (
aircraft_code bpchar(3) NOT NULL,
model jsonb NOT NULL,
"range" int4 NOT NULL,
CONSTRAINT aircrafts_pkey PRIMARY KEY (aircraft_code),
CONSTRAINT aircrafts_range_check CHECK ((range > 0))
);
CREATE TABLE airports_data (
airport_code bpchar(3) NOT NULL,
airport_name jsonb NOT NULL,
city jsonb NOT NULL,
coordinates point NOT NULL,
timezone text NOT NULL,
CONSTRAINT airports_data_pkey PRIMARY KEY (airport_code)
);
CREATE TABLE bookings (
book_ref bpchar(6) NOT NULL,
book_date timestamptz NOT NULL,
total_amount numeric(10, 2) NOT NULL,
CONSTRAINT bookings_pkey PRIMARY KEY (book_ref)
);
CREATE TABLE flights (
flight_id serial4 NOT NULL,
flight_no bpchar(6) NOT NULL,
scheduled_departure timestamptz NOT NULL,
scheduled_arrival timestamptz NOT NULL,
departure_airport bpchar(3) NOT NULL,
arrival_airport bpchar(3) NOT NULL,
status varchar(20) NOT NULL,
aircraft_code bpchar(3) NOT NULL,
actual_departure timestamptz NULL,
actual_arrival timestamptz NULL,
CONSTRAINT flights_check CHECK ((scheduled_arrival > scheduled_departure)),
CONSTRAINT flights_check1 CHECK (((actual_arrival IS NULL) OR ((actual_departure IS NOT NULL) AND (actual_arrival IS NOT NULL) AND (actual_arrival > actual_departure)))),
CONSTRAINT flights_flight_no_scheduled_departure_key UNIQUE (flight_no, scheduled_departure),
CONSTRAINT flights_pkey PRIMARY KEY (flight_id),
CONSTRAINT flights_status_check CHECK (((status)::text = ANY (ARRAY[('On Time'::character varying)::text, ('Delayed'::character varying)::text, ('Departed'::character varying)::text, ('Arrived'::character varying)::text, ('Scheduled'::character varying)::text, ('Cancelled'::character varying)::text]))),
CONSTRAINT flights_aircraft_code_fkey FOREIGN KEY (aircraft_code) REFERENCES aircrafts_data(aircraft_code),
CONSTRAINT flights_arrival_airport_fkey FOREIGN KEY (arrival_airport) REFERENCES airports_data(airport_code),
CONSTRAINT flights_departure_airport_fkey FOREIGN KEY (departure_airport) REFERENCES airports_data(airport_code)
);
CREATE TABLE seats (
aircraft_code bpchar(3) NOT NULL,
seat_no varchar(4) NOT NULL,
fare_conditions varchar(10) NOT NULL,
CONSTRAINT seats_fare_conditions_check CHECK (((fare_conditions)::text = ANY (ARRAY[('Economy'::character varying)::text, ('Comfort'::character varying)::text, ('Business'::character varying)::text]))),
CONSTRAINT seats_pkey PRIMARY KEY (aircraft_code, seat_no),
CONSTRAINT seats_aircraft_code_fkey FOREIGN KEY (aircraft_code) REFERENCES aircrafts_data(aircraft_code) ON DELETE CASCADE
);
CREATE TABLE tickets (
ticket_no bpchar(13) NOT NULL,
book_ref bpchar(6) NOT NULL,
passenger_id varchar(20) NOT NULL,
passenger_name text NOT NULL,
contact_data jsonb NULL,
CONSTRAINT tickets_pkey PRIMARY KEY (ticket_no),
CONSTRAINT tickets_book_ref_fkey FOREIGN KEY (book_ref) REFERENCES bookings(book_ref)
);
CREATE TABLE ticket_flights (
ticket_no bpchar(13) NOT NULL,
flight_id int4 NOT NULL,
fare_conditions varchar(10) NOT NULL,
amount numeric(10, 2) NOT NULL,
CONSTRAINT ticket_flights_amount_check CHECK ((amount >= (0)::numeric)),
CONSTRAINT ticket_flights_fare_conditions_check CHECK (((fare_conditions)::text = ANY (ARRAY[('Economy'::character varying)::text, ('Comfort'::character varying)::text, ('Business'::character varying)::text]))),
CONSTRAINT ticket_flights_pkey PRIMARY KEY (ticket_no, flight_id),
CONSTRAINT ticket_flights_flight_id_fkey FOREIGN KEY (flight_id) REFERENCES flights(flight_id),
CONSTRAINT ticket_flights_ticket_no_fkey FOREIGN KEY (ticket_no) REFERENCES tickets(ticket_no)
);
CREATE TABLE boarding_passes (
ticket_no bpchar(13) NOT NULL,
flight_id int4 NOT NULL,
boarding_no int4 NOT NULL,
seat_no varchar(4) NOT NULL,
CONSTRAINT boarding_passes_flight_id_boarding_no_key UNIQUE (flight_id, boarding_no),
CONSTRAINT boarding_passes_flight_id_seat_no_key UNIQUE (flight_id, seat_no),
CONSTRAINT boarding_passes_pkey PRIMARY KEY (ticket_no, flight_id),
CONSTRAINT boarding_passes_ticket_no_fkey FOREIGN KEY (ticket_no,flight_id) REFERENCES ticket_flights(ticket_no,flight_id)
);
Эта схема определяет базу данных для управления данными, связанными с рейсами, бронированием, билетами, местами, воздушными судами, аэропортами и посадочными талонами.
aircrafts_data - Воздушные суда:aircraft_code(Первичный ключ): 3-символьный код воздушного судна.model: Данные JSONB для модели воздушного судна.range: Целое число, представляющее дальность воздушного судна.- Ограничения: Первичный ключ на
aircraft_code, ограничение проверки дляrange> 0.
airports_data - Аэропорты:airport_code(Первичный ключ): 3-символьный код аэропорта.airport_name: Данные JSONB для названия аэропорта.city: Данные JSONB для города.coordinates: Данные типа Point для координат аэропорта.timezone: Текстовые данные для часового пояса аэропорта.- Ограничения: Первичный ключ на
airport_code.
bookings - Бронирования:book_ref(Первичный ключ): 6-символьный код бронирования.book_date: Метка времени с часовым поясом для даты бронирования.total_amount: Числовые данные для общей суммы бронирования.- Ограничения: Первичный ключ на
book_ref.
flights - Рейсы:flight_id(Серийный первичный ключ): Автоматически инкрементируемое число для идентификатора рейса.flight_no: 6-символьный номер рейса.scheduled_departure: Метка времени с часовым поясом для запланированного вылета.scheduled_arrival: Метка времени с часовым поясом для запланированного прибытия.departure_airport: 3-символьный код аэропорта вылета.arrival_airport: 3-символьный код аэропорта прибытия.status: Varchar для статуса рейса.aircraft_code: 3-символьный код используемого воздушного судна.actual_departure: Нулевая метка времени для фактического вылета (может быть пустой).actual_arrival: Нулевая метка времени для фактического прибытия (может быть пустой).- Ограничения: Первичный ключ на
flight_id, уникальное ограничение наflight_noиscheduled_departure, внешние ключи дляaircraft_code,arrival_airportиdeparture_airport.
seats - Посадочные места на судне:aircraft_code: 3-символьный код воздушного судна.seat_no: Varchar для номера места.fare_conditions: Varchar для условий тарифа.- Ограничения: Первичный ключ на
aircraft_codeиseat_no, внешний ключ дляaircraft_codeс каскадным удалением.
tickets - Билеты:ticket_no(Первичный ключ): 13-символьный номер билета.book_ref: 6-символьный код бронирования.passenger_id: Varchar для идентификатора пассажира.passenger_name: Текст для имени пассажира.contact_data: Данные JSONB для контактной информации (может быть пустой).- Ограничения: Первичный ключ на
ticket_no, внешний ключ дляbook_ref.
ticket_flights - Билеты на перелет:ticket_no: 13-символьный номер билета.flight_id: Целое число для идентификатора рейса.fare_conditions: Varchar для условий тарифа.amount: Числовые данные для суммы билета.- Ограничения: Первичный ключ на
ticket_noиflight_id, внешние ключи дляflight_idиticket_no.
boarding_passes - Посадочные талоны:ticket_no: 13-символьный номер билета.flight_id: Целое число для идентификатора рейса.boarding_no: Целое число для номера посадки.seat_no: Varchar для номера места.- Ограничения: Первичный ключ на
ticket_noиflight_id, уникальные ограничения наflight_idиboarding_no, иflight_idиseat_no. Внешний ключ дляticket_noиflight_id.
Задание 1: Выберите все записи из таблицы
flightsи выведите только номера рейсов (столбецflight_no) в верхнем регистре.
SELECT UPPER(flight_no)
FROM flights;
Задание 2: Выберите все записи из таблицы
ticketsи выведите первые 10 символов из столбцаticket_noв качестве сокращенных номеров билетов.
SELECT LEFT(ticket_no, 10) AS shortened_ticket_no
FROM tickets;
Задание 3: Выберите все записи из таблицы
airports_dataи выведите только код аэропорта (столбецairport_code) и первые 5 символов из названия аэропорта (столбецairport_name) в верхнем регистре.
SELECT airport_code,
UPPER(LEFT(airport_name::text, 5)) AS shortened_name
FROM airports_data;Задание 4: Выберите все записи из таблицы
bookingsи выведите разницу в днях между текущей датой и датой бронирования (столбецbook_date) для каждой записи.
SELECT book_ref,
current_date - book_date AS days_difference
FROM bookings;
Задание 5: Выберите все записи из таблицы
seatsи выведите столбецfare_conditions, в котором все символы будут в нижнем регистре.
SELECT LOWER(fare_conditions) FROM seats;
Задание 6: Выберите все записи из таблицы
flightsи выведите столбцыflight_noи разницу в минутах между запланированным прибытием (scheduled_arrival) и фактическим прибытием (actual_arrival). Представьте разницу в виде положительных значений, даже если фактическое прибытие было раньше запланированного
SELECT flight_no,
ABS(EXTRACT(EPOCH FROM actual_arrival - scheduled_arrival) / 60) AS arrival_delay_minutes
FROM flights;
Задание 7: Выберите все записи из таблицы
bookingsи выведите столбцыbook_refи разницу в днях между датой бронирования (book_date) и текущей датой. Если бронирование было сделано в будущем, то разницу следует представить как отрицательное значение.
SELECT book_ref, current_date - book_date AS days_difference
FROM bookings;
Задание 8: Выберите все записи из таблицы
ticket_flightsи выведите столбцыticket_noи сумму (amount) билета с добавленной налоговой ставкой в размере 10%. Округлите полученную сумму до двух десятичных знаков.
SELECT ticket_no,
ROUND(amount * 1.10, 2) AS total_amount_with_tax
FROM ticket_flights;
Задание 9: Выберите все записи из таблицы
flightsи выведите столбцыflight_no,scheduled_departureи статус выполнения вылета (по расписанию или с задержкой). Еслиactual_departureимеет значение NULL, выведите «По расписанию,» в противном случае, выведите «С задержкой».
SELECT flight_no, scheduled_departure,
CASE
WHEN actual_departure IS NULL THEN 'По расписанию'
ELSE 'С задержкой'
END AS departure_status
FROM flights;
Задание 10: Выберите все записи из таблицы
flightsи выведите столбцыflight_no,scheduled_departure, иactual_departure. Еслиactual_departureимеет значение NULL, выведите «По расписанию,» в противном случае, выведите фактическое время вылета. В этом задании используйте функциюCOALESCEдля отображения «По расписанию» вместо NULL.
SELECT flight_no,
scheduled_departure,
COALESCE(actual_departure, 'По расписанию') AS departure_time
FROM flights;
Задание 11:Выберите все записи из таблицы
airports_dataи выведите английские названия аэропортов (по ключу «en» в JSON-полеairport_name). Преобразуйте результат в верхний регистр и получите 5 первых символов название и функциюLEFTдля вывода первых 5 символов каждого названия.
SELECT
UPPER((airport_name->>'en')) AS english_name,
LEFT(UPPER((airport_name->>'en')), 5) AS abbreviated_name
FROM airports_data;
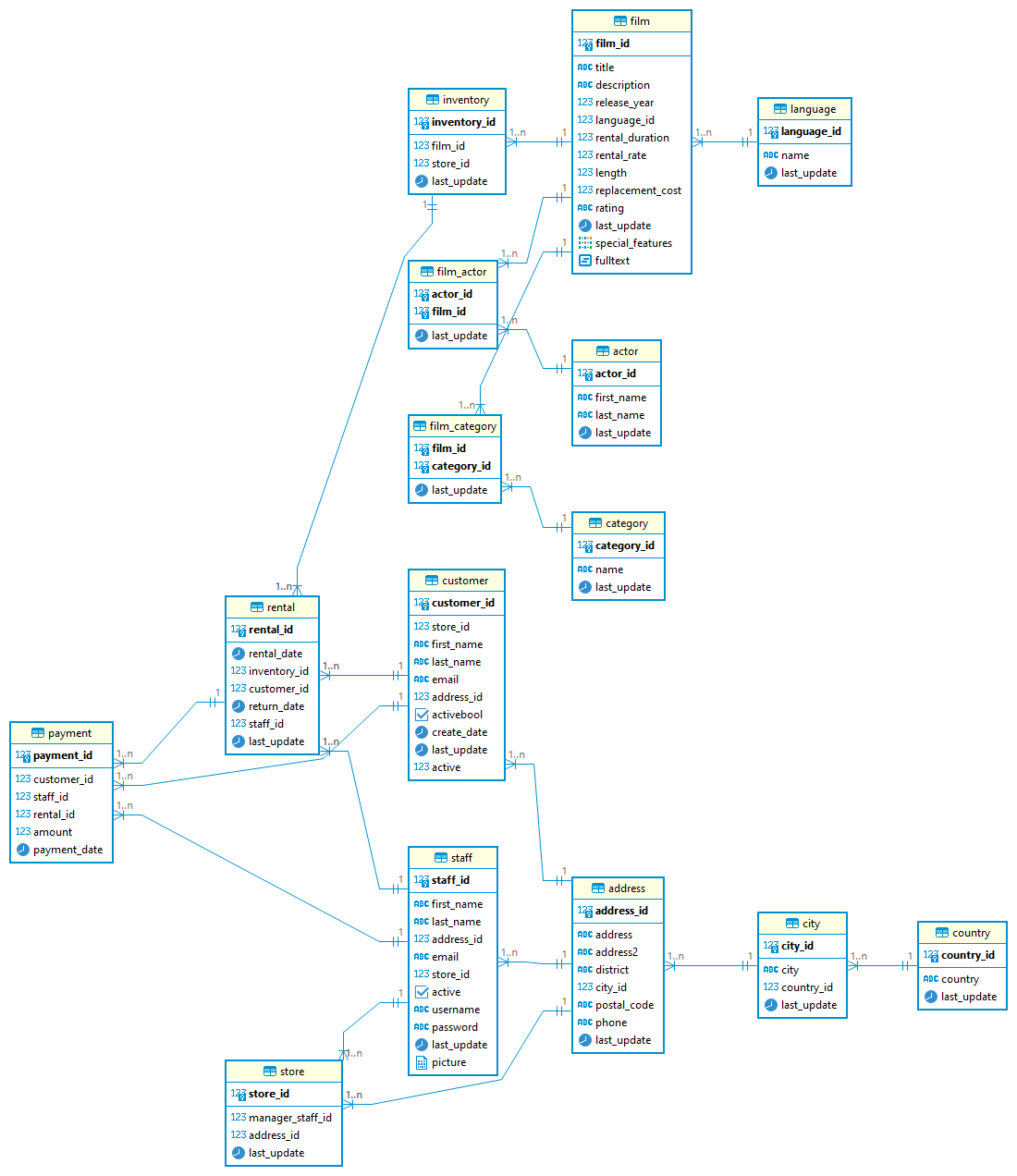
База данных №2. Прокат дисков.
Диаграмма БД
CREATE TABLE actor (
actor_id serial4 NOT NULL,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT actor_pkey PRIMARY KEY (actor_id)
);
CREATE TABLE category (
category_id serial4 NOT NULL,
"name" varchar(25) NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT category_pkey PRIMARY KEY (category_id)
);
CREATE TABLE country (
country_id serial4 NOT NULL,
country varchar(50) NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT country_pkey PRIMARY KEY (country_id)
);
CREATE TABLE "language" (
language_id serial4 NOT NULL,
"name" bpchar(20) NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT language_pkey PRIMARY KEY (language_id)
);
CREATE TABLE city (
city_id serial4 NOT NULL,
city varchar(50) NOT NULL,
country_id int2 NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT city_pkey PRIMARY KEY (city_id),
CONSTRAINT fk_city FOREIGN KEY (country_id) REFERENCES country(country_id)
);
CREATE TABLE film (
film_id serial4 NOT NULL,
title varchar(255) NOT NULL,
description text NULL,
release_year public."year" NULL,
language_id int2 NOT NULL,
rental_duration int2 NOT NULL DEFAULT 3,
rental_rate numeric(4, 2) NOT NULL DEFAULT 4.99,
length int2 NULL,
replacement_cost numeric(5, 2) NOT NULL DEFAULT 19.99,
rating public.mpaa_rating NULL DEFAULT 'G'::mpaa_rating,
last_update timestamp NOT NULL DEFAULT now(),
special_features _text NULL,
fulltext tsvector NOT NULL,
CONSTRAINT film_pkey PRIMARY KEY (film_id),
CONSTRAINT film_language_id_fkey FOREIGN KEY (language_id) REFERENCES "language"(language_id) ON DELETE RESTRICT ON UPDATE CASCADE
);
CREATE TABLE film_actor (
actor_id int2 NOT NULL,
film_id int2 NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT film_actor_pkey PRIMARY KEY (actor_id, film_id),
CONSTRAINT film_actor_actor_id_fkey FOREIGN KEY (actor_id) REFERENCES actor(actor_id) ON DELETE RESTRICT ON UPDATE CASCADE,
CONSTRAINT film_actor_film_id_fkey FOREIGN KEY (film_id) REFERENCES film(film_id) ON DELETE RESTRICT ON UPDATE CASCADE
);
CREATE TABLE film_category (
film_id int2 NOT NULL,
category_id int2 NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT film_category_pkey PRIMARY KEY (film_id, category_id),
CONSTRAINT film_category_category_id_fkey FOREIGN KEY (category_id) REFERENCES category(category_id) ON DELETE RESTRICT ON UPDATE CASCADE,
CONSTRAINT film_category_film_id_fkey FOREIGN KEY (film_id) REFERENCES film(film_id) ON DELETE RESTRICT ON UPDATE CASCADE
);
CREATE TABLE inventory (
inventory_id serial4 NOT NULL,
film_id int2 NOT NULL,
store_id int2 NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT inventory_pkey PRIMARY KEY (inventory_id),
CONSTRAINT inventory_film_id_fkey FOREIGN KEY (film_id) REFERENCES film(film_id) ON DELETE RESTRICT ON UPDATE CASCADE
);
CREATE TABLE address (
address_id serial4 NOT NULL,
address varchar(50) NOT NULL,
address2 varchar(50) NULL,
district varchar(20) NOT NULL,
city_id int2 NOT NULL,
postal_code varchar(10) NULL,
phone varchar(20) NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT address_pkey PRIMARY KEY (address_id),
CONSTRAINT fk_address_city FOREIGN KEY (city_id) REFERENCES city(city_id)
);
CREATE TABLE customer (
customer_id serial4 NOT NULL,
store_id int2 NOT NULL,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
email varchar(50) NULL,
address_id int2 NOT NULL,
activebool bool NOT NULL DEFAULT true,
create_date date NOT NULL DEFAULT 'now'::text::date,
last_update timestamp NULL DEFAULT now(),
active int4 NULL,
CONSTRAINT customer_pkey PRIMARY KEY (customer_id),
CONSTRAINT customer_address_id_fkey FOREIGN KEY (address_id) REFERENCES address(address_id) ON DELETE RESTRICT ON UPDATE CASCADE
);
CREATE TABLE staff (
staff_id serial4 NOT NULL,
first_name varchar(45) NOT NULL,
last_name varchar(45) NOT NULL,
address_id int2 NOT NULL,
email varchar(50) NULL,
store_id int2 NOT NULL,
active bool NOT NULL DEFAULT true,
username varchar(16) NOT NULL,
"password" varchar(40) NULL,
last_update timestamp NOT NULL DEFAULT now(),
picture bytea NULL,
CONSTRAINT staff_pkey PRIMARY KEY (staff_id),
CONSTRAINT staff_address_id_fkey FOREIGN KEY (address_id) REFERENCES address(address_id) ON DELETE RESTRICT ON UPDATE CASCADE
);
CREATE TABLE store (
store_id serial4 NOT NULL,
manager_staff_id int2 NOT NULL,
address_id int2 NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT store_pkey PRIMARY KEY (store_id),
CONSTRAINT store_address_id_fkey FOREIGN KEY (address_id) REFERENCES address(address_id) ON DELETE RESTRICT ON UPDATE CASCADE,
CONSTRAINT store_manager_staff_id_fkey FOREIGN KEY (manager_staff_id) REFERENCES staff(staff_id) ON DELETE RESTRICT ON UPDATE CASCADE
);
CREATE TABLE rental (
rental_id serial4 NOT NULL,
rental_date timestamp NOT NULL,
inventory_id int4 NOT NULL,
customer_id int2 NOT NULL,
return_date timestamp NULL,
staff_id int2 NOT NULL,
last_update timestamp NOT NULL DEFAULT now(),
CONSTRAINT rental_pkey PRIMARY KEY (rental_id),
CONSTRAINT rental_customer_id_fkey FOREIGN KEY (customer_id) REFERENCES customer(customer_id) ON DELETE RESTRICT ON UPDATE CASCADE,
CONSTRAINT rental_inventory_id_fkey FOREIGN KEY (inventory_id) REFERENCES inventory(inventory_id) ON DELETE RESTRICT ON UPDATE CASCADE,
CONSTRAINT rental_staff_id_key FOREIGN KEY (staff_id) REFERENCES staff(staff_id)
);
CREATE TABLE payment (
payment_id serial4 NOT NULL,
customer_id int2 NOT NULL,
staff_id int2 NOT NULL,
rental_id int4 NOT NULL,
amount numeric(5, 2) NOT NULL,
payment_date timestamp NOT NULL,
CONSTRAINT payment_pkey PRIMARY KEY (payment_id),
CONSTRAINT payment_customer_id_fkey FOREIGN KEY (customer_id) REFERENCES customer(customer_id) ON DELETE RESTRICT ON UPDATE CASCADE,
CONSTRAINT payment_rental_id_fkey FOREIGN KEY (rental_id) REFERENCES rental(rental_id) ON DELETE SET NULL ON UPDATE CASCADE,
CONSTRAINT payment_staff_id_fkey FOREIGN KEY (staff_id) REFERENCES staff(staff_id) ON DELETE RESTRICT ON UPDATE CASCADE
);
- Таблица «actor» (Актеры):
- actor_id (идентификатор актера)
- first_name (имя актера)
- last_name (фамилия актера)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поле actor_id
- Таблица «category» (Категории):
- category_id (идентификатор категории)
- «name» (название категории)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поле category_id
- Таблица «country» (Страны):
- country_id (идентификатор страны)
- country (название страны)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поле country_id
- Таблица «language» (Языки):
- language_id (идентификатор языка)
- «name» (название языка)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поле language_id
- Таблица «city» (Города):
- city_id (идентификатор города)
- city (название города)
- country_id (идентификатор страны, к которой относится город)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поле city_id
- Ограничение FOREIGN KEY на поле country_id, связанное с таблицей «country»
- Таблица «film» (Фильмы):
- film_id (идентификатор фильма)
- title (название фильма)
- description (описание фильма)
- release_year (год выпуска фильма)
- language_id (идентификатор языка фильма)
- rental_duration (длительность аренды фильма)
- rental_rate (стоимость аренды фильма)
- length (длительность фильма)
- replacement_cost (стоимость замены фильма)
- rating (рейтинг фильма)
- last_update (дата последнего обновления записи)
- special_features (особенности фильма)
- fulltext (полнотекстовый поиск фильма)
- Ограничение PRIMARY KEY на поле film_id
- Ограничение FOREIGN KEY на поле language_id, связанное с таблицей «language»
- Таблица «film_actor» (Связь между актерами и фильмами):
- actor_id (идентификатор актера)
- film_id (идентификатор фильма)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поля actor_id и film_id
- Ограничения FOREIGN KEY на поля actor_id и film_id, связанные с таблицами «actor» и «film»
- Таблица «film_category» (Связь между фильмами и категориями):
- film_id (идентификатор фильма)
- category_id (идентификатор категории)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поля film_id и category_id
- Ограничения FOREIGN KEY на поля category_id и film_id, связанные с таблицами «category» и «film»
- Таблица «inventory» (Инвентарь фильмов):
- inventory_id (идентификатор инвентаря)
- film_id (идентификатор фильма)
- store_id (идентификатор магазина)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поле inventory_id
- Ограничение FOREIGN KEY на поле film_id, связанное с таблицей «film»
- Таблица «address» (Адреса):
- address_id (идентификатор адреса)
- address (адрес)
- address2 (дополнительный адрес)
- district (район)
- city_id (идентификатор города, к которому относится адрес)
- postal_code (почтовый индекс)
- phone (телефон)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поле address_id
- Ограничение FOREIGN KEY на поле city_id, связанное с таблицей «city»
- Таблица «customer» (Клиенты):
- customer_id (идентификатор клиента)
- store_id (идентификатор магазина)
- first_name (имя клиента)
- last_name (фамилия клиента)
- email (электронная почта клиента)
- address_id (идентификатор адреса клиента)
- activebool (флаг активности клиента)
- create_date (дата создания клиента)
- last_update (дата последнего обновления записи)
- active (статус активности клиента)
- Ограничение PRIMARY KEY на поле customer_id
- Ограничение FOREIGN KEY на поле address_id, связанное с таблицей «address»
- Таблица «staff» (Сотрудники):
- staff_id (идентификатор сотрудника)
- first_name (имя сотрудника)
- last_name (фамилия сотрудника)
- address_id (идентификатор адреса сотрудника)
- email (электронная почта сотрудника)
- store_id (идентификатор магазина)
- active (флаг активности сотрудника)
- username (имя пользователя)
- «password» (пароль)
- last_update (дата последнего обновления записи)
- picture (фотография сотрудника)
- Ограничение PRIMARY KEY на поле staff_id
- Ограничение FOREIGN KEY на поле address_id, связанное с таблицей «address»
- Таблица «store» (Магазины):
- store_id (идентификатор магазина)
- manager_staff_id (идентификатор управляющего магазином)
- address_id (идентификатор адреса магазина)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поле store_id
- Ограничения FOREIGN KEY на поля address_id и manager_staff_id, связанные с таблицами «address» и «staff»
- Таблица «rental» (Аренда фильмов):
- rental_id (идентификатор аренды)
- rental_date (дата аренды)
- inventory_id (идентификатор инвентаря)
- customer_id (идентификатор клиента)
- return_date (дата возврата)
- staff_id (идентификатор сотрудника)
- last_update (дата последнего обновления записи)
- Ограничение PRIMARY KEY на поле rental_id
- Ограничения FOREIGN KEY на поля customer_id, inventory_id и staff_id, связанные с таблицами «customer», «inventory» и «staff»
- Таблица «payment» (Платежи):
- payment_id (идентификатор платежа)
- customer_id (идентификатор клиента)
- staff_id (идентификатор сотрудника)
- rental_id (идентификатор аренды)
- amount (сумма платежа)
- payment_date (дата платежа)
- Ограничение PRIMARY KEY на поле payment_id
- Ограничения FOREIGN KEY на поля customer_id, rental_id и staff_id, связанные с таблицами «customer», «rental» и «staff»
Задание 11: Выберите все фильмы (таблица «film»), но ограничьтесь только первыми 10 записями. Отсортируйте их по названию фильма в алфавитном порядке.
SELECT * FROM film
ORDER BY title
LIMIT 10;
Задание 12: Выведите список всех языков (таблица «language») в формате «Язык: [название языка]».
SELECT 'Язык: ' || "name" AS language_info
FROM "language";
Задание 13: Получите сумму всех платежей (таблица «payment») и округлите результат до двух знаков после запятой.
SELECT ROUND(SUM(amount), 2) AS total_payments
FROM payment;
Задание 14: Найдите актеров (таблица «actor»), чьи имена содержат букву ‘a’ и фамилии содержат букву ‘e’. Выведите их имена и фамилии.
SELECT first_name,
last_name
FROM actor
WHERE first_name LIKE '%a%'
AND last_name LIKE '%e%';
Задание 15: Выведите текущую дату и время в формате ‘ГГГГ-ММ-ДД ЧЧ:ММ:СС’.
SELECT TO_CHAR(NOW(), 'YYYY-MM-DD HH24:MI:SS') AS current_datetime;
Инструкция WHERE . Фильтрация данных с помощью SQL
Инструкция WHERE в SQL используется для фильтрации строк в результатах запроса. Это означает, что вы можете использовать WHERE, чтобы выбрать только те строки, которые соответствуют определенным условиям. Вот как это работает:
- Операторы сравнения: С помощью
WHEREвы можете сравнивать значения в столбцах с определенными значениями. Например, вы можете выбрать все строки, где значение в столбце «возраст» больше 30. В этом примереage > 30— это условие, иWHEREвыбирает только те строки, для которых оно истинно.SELECT * FROM employees WHERE age > 30; - Логические операторы: Вы можете комбинировать несколько условий с использованием логических операторов, таких как
AND,OR, иNOT. Например, вы можете выбрать всех сотрудников, чей возраст больше 30 и которые работают в отделе продаж. В этом примере мы используемAND, чтобы объединить два условия.SELECT * FROM employees WHERE age > 30 AND department = 'Продажи'; - Другие операторы: Вы также можете использовать операторы, такие как
IN,BETWEEN, иLIKE, чтобы фильтровать данные. Например, вы можете выбрать всех сотрудников, чьи имена начинаются с буквы «А» или «В». Здесь мы используемLIKEдля поиска имен, начинающихся с определенных букв.SELECT * FROM employees WHERE first_name LIKE 'А%' OR first_name LIKE 'В%'; - Функции и подзапросы в логических выражениях: Вы также можете использовать функции в логических выражениях, чтобы более сложно фильтровать данные. Например, вы можете выбрать всех сотрудников, чья зарплата больше средней зарплаты в компании:
SELECT * FROM employees WHERE salary > (SELECT AVG(salary) FROM employees);
Операторы сравнения
Операторы сравнения в SQL используются для сравнения значений в столбцах с определенными условиями. Они позволяют выбирать строки из таблицы, которые соответствуют заданным критериям.
- Оператор равенства (
=): Используется для сравнения двух значений. Например, чтобы выбрать всех сотрудников с именем «Анна», вы можете написать:SELECT * FROM employees WHERE first_name = 'Анна'; - Оператор неравенства (
<>или!=): Используется для проверки, что значение не равно заданному. Например, чтобы выбрать всех сотрудников, у которых не имя «Петр», вы можете написать:SELECT * FROM employees WHERE first_name <> 'Петр'; - Оператор больше (
>): Используется для сравнения числовых значений. Например, чтобы выбрать всех сотрудников с возрастом старше 30 лет:SELECT * FROM employees WHERE age > 30; - Оператор меньше (
<): Используется для сравнения числовых значений. Например, чтобы выбрать всех сотрудников с зарплатой меньше $50000:SELECT * FROM employees WHERE salary < 50000; - Оператор больше или равно (
>=) и меньше или равно (<=): Используются для сравнения числовых значений с учетом равенства. Например, чтобы выбрать всех сотрудников с возрастом 30 лет и старше:SELECT * FROM employees WHERE age >= 30; - Или чтобы выбрать всех сотрудников с зарплатой не более $60000:
SELECT * FROM employees WHERE salary <= 60000;
Эти операторы сравнения позволяют вам фильтровать данные в таблице, выбирая только те строки, которые соответствуют заданным условиям.
Логические операторы
Логические операторы в SQL позволяют комбинировать условия в операторе WHERE для создания более сложных запросов. Вот несколько основных логических операторов и их использование:
- Оператор «И» (
AND): Этот оператор используется, чтобы проверить, выполняются ли оба условия. Если оба условия истинны, то строка будет включена в результат. Пример: Выбрать всех сотрудников с именем «Анна» и возрастом старше 30 лет.SELECT * FROM employees WHERE first_name = 'Анна' AND age > 30; - Оператор «ИЛИ» (
OR): Этот оператор используется, чтобы проверить, выполняется ли хотя бы одно из условий. Если хотя бы одно из условий истинно, то строка будет включена в результат. Пример: Выбрать всех сотрудников с именем «Анна» или с возрастом старше 30 лет.SELECT * FROM employees WHERE first_name = 'Анна' OR age > 30; - Оператор «НЕ» (
NOT): Этот оператор используется, чтобы инвертировать условие. Он делает условие ложным, если оно было истинным, и наоборот. Пример: Выбрать всех сотрудников, у которых не имя «Петр».SELECT * FROM employees WHERE NOT first_name = 'Петр'; - Скобки: Вы можете использовать скобки для управления порядком выполнения условий и создания более сложных логических выражений. Пример: Выбрать всех сотрудников, у которых имя «Анна» и возраст больше 30 лет, или имя «Петр» и зарплата больше $50000.
SELECT * FROM employees WHERE (first_name = 'Анна' AND age > 30) OR (first_name = 'Петр' AND salary > 50000);
Логические операторы позволяют вам создавать более сложные условия в операторе WHERE, что делает ваши запросы более гибкими и позволяет выбирать только те данные, которые соответствуют заданным критериям.
Оператор IN
Оператор IN в SQL используется для фильтрации строк в операторе WHERE, когда вы хотите выбрать строки, чье значение в столбце соответствует одному из списка значений. Это удобно, когда вы хотите выбрать строки, где значение в столбце соответствует одному из нескольких возможных вариантов.
- Простой пример с числами: Выберем всех сотрудников с номером отдела 101 или 102. Этот запрос выберет все строки, где
department_idравен 101 или 102.SELECT * FROM employees WHERE department_id IN (101, 102); - Пример с текстовыми значениями: Выберем всех сотрудников с должностью «Менеджер» или «Специалист»:
SELECT * FROM employees WHERE job_title IN ('Менеджер', 'Специалист'); - Пример с подзапросом: Выберем всех сотрудников, у которых
department_idсоответствует какому-то подзапросу. В этом примереINиспользуется с подзапросом для выбора всех отделов в Нью-Йорке и затем выбора сотрудников из этих отделов.SELECT * FROM employees WHERE department_id IN ( SELECT department_id FROM departments WHERE location = 'Нью-Йорк' );
Оператор IN позволяет вам легко выбирать данные, когда у вас есть список значений, с которыми вы хотите сравнить значение в столбце. Это удобно и сокращает количество кода, который вам нужно писать, чтобы создать такие запросы.
Оператор BETWEEN
Оператор BETWEEN в SQL используется для фильтрации строк в операторе WHERE, когда вы хотите выбрать строки, чье значение в столбце находится в заданном диапазоне. Это удобно, когда вы хотите выбрать строки, где значение в столбце находится между двумя другими значениями.
- Простой пример с числами: Выберем всех сотрудников с возрастом от 25 до 35 лет. Этот запрос выберет все строки, где
ageнаходится в диапазоне от 25 до 35 лет.SELECT * FROM employees WHERE age BETWEEN 25 AND 35; - Пример с датами: Выберем все заказы, сделанные с 1 января 2023 года по 31 декабря 2023 года
SELECT * FROM orders WHERE order_date BETWEEN '2023-01-01' AND '2023-12-31'; - Пример с текстовыми значениями: Выберем всех сотрудников с именем, начинающимся с буквы «А», «Б» или «В»
SELECT * FROM employees WHERE first_name BETWEEN 'А' AND 'В';
В случае использования оператора
BETWEEN, значения, указанные в диапазоне, включаются в результат. Это означает, что значения на границах диапазона также учитываются.
Оператор BETWEEN позволяет вам удобно выбирать данные в заданном диапазоне значений. Он может использоваться с числами, датами, текстовыми значениями и другими типами данных.
Оператор LIKE
Оператор LIKE в SQL используется для фильтрации строк в операторе WHERE, когда вы хотите выбрать строки, которые соответствуют определенному шаблону. Он особенно полезен для поиска текстовых данных, когда точное совпадение необязательно.
Оператор LIKE позволяет вам искать строки, которые соответствуют определенному шаблону, используя символы % для обозначения «ноль или более символов» и символ _ для обозначения «одного символа».
- Пример совпадения начала строки: Выберем всех сотрудников, имена которых начинаются с буквы «А». Здесь символ
%после буквы «А» означает «ноль или более символов». Этот запрос выберет всех сотрудников, у которыхfirst_nameначинается с буквы «А».SELECT * FROM employees WHERE first_name LIKE 'А%'; - Пример совпадения конца строки: Выберем всех сотрудников, фамилии которых заканчиваются на «ов». Здесь
%перед «ов» означает «ноль или более символов». Этот запрос выберет всех сотрудников, у которыхlast_nameзаканчивается на «ов».SELECT * FROM employees WHERE last_name LIKE '%ов'; - Пример поиска подстроки: Выберем всех сотрудников, у которых в имени есть подстрока «ле». Здесь
%как перед «ле», так и после «ле» означает «ноль или более символов». Этот запрос выберет всех сотрудников, у которыхfirst_nameсодержит подстроку «ле».SELECT * FROM employees WHERE first_name LIKE '%ле%'; - Пример совпадения отдельного символа: Выберем всех сотрудников, у которых имя начинается с «А», а вторая буква — «н» (например, «Анна»). Здесь мы явно указываем «н» вторым символом. Этот запрос выберет всех сотрудников, у которых
first_nameначинается с «Ан».SELECT * FROM employees WHERE first_name LIKE 'Ан%';
Задания на закрепление WHERE
Схема «Бронирования перелетов». Описание здесь.
Задание 16: Выберите все записи из таблицы
flights, где статус рейса (status) — «On Time» (по времени) или «Scheduled» (запланирован).
SELECT *
FROM flights
WHERE status IN ('On Time', 'Scheduled');
Задание 17: Выберите все записи из таблицы
aircrafts_data, где дальность полета (range) превышает 5000 км.
SELECT *
FROM aircrafts_data
WHERE range > 5000;
Задание 18: Выберите все записи из таблицы
airports_data, где часовой пояс (timezone) — «UTC+3».
SELECT *
FROM airports_data
WHERE timezone = 'UTC+3';
Задание 19: Выберите все записи из таблицы
seats, где условия тарифа (fare_conditions) — «Business».
SELECT *
FROM seats
WHERE fare_conditions = 'Business';
Задание 20:Выберите все записи из таблицы
flights, где фактическое время прибытия (actual_arrival) отсутствует (NULL), что означает, что рейс еще не завершен.
SELECT *
FROM flights
WHERE actual_arrival IS NULL;
Схема «Прокат дисков». Описание здесь.
Задание 21: Найдите все фильмы (таблица «film»), выпущенные после 2010 года.
SELECT *
FROM film
WHERE release_year > 2010;
Задание 22:Выведите список всех актеров (таблица «actor»), чьи фамилии начинаются с буквы ‘S’.
SELECT *
FROM actor
WHERE last_name LIKE 'S%';
Задание 23: Найдите все платежи (таблица «payment»), совершенные клиентом с идентификатором 15.
SELECT *
FROM payment
WHERE customer_id = 15;
Задание 24: Выведите список городов (таблица «city»), расположенных в стране с названием ‘USA’.
SELECT *
FROM city
WHERE country_id =
(
SELECT country_id
FROM country
WHERE country = 'USA'
);
Задание 25: Найдите всех клиентов (таблица «customer»), активных на момент текущей даты.
SELECT * FROM customer
WHERE create_date <= NOW()
AND
(last_update IS NULL
OR last_update >= NOW());
Подведение итогов. Операторы GROUP BY и HAVING.
Группировка и подведение итогов в SQL используются для агрегации данных и получения суммарных результатов на основе групп элементов. Давайте рассмотрим основные концепции и синтаксис группировки:
Зачем нужна группировка?
Группировка пригодна, когда у вас есть множество данных, и вы хотите сгруппировать их по какому-то критерию, например, по значениям в определенном столбце. Затем, к этим группам, можно применить агрегатные функции, такие как сумма, среднее, минимум, максимум и другие, чтобы получить обобщенные результаты.
Синтаксис группировки:
SELECT
column1,
column2,
aggregate_function(column3) AS result_column
FROM
table_name
GROUP BY
column1, column2;
Пример:
Предположим, у нас есть таблица orders с колонками customer_id, product, и quantity, и мы хотим посчитать общее количество проданных продуктов для каждого клиента:
SELECT
customer_id,
SUM(quantity) AS total_quantity
FROM
orders
GROUP BY
customer_id;
В этом запросе:
customer_idявляется полем группировки.SUM(quantity)— это агрегатная функция, которая суммирует количество для каждого клиента.- Результаты будут сгруппированы по
customer_id, и для каждой группы будет подсчитана суммаquantity.
Полезные дополнения:
HAVING: Оператор
HAVINGиспользуется послеGROUP BYдля фильтрации результатов группировки на основе агрегатных функций. Например, вы можете использовать его для выбора только тех групп, у которых сумма больше определенного значения.
Выражения в SELECT без GROUP BY: В стандартном SQL, если в SELECT-части есть выражения, которых нет в GROUP BY или агрегатных функциях, это вызовет ошибку. Однако, в некоторых базах данных (например, PostgreSQL), это можно сделать с использованием расширенного синтаксиса.
Пример использования HAVING:
SELECT
customer_id,
SUM(quantity) AS total_quantity
FROM
orders
GROUP BY
customer_id
HAVING
SUM(quantity) > 10;
Этот запрос выберет только те группы, у которых общее количество проданных продуктов превышает 10.
Что произойдет, если в SELECT-части есть выражения, которых нет в GROUP BY или агрегатных функциях?
В стандартном SQL, когда используется оператор GROUP BY, все столбцы, указанные в SELECT-части, должны быть либо частью списка группировки (в GROUP BY), либо агрегированы с использованием агрегатных функций. Если это правило нарушается, то запрос может вызвать ошибку.
Давайте рассмотрим пример:
-- Неправильный запрос
SELECT
department,
employee_name,
MAX(salary)
FROM
employees
GROUP BY
department;
В этом запросе employee_name не входит в список группировки и не агрегировано, что может вызвать ошибку в стандартном SQL.
Задания на закрепление.
БД №1. Перелёты, бронирования. Ссылка на описание.
Задание 26: Вычислить среднюю дальность полета (
range) для каждой модели воздушного судна. Вывести только те модели, у которых средняя дальность полета превышает 6000 км.
SELECT model->>'en' AS aircraft_model, AVG(range) AS avg_range
FROM aircrafts_data
GROUP BY aircraft_model
HAVING AVG(range) > 6000;
Задание 27: Для каждого аэропорта вывести общее количество рейсов, отправляющихся и прибывающих. Учитывать только те аэропорты, где общее количество рейсов превышает 50.
SELECT departure_airport AS airport_code, COUNT(*) AS total_departures,
arrival_airport AS airport_code, COUNT(*) AS total_arrivals
FROM flights
GROUP BY departure_airport, arrival_airport
HAVING COUNT(*) > 50;
Задание 28: Для каждого борта вывести общее количество занятых мест в каждом из классов (Economy, Comfort, Business). Учитывать только те борта, где общее количество занятых мест превышает 200.
SELECT aircraft_code, fare_conditions, COUNT(*) AS total_seats
FROM seats
GROUP BY aircraft_code, fare_conditions
HAVING COUNT(*) > 200;
Задание 29: Для каждой даты бронирования вывести количество совершенных бронирований и общую сумму затраченных средств. Учитывать только те даты, где общая сумма превышает 10000.
SELECT book_date, COUNT(*) AS total_bookings, SUM(total_amount) AS total_spent
FROM bookings
GROUP BY book_date
HAVING SUM(total_amount) > 10000;
Задание 30: Для каждого статуса рейса вывести общее количество рейсов и среднюю задержку в минутах. Учитывать только те статусы, где средняя задержка превышает 10 минут.
SELECT status, COUNT(*) AS total_flights, AVG(EXTRACT(EPOCH FROM actual_arrival - scheduled_arrival) / 60) AS avg_delay
FROM flights
GROUP BY status
HAVING AVG(EXTRACT(EPOCH FROM actual_arrival - scheduled_arrival) / 60) > 10;
БД №2 (прокат). Ссылка на описание.
Задание 31: напишите запрос для определения количества фильмов в каждой категории. Выведите идентификатор категории и количество фильмов в каждой категории.
SELECT category_id, COUNT(*) AS film_count
FROM film_category
GROUP BY category_id;Задание 32: напишите запрос для определения средней длительности фильмов по годам выпуска. Выведите год выпуска и среднюю длительность фильмов, но покажите только те годы, в которых средняя длительность фильмов превышает 120 минут.
SELECT release_year, AVG(length) AS average_duration
FROM film
GROUP BY release_year
HAVING AVG(length) > 120;
Задание 33: Напишите запрос для подсчета количества фильмов на каждом языке. Выведите идентификатор языка и общее количество фильмов на каждом языке.
SELECT language_id, COUNT(*) AS film_count
FROM film
GROUP BY language_id;
Задание 34: Напишите запрос для вычисления средней стоимости аренды фильмов по странам. Выведите название страны и среднюю стоимость аренды, но покажите только те страны, где средняя стоимость аренды менее $3.00.
SELECT c.country, AVG(f.rental_rate) AS average_rental_rate
FROM country c
JOIN city ci ON c.country_id = ci.country_id
JOIN address a ON ci.city_id = a.city_id
JOIN customer cu ON a.address_id = cu.address_id
JOIN rental r ON cu.customer_id = r.customer_id
JOIN inventory i ON r.inventory_id = i.inventory_id
JOIN film f ON i.film_id = f.film_id
GROUP BY c.country
HAVING AVG(f.rental_rate) < 3.00;
Задание 35: Напишите запрос для вычисления общей суммы платежей по месяцам. Выведите месяц платежа и общую сумму платежей, но покажите только те месяцы, в которых общая сумма платежей превышает $1000.
SELECT EXTRACT(MONTH FROM payment_date) AS payment_month, SUM(amount) AS total_payment
FROM payment
GROUP BY payment_month
HAVING SUM(amount) > 1000;
Сортировка данных. ORDER BY
Сортировка данных в SQL выполняется с использованием оператора ORDER BY. Этот оператор используется для упорядочивания результирующего набора данных в запросе.
Зачем нужна сортировка?
Сортировка позволяет упорядочить результаты запроса в определенном порядке. Это может быть полезным, например, когда вы хотите видеть данные отсортированными по алфавиту, числовому значению, дате или другому критерию.
Синтаксис ORDER BY:
SELECT
column1,
column2,
...
FROM
table_name
ORDER BY
column1 [ASC | DESC], column2 [ASC | DESC], ...;
ASC(по умолчанию) означает сортировку по возрастанию.DESCозначает сортировку по убыванию.
Пример:
SELECT
product_name,
price
FROM
products
ORDER BY
price DESC;
В этом запросе продукты будут отсортированы по цене в порядке убывания (самая дорогая первой).
Дополнительные сведения:
- Множественная сортировка: Вы можете указать несколько столбцов для сортировки, и данные будут упорядочены сначала по первому столбцу, затем по второму и так далее.
SELECT column1, column2, ... FROM table_name ORDER BY column1 [ASC | DESC], column2 [ASC | DESC], ...; - Сортировка по выражениям: Вы можете использовать выражения в ORDER BY, а не только имена столбцов. Например, сортировка по результату арифметического выражения.
SELECT product_name, price, price * 0.8 AS discounted_price FROM products ORDER BY discounted_price DESC; - Порядковый номер столбца: Можно также использовать порядковый номер столбца в ORDER BY.
SELECT product_name, price FROM products ORDER BY 2 DESC;
Сравнение различных типов данных
Сравнение значений различных типов данных в PostgreSQL осуществляется в соответствии с их семантикой.
Числа: Числа сравниваются как обычно: по их числовому значению.
SELECT * FROM numbers ORDER BY column1;
Строки: Строки сравниваются лексикографически (по алфавиту).
SELECT * FROM names ORDER BY column1;
Дата и время: Даты и времена сравниваются по временному порядку.
SELECT * FROM events ORDER BY event_date;
JSON: JSON сравнивается в соответствии с его структурой и значениями. Это сложная тема, так как сравнение зависит от содержания JSON.
SELECT * FROM json_data ORDER BY json_column->>'name';
Географические точки (Point): Точки сравниваются по их координатам.
SELECT * FROM locations ORDER BY point_column;
NULL: Значения NULL не сравниваются, их можно проверить с использованием IS NULL или IS NOT NULL.
SELECT * FROM data WHERE column1 IS NULL;
Составные типы данных: Составные типы данных, такие как массивы или пользовательские типы, сравниваются по их структуре и элементам.
UUID: UUID сравниваются в соответствии с их битовым представлением.
SELECT * FROM uuid_data ORDER BY uuid_column;
SELECT * FROM custom_types ORDER BY array_column[1];
Замечания:
- В PostgreSQL можно определить пользовательские функции сравнения для специфических типов данных.
- Для более сложных типов данных, таких как JSONB, сравнение зависит от их внутренней структуры и содержания.
Создание пользовательской функции для в качестве критерия сортировки
Создадим простую пользовательскую функцию для сравнения строк по их длине и использования этой функции в качестве критерия сортировки
-- Создание функции сравнения для строк по их длине
CREATE OR REPLACE FUNCTION compare_strings_by_length(str1 text, str2 text)
RETURNS integer AS $$
BEGIN
IF LENGTH(str1) < LENGTH(str2) THEN
RETURN -1;
ELSIF LENGTH(str1) = LENGTH(str2) THEN
RETURN 0;
ELSE
RETURN 1;
END IF;
END;
$$ LANGUAGE plpgsql;
-- Пример использования функции сортировки
SELECT
column1
FROM
your_table
ORDER BY
compare_strings_by_length(column1, 'target_string');
В данном примере создается функция compare_strings_by_length, которая принимает две строки и возвращает целое число: -1, если первая строка короче; 0, если строки равной длины; 1, если первая строка длиннее. Затем эта функция используется в качестве критерия сортировки в запросе.
Конструкция CASE в сортировке
Конструкция CASE может использоваться в выражении сортировки (ORDER BY), чтобы определить условия для порядка сортировки. Вот пример:
-- Пример использования CASE в ORDER BY
SELECT
employee_id,
employee_name,
salary,
CASE
WHEN salary > 50000 THEN 'High Salary'
WHEN salary > 30000 THEN 'Medium Salary'
ELSE 'Low Salary'
END AS salary_category
FROM
employees
ORDER BY
CASE
WHEN salary_category = 'High Salary' THEN 1
WHEN salary_category = 'Medium Salary' THEN 2
ELSE 3
END, employee_name;
В этом примере создается столбец salary_category с использованием CASE в предложении SELECT. Затем, в предложении ORDER BY, используется еще одна конструкция CASE для определения порядка сортировки. Сотрудники с высокой зарплатой будут первыми, затем те с средней зарплатой, и наконец, те с низкой зарплатой. Внутри каждой категории сотрудники сортируются по имени.
Задания для тренировки
База1. Полеты.
Задание 36. Отсортировать записи в таблице airports_data по названию аэропорта (на английском) в алфавитном порядке.
SELECT * FROM airports_data
ORDER BY airport_name->>'en';
Задание 37. Отсортировать записи в таблице flights по запланированному времени вылета (scheduled_departure) по возрастанию, а затем по номеру рейса (flight_no) в алфавитном порядке.
SELECT * FROM flights
ORDER BY scheduled_departure ASC, flight_no;
Задание 38. Отсортировать записи в таблице seats по общему количеству мест (total_seats) в каждом борту по убыванию. Вывести только уникальные борты.
SELECT aircraft_code, SUM(COUNT(*)) AS total_seats
FROM seats
GROUP BY aircraft_code
ORDER BY total_seats DESC;
Задание 39. Отсортировать записи в таблице tickets по дате бронирования (book_date) в порядке убывания и вывести только уникальные записи.
SELECT DISTINCT * FROM tickets
ORDER BY book_date DESC;
Задание 40. Отсортировать записи в таблице flights по статусу рейса (status) в алфавитном порядке, при этом статус «On Time» должен идти первым, а затем остальные статусы в алфавитном порядке.
SELECT * FROM flights
ORDER BY
CASE
WHEN status = 'On Time' THEN 1
ELSE 2
END,
status;
База2. Прокат.
Задание 41. Простая сортировка: Выведите все фильмы (таблица «film») в алфавитном порядке по названию.
SELECT * FROM film
ORDER BY title;
Задание 42. Сортировка по нескольким значениям: Выведите фильмы в порядке убывания стоимости аренды, а затем по возрастанию длительности аренды.
SELECT * FROM film
ORDER BY rental_rate DESC, rental_duration;
Задание 43. Сортировка с использованием агрегатных функций: Выведите список языков (таблица «language») в порядке убывания количества фильмов на каждом языке.
SELECT l.language_id, l."name", COUNT(f.film_id) AS film_count
FROM language l
JOIN film f ON l.language_id = f.language_id
GROUP BY l.language_id, l."name"
ORDER BY film_count DESC;
Задание 44. Сортировка с использованием стандартных функций: Выведите клиентов (таблица «customer») в порядке возрастания их полного имени (комбинация first_name и last_name).
SELECT customer_id, first_name, last_name
FROM customer
ORDER BY CONCAT(first_name, ' ', last_name);
Задание 45. Сортировка с использованием сложных выражений: Выведите актеров (таблица «actor») в порядке убывания средней длительности фильмов, в которых они снимались. Усредненная длительность рассчитывается для каждого актера.
SELECT a.actor_id, a.first_name, a.last_name, AVG(f.length) AS average_duration
FROM actor a
JOIN film_actor fa ON a.actor_id = fa.actor_id
JOIN film f ON fa.film_id = f.film_id
GROUP BY a.actor_id, a.first_name, a.last_name
ORDER BY average_duration DESC;
Соединения
В SQL, соединения позволяют объединять данные из нескольких таблиц в одном запросе.
Это полезно, когда ваши данные разбиты по разным таблицам, и вам нужно объединить их, чтобы получить полную картину.
Для чего используются соединения?
Ситуация:
- Предположим, у вас есть таблица с информацией о заказах (
orders) и таблица с информацией о продуктах (products). - Если вы хотите узнать, какие продукты были в каждом заказе, вам нужно объединить эти таблицы.
Пример с использованием соединения:
SELECT orders.order_id, orders.order_date,
products.product_name
FROM orders, products
WHERE orders.product_id = products.product_id;
Тот же пример, но с использованием JOIN
SELECT orders.order_id, orders.order_date, products.product_name
FROM orders
JOIN products ON orders.product_id = products.product_id;
Синтаксис и виды соединений
Синтаксис может варьироваться, но общая структура выглядит так:
INNER JOIN: Возвращает строки, которые имеют соответствующие значения в обеих таблицах.
SELECT *
FROM table1
INNER JOIN table2
ON table1.column = table2.column;
LEFT (OUTER) JOIN: Возвращает все строки из левой таблицы и соответствующие строки из правой таблицы. Если нет соответствия, будут возвращены NULL-значения.
SELECT *
FROM table1
LEFT JOIN table2 ON table1.column = table2.column;
RIGHT (OUTER) JOIN: Возвращает все строки из правой таблицы и соответствующие строки из левой таблицы. Если нет соответствия, будут возвращены NULL-значения.
SELECT *
FROM table1
RIGHT JOIN table2 ON table1.column = table2.column;
FULL (OUTER) JOIN: Возвращает все строки, когда есть соответствие в левой или правой таблице. Если нет соответствия, будут возвращены NULL-значения.
SELECT *
FROM table1
FULL JOIN table2 ON table1.column = table2.column;
Пример самосоединения:
Самосоединение (Self-Join): Когда таблица соединяется с самой собой.
Предположим, у нас есть таблица employees, и мы хотим получить информацию о сотрудниках и их непосредственных руководителях. В этом случае мы можем использовать самосоединение:
SELECT e.employee_id, e.employee_name, e.manager_id, m.employee_name as manager_name
FROM employees e
JOIN employees m ON e.manager_id = m.employee_id;
В этом запросе employees e и employees m представляют одну и ту же таблицу, но обозначаются разными псевдонимами (e и m), чтобы отличать роли сотрудников и их руководителей.
Пример сложных условий соединения:
Сложные условия соединения:
Допустим, у нас есть таблицы orders и customers, и мы хотим получить заказы для клиентов из определенного города, но также включить клиентов, у которых нет заказов.
Здесь мы используем сложное условие соединения c.customer_id = o.customer_id AND c.city = 'New York', чтобы отфильтровать заказы только для клиентов из Нью-Йорка, но при этом включить всех клиентов.
SELECT c.customer_id, c.customer_name, o.order_id, o.order_date
FROM customers c
LEFT JOIN orders o ON c.customer_id = o.customer_id AND c.city = 'New York';
Пример соединения с подзапросом:
Соединение с подзапросом:
Допустим, у нас есть таблицы employees и salaries, и мы хотим получить информацию о сотрудниках и их зарплатах, но только для тех, у кого зарплата выше средней.
SELECT e.employee_id, e.employee_name, s.salary_amount
FROM employees e
JOIN salaries s ON e.employee_id = s.employee_id
WHERE s.salary_amount > (SELECT AVG(salary_amount) FROM salaries);
В этом запросе мы используем подзапрос (SELECT AVG(salary_amount) FROM salaries) для получения средней зарплаты, и затем сравниваем зарплаты сотрудников с этим значением.
Задания на закрепление.
База данных «Полеты«.
Задание 46. Вывести все бронирования из таблицы
bookings, добавив к каждому бронированию информацию о соответствующем рейсе из таблицыflightsпо ключуbook_ref.
SELECT *
FROM bookings
JOIN flights ON bookings.book_ref = flights.book_ref;
Задание 47. Вывести список бортов из таблицы
aircrafts_data, а также количество сидений в каждом классе из таблицыseats, соединив их по коду борта.
SELECT aircrafts_data.*, seats.fare_conditions, COUNT(seats.*) AS total_seats
FROM aircrafts_data
JOIN seats ON aircrafts_data.aircraft_code = seats.aircraft_code
GROUP BY aircrafts_data.aircraft_code, seats.fare_conditions;
Задание 48. Вывести все бронирования из таблицы
bookings, добавив к каждому бронированию информацию о соответствующем рейсе из таблицыflightsпо ключуbook_ref. Включить в результат только те бронирования, у которых общая сумма (total_amount) превышает 5000.
SELECT *
FROM bookings
JOIN flights ON bookings.book_ref = flights.book_ref
WHERE bookings.total_amount > 5000;
Задание 49. Вывести список аэропортов из таблицы
airports_dataс указанием количества вылетов и прилетов рейсов для каждого аэропорта. Учитывать только аэропорты с не менее чем 20 рейсами.
SELECT airports_data.*,
COUNT(departures.flight_id) AS departures_count,
COUNT(arrivals.flight_id) AS arrivals_count
FROM airports_data
LEFT JOIN flights departures ON airports_data.airport_code = departures.departure_airport
LEFT JOIN flights arrivals ON airports_data.airport_code = arrivals.arrival_airport
GROUP BY airports_data.airport_code
HAVING COUNT(departures.flight_id) + COUNT(arrivals.flight_id) >= 20;
Задание 50. Вывести список билетов из таблицы
tickets, включая информацию о рейсе из таблицыflightsи дополнительные данные о месте из таблицыboarding_passes. Учесть только те билеты, для которых бортовая карта существует.
SELECT tickets.*, flights.*, boarding_passes.seat_no
FROM tickets
JOIN ticket_flights ON tickets.ticket_no = ticket_flights.ticket_no
JOIN flights ON ticket_flights.flight_id = flights.flight_id
JOIN boarding_passes ON ticket_flights.ticket_no = boarding_passes.ticket_no
WHERE boarding_passes.flight_id IS NOT NULL;
База данных «Диски«.
Задание 51. Выведите имена и фамилии актеров (таблица «actor»), а также названия фильмов (таблица «film»), в которых они снимались.
SELECT a.first_name, a.last_name, f.title
FROM actor a
JOIN film_actor fa ON a.actor_id = fa.actor_id
JOIN film f ON fa.film_id = f.film_id;
Задание 52. Выведите все категории фильмов (таблица «category»), а также названия фильмов (таблица «film»), даже если они не принадлежат к какой-либо категории.
SELECT c.name AS category_name, f.title
FROM category c
LEFT JOIN film_category fc ON c.category_id = fc.category_id
LEFT JOIN film f ON fc.film_id = f.film_id;
Задание 53. Выведите имена и фамилии сотрудников (таблица «staff») и их непосредственных руководителей (если они есть).
SELECT s1.first_name, s1.last_name, s2.first_name AS manager_first_name, s2.last_name AS manager_last_name
FROM staff s1
LEFT JOIN staff s2 ON s1.manager_staff_id = s2.staff_id;
Задание 54. Выведите имена клиентов (таблица «customer») и количество арендованных ими фильмов, округленное до ближайшего целого числа.
SELECT c.first_name, c.last_name, COUNT(r.rental_id) AS rental_count
FROM customer c
LEFT JOIN rental r ON c.customer_id = r.customer_id
GROUP BY c.first_name, c.last_name;
Задание 55. Выведите имена актеров (таблица «actor») и общую стоимость аренды всех фильмов, в которых они снимались.
SELECT a.first_name, a.last_name, SUM(f.rental_rate) AS total_rental_cost
FROM actor a
JOIN film_actor fa ON a.actor_id = fa.actor_id
JOIN film f ON fa.film_id = f.film_id
JOIN inventory i ON f.film_id = i.film_id
JOIN rental r ON i.inventory_id = r.inventory_id
GROUP BY a.first_name, a.last_name;
Работа с подзапросами
Для чего используются подзапросы?
Подзапросы в SQL используются для выполнения вложенных запросов внутри основного запроса.
Они позволяют вам получать данные из одного запроса и использовать их в другом запросе. Это полезно, когда вы хотите выполнить операции на основе результатов другого запроса.
Синтаксис и виды подзапросов
Общий синтаксис подзапроса:
SELECT column_name(s)
FROM table_name
WHERE column_name operator (SELECT column_name FROM table_name WHERE condition);
Виды подзапросов:
- Подзапрос в
SELECT:- Используется для возврата единственного значения или набора значений, которые могут быть использованы в основном запросе.
SELECT column_name, (SELECT AVG(salary) FROM employees) AS avg_salary FROM employees;
- Используется для возврата единственного значения или набора значений, которые могут быть использованы в основном запросе.
- Подзапрос в
FROM:- Используется для создания временной таблицы, которая может быть использована в основном запросе.
SELECT * FROM (SELECT employee_name, salary FROM employees WHERE department_id = 1) AS department_1_employees;
- Используется для создания временной таблицы, которая может быть использована в основном запросе.
- Подзапрос в
WHERE:- Используется для фильтрации основного запроса на основе результата вложенного запроса.
SELECT customer_name FROM customers WHERE customer_id IN (SELECT customer_id FROM orders WHERE order_date >= '2023-01-01');
- Используется для фильтрации основного запроса на основе результата вложенного запроса.
- Подзапрос в
JOIN:- Используется для соединения таблиц с использованием результатов вложенного запроса.
SELECT employees.employee_name, departments.department_name FROM employees JOIN (SELECT department_id, department_name FROM departments WHERE location = 'New York') AS departments ON employees.department_id = departments.department_id;
- Используется для соединения таблиц с использованием результатов вложенного запроса.
Использование агрегатных функций, полей и выражений
- Подзапросы могут использовать агрегатные функции, поля и выражения так же, как и обычные запросы.
- Важно, чтобы подзапрос возвращал один столбец или набор значений, чтобы его можно было использовать в операторах сравнения (
=,>,<, и т. д.).
Пример: Подзапрос с использованием агрегатной функции:
SELECT employee_name, salary
FROM employees
WHERE salary > (SELECT AVG(salary) FROM employees);
Использование ANY и ALL в подзапросах
Ключевые слова ANY и ALL используются в подзапросах для сравнения значения с набором значений, возвращаемых подзапросом.
Использование ANY:
- Пример с
ANYвWHERE:- В этом примере мы выбираем продукты, цена которых выше цены любого продукта в категории ‘Electronics’.
SELECT product_name, price FROM products WHERE price > ANY (SELECT price FROM products WHERE category = 'Electronics');
- В этом примере мы выбираем продукты, цена которых выше цены любого продукта в категории ‘Electronics’.
- Пример с
ANYвJOIN:- Здесь мы выбираем заказы, включающие продукт с
product_id = 1.SELECT orders.order_id, orders.order_date FROM orders WHERE orders.order_id = ANY (SELECT order_id FROM order_items WHERE product_id = 1);
- Здесь мы выбираем заказы, включающие продукт с
Использование ALL:
- Пример с
ALLвWHERE:SELECT supplier_name FROM suppliers WHERE supplier_id = ALL (SELECT supplier_id FROM products WHERE price > 100);- Этот запрос возвращает поставщиков, у которых все продукты стоят больше $100.
- Пример с
ALLи агрегатной функцией:SELECT employee_name, salary FROM employees WHERE salary > ALL (SELECT AVG(salary) FROM employees GROUP BY department_id);- Здесь мы выбираем сотрудников, у которых зарплата выше средней зарплаты в каждом отделе.
Дополнительные сведения:
ANYиALLс операторами сравнения: Можно использоватьANYиALLс различными операторами сравнения (например,<,>,=, и т. д.).ANYиALLс вложенными подзапросами: Можно использовать вложенные подзапросы сANYиALL, делая запрос более гибким.ANYиALLсовместно с подзапросами вSELECT: ПомимоWHERE,ANYиALLмогут использоваться в оператореSELECTдля сравнения значений с результатами подзапросов.
Примеры:
Пример с ANY в SELECT:
SELECT employee_name, salary,
salary > ANY (SELECT salary FROM employees WHERE department_id = 1) AS higher_than_any
FROM employees;
Этот запрос добавляет столбец higher_than_any, который показывает, превышает ли зарплата сотрудника зарплату любого сотрудника из отдела 1.
Пример с ALL в SELECT:
SELECT department_id, MAX(salary),
MAX(salary) = ALL (SELECT salary FROM employees WHERE department_id = departments.department_id) AS is_highest_salary
FROM employees
GROUP BY department_id;
Этот запрос добавляет столбец is_highest_salary, который показывает, является ли максимальная зарплата в отделе самой высокой в отделе.
Общие табличные выражения (CTE) с ключевым словом WITH в SQL:
Общие табличные выражения (Common Table Expressions, CTE) представляют собой временные результаты запроса, которые можно использовать внутри других запросов. Они создаются с использованием ключевого слова WITH. CTE обеспечивают более чистый и читаемый способ организации сложных запросов.
Синтаксис CTE:
WITH cte_name (column1, column2, ...) AS (
-- Здесь следует запрос, создающий временный результат
SELECT column1, column2, ...
FROM table_name
WHERE condition
)
-- Далее следует основной запрос, который может использовать CTE
SELECT *
FROM cte_name;
Примеры использования CTE:
Пример 1: Создание CTE для фильтрации данных:
WITH high_salary_employees AS (
SELECT employee_name, salary
FROM employees
WHERE salary > 50000
)
SELECT * FROM high_salary_employees;
Этот запрос создает CTE high_salary_employees, который содержит сотрудников с зарплатой выше $50,000, а затем основной запрос выводит данные из CTE.
Пример 2: Использование нескольких CTE:
WITH
department_cte AS (
SELECT department_id, department_name
FROM departments
),
employee_cte AS (
SELECT employee_name, department_id
FROM employees
)
SELECT e.employee_name, d.department_name
FROM employee_cte e
JOIN department_cte d ON e.department_id = d.department_id;
В этом примере создаются два CTE (department_cte и employee_cte), а затем основной запрос соединяет результаты этих CTE.
Пример 3: Рекурсивное CTE для обхода иерархии:
WITH RECURSIVE org_hierarchy AS (
SELECT id, name, manager_id
FROM employees
WHERE manager_id IS NULL
UNION
SELECT e.id, e.name, e.manager_id
FROM employees e
JOIN org_hierarchy h ON e.manager_id = h.id
)
SELECT * FROM org_hierarchy;
Этот запрос создает рекурсивное CTE org_hierarchy для обхода иерархии сотрудников с использованием их manager_id.
Пример 4. использования CTE внутри другого CTE:
WITH
cte1 AS (SELECT * FROM table1),
cte2 AS (SELECT * FROM cte1)
SELECT * FROM cte2;
Задания на закрепление подзапросов
БД Перелеты
Задание 56. Выбрать все борты (aircraft_code) из seats, для которых существуют записи в flights.
SELECT DISTINCT aircraft_code
FROM seats
WHERE aircraft_code IN (SELECT aircraft_code FROM flights);
Задание 57. Выбрать все аэропорты из airports_data, для которых не существуют рейсы, вылетающие из них.
SELECT *
FROM airports_data
WHERE airport_code NOT IN (SELECT DISTINCT departure_airport FROM flights);
Задание 58. Выбрать все записи из
tickets, у которых сумма (amount) вticket_flightsбольше средней суммы по всем билетам.
SELECT *
FROM tickets
WHERE amount > (SELECT AVG(amount) FROM ticket_flights);
Задание 59. Выбрать все записи из
flights, для которых количество билетов (ticket_no) вticket_flightsбольше 50% общего количества мест в самолете.
SELECT *
FROM flights
WHERE (SELECT COUNT(*) FROM ticket_flights WHERE ticket_flights.flight_id = flights.flight_id) >
0.5 * (SELECT COUNT(*) FROM seats WHERE seats.aircraft_code = flights.aircraft_code);
Задание 60. Выбрать все борты (
aircraft_code) изseats, для которых средняя стоимость места (amount) вticket_flightsвыше средней стоимости места по всем бортам.
WITH AvgSeatAmounts AS (
SELECT aircraft_code, AVG(amount) AS avg_seat_amount
FROM ticket_flights
GROUP BY aircraft_code
)
SELECT seats.aircraft_code
FROM seats
JOIN AvgSeatAmounts ON seats.aircraft_code = AvgSeatAmounts.aircraft_code
WHERE seats.amount > AvgSeatAmounts.avg_seat_amount;
Задание 61. Выбрать все записи из
flights, для которых дата фактического прибытия (actual_arrival) отличается от запланированной (scheduled_arrival) более чем на 1 час.
SELECT *
FROM flights
WHERE EXTRACT(EPOCH FROM (actual_arrival - scheduled_arrival) / 3600) > 1;
Задание 62. Выбрать все записи из
airports_data, для которых есть хотя бы один рейс с задержкой (status = 'Delayed') из этого аэропорта.
SELECT *
FROM airports_data
WHERE airport_code IN (SELECT DISTINCT arrival_airport FROM flights WHERE status = 'Delayed');
Задание 63.
Задание 64. Выбрать все записи из
flights, для которых существует рейс с аналогичным номером рейса (flight_no), но с другим временем вылета (scheduled_departure).
SELECT *
FROM flights
WHERE (flight_no, scheduled_departure) IN (SELECT flight_no, MIN(scheduled_departure)
FROM flights
GROUP BY flight_no
HAVING COUNT(DISTINCT scheduled_departure) > 1);
Задание 65. Использовать CTE для вывода статистики о задержках в аэропортах, включая общее количество задержек и среднюю продолжительность задержек.
WITH DelayStatistics AS (
SELECT arrival_airport,
COUNT(*) AS total_delays,
AVG(EXTRACT(EPOCH FROM (actual_arrival - scheduled_arrival) / 60)) AS avg_delay_duration
FROM flights
WHERE status = 'Delayed'
GROUP BY arrival_airport
)
SELECT airports_data.*, DelayStatistics.*
FROM airports_data
LEFT JOIN DelayStatistics ON airports_data.airport_code = DelayStatistics.arrival_airport;
БД Прокат дисков
Задание 66. Выведите имена всех актеров (таблица «actor») и количество фильмов, в которых они снимались.
SELECT first_name, last_name, (
SELECT COUNT(*)
FROM film_actor
WHERE actor_id = a.actor_id
) AS film_count
FROM actor a;
Задание 67. Выведите все категории фильмов (таблица «category»), в которых есть более 5 фильмов.
SELECT *
FROM category
WHERE category_id IN (
SELECT category_id
FROM film_category
GROUP BY category_id
HAVING COUNT(*) > 5
);
Задание 68. Выведите имена клиентов (таблица «customer»), которые совершили платежи больше, чем любой из сотрудников.
SELECT first_name, last_name
FROM customer
WHERE payment_amount > ANY (
SELECT amount
FROM payment
);
Задание 69. Выведите имена сотрудников (таблица «staff»), у которых все платежи превышают $10.
SELECT first_name, last_name
FROM staff
WHERE 10 < ALL (
SELECT amount
FROM payment
WHERE payment.staff_id = staff.staff_id
);
Задание 70. Выведите среднюю стоимость аренды фильмов по каждой категории (таблица «category»).
SELECT c.name AS category, AVG(f.rental_rate) AS avg_rental_rate
FROM category c
JOIN film_category fc ON c.category_id = fc.category_id
JOIN film f ON fc.film_id = f.film_id
GROUP BY c.name;
Задание 71. Выведите имена и фамилии сотрудников (таблица «staff») и информацию, являются ли они менеджерами (1 — менеджер, 0 — не менеджер).
SELECT first_name, last_name,
CASE WHEN staff_id IN (
SELECT manager_staff_id
FROM store
) THEN 1 ELSE 0 END AS is_manager
FROM staff;
Задание 72. Выведите имена и фамилии актеров (таблица «actor»), снимавшихся в фильмах в жанре «Comedy».
SELECT first_name, last_name
FROM actor a
WHERE EXISTS (
SELECT 1
FROM film_actor fa
JOIN film_category fc ON fa.film_id = fc.film_id
JOIN category c ON fc.category_id = c.category_id
WHERE a.actor_id = fa.actor_id AND c.name = 'Comedy'
);
Задание 73. Выведите имена клиентов (таблица «customer») и общую сумму их платежей с использованием общего выражения (CTE).
WITH CustomerPayments AS (
SELECT customer_id, SUM(amount) AS total_payments
FROM payment
GROUP BY customer_id
)
SELECT c.first_name, c.last_name, cp.total_payments
FROM customer c
LEFT JOIN CustomerPayments cp ON c.customer_id = cp.customer_id;
Задание 74. Выведите иерархию менеджеров и подчиненных с использованием рекурсивного CTE.
WITH RECURSIVE EmployeeHierarchy AS (
SELECT staff_id, first_name, last_name, manager_staff_id
FROM staff
WHERE manager_staff_id IS NULL
UNION
SELECT s.staff_id, s.first_name, s.last_name, s.manager_staff_id
FROM staff s
JOIN EmployeeHierarchy e ON s.manager_staff_id = e.staff_id
)
SELECT * FROM EmployeeHierarchy;
Задание 75. Выведите топ-3 клиентов (таблица «customer») с наибольшими общими суммами платежей.
SELECT customer_id, first_name, last_name, total_payments
FROM (
SELECT customer_id, first_name, last_name,
RANK() OVER (ORDER BY total_payments DESC) AS ranking
FROM (
SELECT customer_id, first_name, last_name, SUM(amount) AS total_payments
FROM payment
GROUP BY customer_id, first_name, last_name
) AS CustomerPayments
) AS RankedCustomers
WHERE ranking <= 3;
Сложная группировка. GROUPING SETS, ROLLUP, CUBE
ROLLUP и CUBE — это дополнительные опции для оператора GROUP BY в PostgreSQL, предназначенные для создания расширенных отчетов и агрегирования данных на различных уровнях иерархии. Они позволяют создавать более мощные и гибкие запросы для анализа данных.
ROLLUP:
ROLLUP используется для создания итоговых строк для каждого уровня иерархии. Он автоматически добавляет строки итогов для всех комбинаций указанных столбцов, уровень за уровнем, начиная с самого верхнего.
Пример использования ROLLUP:
SELECT country, city, SUM(sales)
FROM sales_data
GROUP BY ROLLUP (country, city);
Этот запрос создаст итоги по уровням: (country, city), (country), и () (все данные без группировки).
CUBE:
CUBE генерирует итоги для всех возможных комбинаций указанных столбцов. Это более мощный вариант, поскольку включает в себя все комбинации столбцов независимо от их порядка.
Пример использования CUBE:
SELECT country, city, product, SUM(sales)
FROM sales_data
GROUP BY CUBE (country, city, product);
Этот запрос создаст итоги для всех комбинаций: (country, city, product), (country, city), (country, product), (city, product), (country), (city), (product), и ().
Общие черты ROLLUP и CUBE:
- Упрощение агрегации данных: Обе опции упрощают создание отчетов и агрегацию данных на различных уровнях детализации.
- Многомерные анализы: Их использование особенно полезно для анализа многомерных данных, где необходимо рассматривать данные с разных точек зрения.
- Гибкость запросов: Позволяют создавать более гибкие и динамичные запросы для различных потребностей анализа.
Примечание: Важно учитывать, что использование
ROLLUPиCUBEможет привести к большему количеству строк в результате запроса, что может сказаться на производительности. Это стоит учитывать при работе с большими объемами данных.
GROUPING SETS — это расширение стандартного оператора GROUP BY, предоставляющее более гибкий способ группировки данных в PostgreSQL. Он позволяет создавать агрегаты для различных комбинаций столбцов, не повторяя каждый раз полный список группировочных столбцов.
Синтаксис GROUPING SETS:
SELECT column1, column2, ..., aggregate_function(column)
FROM table
GROUP BY GROUPING SETS ((column1, column2), (column1), ());
- column1, column2, …: Список столбцов для группировки.
- aggregate_function(column): Функции агрегации, которые применяются к столбцам.
- table: Имя таблицы, из которой выбираются данные.
Пример использования GROUPING SETS:
Пример: Получение суммы продаж по датам и продуктам:
SELECT sale_date, product_name, SUM(sale_amount) AS total_sales
FROM sales
GROUP BY GROUPING SETS ((sale_date, product_name), (sale_date), ());
В этом запросе:
GROUPING SETSпозволяет создавать агрегаты для комбинаций(sale_date, product_name),(sale_date), и пустого множества().SUM(sale_amount)вычисляет сумму продаж для каждой указанной группы.
Дополнительные сведения:
- Пустое множество
(): Используется для вычисления общего агрегата (без группировки). - Применение к нескольким столбцам: Можно группировать данные по нескольким столбцам, создавая разные комбинации.
- Преимущества:
GROUPING SETSобеспечивает более чистый и компактный синтаксис по сравнению с использованиемUNION ALLдля создания разных агрегатов. - Совместное использование с ROLLUP и CUBE:
GROUPING SETSможет использоваться вместе сROLLUPиCUBEдля создания более сложных структур агрегации.
Примеры работы со сложными группировками
Пример с ROLLUP:
-- Создаем таблицу для примера
CREATE TABLE sales_data (
country VARCHAR(50),
city VARCHAR(50),
product VARCHAR(50),
sales INT
);
-- Вставляем тестовые данные
INSERT INTO sales_data VALUES ('USA', 'New York', 'Laptop', 1000);
INSERT INTO sales_data VALUES ('USA', 'New York', 'Phone', 500);
INSERT INTO sales_data VALUES ('USA', 'Chicago', 'Laptop', 800);
INSERT INTO sales_data VALUES ('USA', 'Chicago', 'Phone', 300);
INSERT INTO sales_data VALUES ('Canada', 'Toronto', 'Laptop', 1200);
INSERT INTO sales_data VALUES ('Canada', 'Toronto', 'Phone', 600);
-- Запрос с использованием ROLLUP
SELECT country, city, product, SUM(sales) AS total_sales
FROM sales_data
GROUP BY ROLLUP (country, city, product)
ORDER BY country, city, product;
Результат:
country | city | product | total_sales
---------+-----------+---------+-------------
Canada | Toronto | Laptop | 1200
Canada | Toronto | Phone | 600
Canada | Toronto | | 1800 -- Итоги для Canada и Toronto
USA | Chicago | Laptop | 800
USA | Chicago | Phone | 300
USA | Chicago | | 1100 -- Итоги для USA и Chicago
USA | New York | Laptop | 1000
USA | New York | Phone | 500
USA | New York | | 1500 -- Итоги для USA и New York
USA | | Laptop | 1800
USA | | Phone | 800
USA | | | 2600 -- Итоги для всей страны
| | | 4400 -- Общие итоги
Пример с CUBE:
-- Запрос с использованием CUBE
SELECT country, city, product, SUM(sales) AS total_sales
FROM sales_data
GROUP BY CUBE (country, city, product)
ORDER BY country, city, product;
Результат:
country | city | product | total_sales
---------+-----------+---------+-------------
Canada | Toronto | Laptop | 1200
Canada | Toronto | Phone | 600
Canada | Toronto | | 1800 -- Итоги для Canada и Toronto
Canada | | Laptop | 1200
Canada | | Phone | 600
Canada | | | 1800 -- Итоги для всей страны
USA | Chicago | Laptop | 800
USA | Chicago | Phone | 300
USA | Chicago | | 1100 -- Итоги для USA и Chicago
USA | New York | Laptop | 1000
USA | New York | Phone | 500
USA | New York | | 1500 -- Итоги для USA и New York
USA | | Laptop | 1800
USA | | Phone | 800
USA | | | 2600 -- Итоги для всей страны
| | | 4400 -- Общие итоги
Пример с GROUPING SETS:
-- Запрос с использованием GROUPING SETS
SELECT country, city, product, SUM(sales) AS total_sales
FROM sales_data
GROUP BY GROUPING SETS ((country, city, product), (country, city), (country), ());
Результат:
country | city | product | total_sales
---------+-----------+---------+-------------
Canada | Toronto | Laptop | 1200
Canada | Toronto | Phone | 600
Canada | Toronto | | 1800 -- Итоги для Canada и Toronto
Canada | Toronto | | 1800 -- Итоги для Canada и Toronto (дубль)
Canada | | | 1800 -- Итоги для всей страны
USA | Chicago | Laptop | 800
USA | Chicago | Phone | 300
USA | Chicago | | 1100 -- Итоги для USA и Chicago
USA | New York | Laptop | 1000
USA | New York | Phone | 500
USA | New York | | 1500 -- Итоги для USA и New York
USA | New York | | 1500 -- Итоги для USA и New York (дубль)
USA | | | 2600 -- Итоги для всей страны
| | | 4400 -- Общие итоги
| | | 4400 -- Общие итоги (дубль)
Задания для тренировки
БД перелеты
Задание 76. Получить общее количество билетов (
ticket_no) для каждого класса обслуживания (fare_conditions) и общее количество билетов без учета класса.
SELECT fare_conditions, COUNT(*) AS ticket_count
FROM ticket_flights
GROUP BY ROLLUP(fare_conditions);
Задание 77. Получить общее количество билетов (
ticket_no) для каждого класса обслуживания (fare_conditions), а также общее количество билетов для каждого рейса (flight_id).
SELECT flight_id, fare_conditions, COUNT(*) AS ticket_count
FROM ticket_flights
GROUP BY CUBE(flight_id, fare_conditions);
Задание 78. Получить общее количество билетов (
ticket_no) для каждого класса обслуживания (fare_conditions) и для каждого рейса (flight_id), а также общее количество билетов без учета класса и рейса.
SELECT flight_id, fare_conditions, COUNT(*) AS ticket_count
FROM ticket_flights
GROUP BY GROUPING SETS((flight_id, fare_conditions), ());
Задание 79. Получить общее количество билетов (
ticket_no) для каждого класса обслуживания (fare_conditions) и для каждого рейса (flight_id), а также общее количество билетов для каждого аэропорта отправления (departure_airport) и аэропорта прибытия (arrival_airport).
SELECT flight_id, fare_conditions, COUNT(*) AS ticket_count
FROM ticket_flights
GROUP BY GROUPING SETS((flight_id, fare_conditions), (departure_airport, arrival_airport));
Задание 80. Получить общее количество билетов (
ticket_no) для каждого класса обслуживания (fare_conditions), для каждого рейса (flight_id), а также общее количество билетов для каждого аэропорта отправления (departure_airport) и аэропорта прибытия (arrival_airport). Дополнительно, вывести общее количество билетов без учета класса, рейса и аэропортов.
SELECT flight_id, fare_conditions, departure_airport, arrival_airport, COUNT(*) AS ticket_count
FROM ticket_flights
GROUP BY CUBE(flight_id, fare_conditions, departure_airport, arrival_airport);
БД прокат дисков
Задание 81. Простая группировка с ROLLUP. Выведите общее количество фильмов (таблица «film») для каждого языка (таблица «language») и общее количество фильмов в целом.
SELECT language_id, COUNT(*) AS film_count
FROM film
GROUP BY ROLLUP (language_id);
Задание 82. Группировка с CUBE по годам выпуска и языкам. Выведите количество фильмов (таблица «film») для каждого года выпуска и языка, а также общее количество фильмов по годам и общее количество фильмов в целом.
SELECT release_year, language_id, COUNT(*) AS film_count
FROM film
GROUP BY CUBE (release_year, language_id);
Задание 83. Группировка с использованием GROUPING SETS по категориям, языкам и годам выпуска. Выведите количество фильмов (таблица «film») для каждой категории, языка и года выпуска, а также общее количество фильмов по каждой категории, языку, году выпуска и общее количество фильмов в целом.
SELECT category_id, language_id, release_year, COUNT(*) AS film_count
FROM film
GROUP BY GROUPING SETS ((category_id, language_id, release_year), (category_id, language_id), (category_id), ());
Задание 84. Группировка с ROLLUP и вычислением средней стоимости аренды. Выведите среднюю стоимость аренды фильмов (таблица «film») для каждого года выпуска и языка, а также общую среднюю стоимость аренды по годам и общую среднюю стоимость аренды в целом.
SELECT release_year, language_id, AVG(rental_rate) AS avg_rental_rate
FROM film
GROUP BY ROLLUP (release_year, language_id);
Задание 85. Группировка с CUBE, включающая агрегатные функции и выражения. Выведите суммарные выручки от аренды фильмов (таблица «film») для каждой категории, языка и года выпуска, а также общую суммарную выручку по каждой категории, языку, году выпуска и общую суммарную выручку в целом.
SELECT category_id, language_id, release_year, SUM(rental_rate * rental_duration) AS total_revenue
FROM film
GROUP BY CUBE (category_id, language_id, release_year);
Индивидуальное и групповое обучение «Аналитик данных»
Если вы хотите стать экспертом в аналитике, могу помочь. Запишитесь на мой курс «Аналитик данных» и начните свой путь в мир ИТ уже сегодня!
Контакты
Для получения дополнительной информации и записи на курсы свяжитесь со мной:
Телеграм: https://t.me/Vvkomlev
Email: victor.komlev@mail.ru
Объясняю сложное простыми словами. Даже если вы никогда не работали с ИТ и далеки от программирования, теперь у вас точно все получится! Проверено десятками примеров моих учеников.
Гибкий график обучения. Я предлагаю занятия в мини-группах и индивидуально, что позволяет каждому заниматься в удобном темпе. Вы можете совмещать обучение с работой или учебой.
Практическая направленность. 80%: практики, 20% теории. У меня множество авторских заданий, которые фокусируются на практике. Вы не просто изучаете теорию, а сразу применяете знания в реальных проектах и задачах.
Разнообразие учебных материалов: Теория представлена в виде текстовых уроков с примерами и видео, что делает обучение максимально эффективным и удобным.
Понимаю, что обучение информационным технологиям может быть сложным, особенно для новичков. Моя цель – сделать этот процесс максимально простым и увлекательным. У меня персонализированный подход к каждому ученику. Максимальный фокус внимания на ваши потребности и уровень подготовки.




