Pandas – это мощная библиотека программирования на языке Python, предназначенная для обработки и анализа данных.
Она предоставляет высокоуровневые структуры данных, такие как DataFrame (таблицы данных) и Series (одномерные массивы), которые облегчают работу с табличными данными. Pandas включает в себя функциональность для чтения, записи, фильтрации, агрегации, визуализации и многих других операций с данными.
Важные особенности Pandas:
- DataFrame: Основная структура данных в Pandas, представляющая собой двумерную таблицу с метками строк и столбцов. Это удобный способ представления и манипулирования табличными данными.
- Series: Одномерный массив данных, который может быть использован в качестве столбца в DataFrame. Series обладает индексом, что делает его более гибким для работы с данными.
- Мощные инструменты для анализа данных: Pandas предоставляет функционал для фильтрации, сортировки, группировки, агрегации и многих других операций, что делает его отличным инструментом для аналитики и исследования данных.
- Поддержка временных данных: Pandas обладает удобными средствами работы с временными рядами, что делает его популярным инструментом в области финансов, анализа временных рядов и статистики.
- Интеграция с другими библиотеками: Pandas легко интегрируется с другими популярными библиотеками Python, такими как NumPy, Matplotlib и SciPy, что позволяет создавать комплексные аналитические решения.
Коротко говоря, Pandas предоставляет эффективные инструменты для обработки и анализа данных, что делает его неотъемлемой частью инструментария для специалистов по анализу данных и разработчиков в области машинного обучения.
Преимущества использования Pandas для анализа данных:
- Pandas предоставляет удобные и эффективные структуры данных (DataFrame и Series) для работы с табличными данными.
- Библиотека обладает мощными инструментами для обработки, фильтрации и анализа данных.
- Pandas легко интегрируется с другими библиотеками Python, такими как NumPy, Matplotlib и SciPy.
Установка и импорт библиотеки
Установка:
- Для установки Pandas используйте команду:
pip install pandas.
Импорт в Python:
- После установки, импортируйте библиотеку в свой скрипт или блокнот с помощью команды:
import pandas as pd.
Пример использования:
import pandas as pd
# Создание DataFrame (таблицы данных)
data = {'Имя': ['Анна', 'Борис', 'Светлана'],
'Возраст': [25, 30, 22],
'Зарплата': [50000, 70000, 45000]}
df = pd.DataFrame(data)
# Вывод первых строк таблицы
print(df.head())
Этот код создает простую таблицу данных с именами, возрастом и зарплатой, а затем выводит первые строки этой таблицы.
Основные термины и примеры использования
Series:
- Что это: Series — это одномерный массив (подобный списку) данных в библиотеке Pandas. Он может содержать данные любого типа, включая числа, строки и другие объекты.
- Пример:
import pandas as pd # Создание Series из списка my_series = pd.Series([10, 20, 30, 40, 50]) print(my_series)Вывод:
0 10 1 20 2 30 3 40 4 50 dtype: int64
DataFrame:
- Что это: DataFrame — это двумерная таблица данных, представленная в виде структуры с метками строк и столбцов. Можно представить его как электронную таблицу или базу данных.
- Пример:
import pandas as pd # Создание DataFrame из словаря data = {'Имя': ['Анна', 'Борис', 'Светлана'], 'Возраст': [25, 30, 22], 'Зарплата': [50000, 70000, 45000]} my_dataframe = pd.DataFrame(data) print(my_dataframe)Вывод:
Имя Возраст Зарплата 0 Анна 25 50000 1 Борис 30 70000 2 Светлана 22 45000
Индекс:

- Что это: Индекс — это метка, присвоенная каждой строке в Series или DataFrame. Он обеспечивает уникальную идентификацию каждой записи и упрощает доступ и манипуляции с данными.
- Пример:
import pandas as pd # Создание DataFrame с явным заданием индекса data = {'Имя': ['Анна', 'Борис', 'Светлана'], 'Возраст': [25, 30, 22], 'Зарплата': [50000, 70000, 45000]} my_dataframe = pd.DataFrame(data, index=['сотрудник1', 'сотрудник2', 'сотрудник3']) print(my_dataframe)Вывод:
Имя Возраст Зарплата сотрудник1 Анна 25 50000 сотрудник2 Борис 30 70000 сотрудник3 Светлана 22 45000
Способы создания индексов
В Pandas индекс можно создать различными способами. Давайте рассмотрим несколько вариантов:
- Не задавать индекс в явном виде:
import pandas as pd data = {'Имя': ['Анна', 'Борис', 'Светлана'], 'Возраст': [25, 30, 22], 'Зарплата': [50000, 70000, 45000]} my_dataframe = pd.DataFrame(data) print(my_dataframe)Имя Возраст Зарплата 0 Анна 25 50000 1 Борис 30 70000 2 Светлана 22 45000В этом случае Pandas автоматически создаст целочисленный индекс, начиная с 0.
- Создание индекса на основе столбца данных:
import pandas as pd data = {'Имя': ['Анна', 'Борис', 'Светлана'], 'Возраст': [25, 30, 22], 'Зарплата': [50000, 70000, 45000]} my_dataframe = pd.DataFrame(data) # Используем столбец "Имя" в качестве индекса my_dataframe.set_index('Имя', inplace=True) print(my_dataframe)Возраст Зарплата Имя Анна 25 50000 Борис 30 70000 Светлана 22 45000В этом примере столбец «Имя» стал индексом DataFrame.
- Создание вычисляемого или генерируемого индекса:
import pandas as pd data = {'Возраст': [25, 30, 22], 'Зарплата': [50000, 70000, 45000]} my_dataframe = pd.DataFrame(data) # Генерация индекса от 100 my_dataframe.index = range(100, 100 + len(my_dataframe)) print(my_dataframe)Возраст Зарплата 100 25 50000 101 30 70000 102 22 45000В этом примере мы создали индекс, начиная с числа 100.
Работа с индексами
Работа с индексами в Pandas предоставляет множество возможностей для управления данными и выполнения операций, таких как сортировка, смена и перестройка индексов. Вот основные способы работы с индексами и их методы:
- Сортировка индекса: Методы для сортировки индекса позволяют упорядочить строки в датафрейме или серии на основе значений индекса.
sort_index(): Сортирует индекс по возрастанию или убыванию.
Пример:
df.sort_index(ascending=False) # Сортировка индекса по убыванию - Смена индекса: Методы для изменения индекса позволяют заменить текущий индекс на другой столбец или на другую последовательность значений.
set_index(): Устанавливает новый индекс, используя значения из одного или нескольких столбцов.
Пример:
df.set_index('new_index_column') # Установка нового индекса на основе столбца 'new_index_column' - Перестройка индекса: Методы для перестройки индекса позволяют изменить порядок или значения индекса без изменения данных.
reindex(): Перестраивает индекс на основе новых меток индекса или дополняет его новыми метками.
Пример:
df.reindex(new_index_labels) # Перестройка индекса на основе новых меток индекса
Кроме того, у этих методов есть дополнительные параметры:
axis: Определяет, сортируется или перестраивается индекс по строкам (axis=0, по умолчанию) или по столбцам (axis=1).ascending: Определяет порядок сортировки индекса (Trueдля возрастания,Falseдля убывания).level: При работе с иерархическими индексами позволяет указать уровень, по которому производится сортировка или перестройка.fill_value: При перестройке индекса определяет значение, которое будет использоваться для заполнения отсутствующих меток.
Пример работы с индексами на прикладных данных:
import pandas as pd
# Создание датафрейма с индексом из дат
dates = pd.date_range('2022-01-01', periods=5)
df = pd.DataFrame({'A': [1, 2, 3, 4, 5]}, index=dates)
# Смена индекса на другой столбец
df.set_index('A')
# Перестройка индекса на основе новых меток
new_index = pd.date_range('2022-01-02', periods=6)
df.reindex(new_index)
# Сортировка индекса по убыванию
df.sort_index(ascending=False)
Практическое применение Series
Series в Pandas — это одномерный массив с метками, который может содержать данные различных типов. Он может быть использован для представления одного столбца данных в DataFrame или просто для работы с одномерными данными. Несколько практических примеров применения Series:
- Извлечение столбца из DataFrame: Метод
DataFrame['column_name']возвращаетSeries, который представляет один столбец данных из DataFrame.import pandas as pd # Создание DataFrame для примера data = {'A': [1, 2, 3], 'B': [4, 5, 6]} df = pd.DataFrame(data) # Извлечение столбца 'A' в виде Series series_A = df['A'] - Агрегирование данных:
Seriesможно использовать для вычисления статистических показателей, таких как среднее значение, медиана, минимум, максимум и т. д.# Вычисление среднего значения для столбца 'A' mean_A = series_A.mean() - Фильтрация данных:
Seriesможет быть использован для фильтрации данных по определенному условию.# Фильтрация значений больше 2 filtered_series = series_A[series_A > 2] - Итерация по данным:
Seriesможно использовать для итерации по элементам и выполнения каких-либо операций.# Итерация по элементам Series for value in series_A: print(value) - Индексирование и выборка данных:
Seriesподдерживает различные методы индексации и выборки данных.# Выборка данных по индексу value_at_index_0 = series_A[0] - Визуализация данных:
Seriesможет быть использован для создания графиков и визуализации данных.# Построение графика series_A.plot() - Выполнение операций с другими Series:
Seriesможно использовать для выполнения операций с другими Series, включая арифметические операции.# Выполнение арифметической операции с другим Series series_sum = series_A + df['B']
Цепочки методов
Цепочки методов в библиотеке Pandas позволяют комбинировать несколько операций обработки данных в одну последовательность, что делает код более компактным и удобным. Вот несколько примеров применения цепочек методов:
Пример 1: Фильтрация, группировка и агрегация данных
import pandas as pd
# Создание датафрейма с реальными данными
data = {
'Город': ['Москва', 'Санкт-Петербург', 'Москва', 'Санкт-Петербург', 'Москва'],
'Температура': [25, 23, 28, 22, 27],
'Влажность': [50, 60, 45, 55, 48]
}
df = pd.DataFrame(data)
# Фильтрация данных для города Москва и вычисление средней температуры
average_temp_moscow = df[df['Город'] == 'Москва'].groupby('Город')['Температура'].mean()
print(average_temp_moscow)
Пример 2: Преобразование данных и сортировка
import pandas as pd
# Создание датафрейма с реальными данными
data = {
'Имя': ['Алексей', 'Мария', 'Иван', 'Екатерина', 'Дмитрий'],
'Зарплата': ['$5000', '$6000', '$4500', '$5500', '$4800']
}
df = pd.DataFrame(data)
# Удаление символа '$' и преобразование к числовому типу
df['Зарплата'] = df['Зарплата'].str.replace('$', '').astype(int)
# Сортировка по убыванию зарплаты
sorted_df = df.sort_values(by='Зарплата', ascending=False)
print(sorted_df)
Пример 3: Вычисление нового столбца и фильтрация
import pandas as pd
# Создание датафрейма с реальными данными
data = {
'Название': ['Продукт A', 'Продукт B', 'Продукт C', 'Продукт D'],
'Продажи_2022': [10000, 12000, 8000, 15000],
'Продажи_2023': [11000, 11500, 8500, 16000]
}
df = pd.DataFrame(data)
# Вычисление изменения продаж и фильтрация для увеличения продаж в 2023 году
filtered_df = df[(df['Продажи_2023'] - df['Продажи_2022']) > 0]
print(filtered_df)
Загрузка данных в датафреймы
Pandas предоставляет удобные функции для чтения данных из различных источников.
- Чтение из CSV-файла:
import pandas as pd # Чтение данных из CSV-файла my_dataframe = pd.read_csv('путь_к_файлу.csv') - Чтение из Excel-файла:
import pandas as pd # Чтение данных из Excel-файла my_dataframe = pd.read_excel('файл.xlsx', sheet_name='Лист1') - Чтение из SQL-запроса или базы данных:
import pandas as pd from sqlalchemy import create_engine # Создание соединения с базой данных engine = create_engine('sqlite:///:memory:') # В примере - временная база данных SQLite # Чтение данных из SQL-запроса query = "SELECT * FROM my_table;" my_dataframe = pd.read_sql(query, engine) - Чтение данных из веб-ресурса (например, CSV с веб-сервера):
import pandas as pd # Чтение данных из веб-ресурса url = 'https://example.com/data.csv' my_dataframe = pd.read_csv(url) - Чтение данных из JSON-файла:
import pandas as pd # Чтение данных из JSON-файла my_dataframe = pd.read_json('файл.json') - Чтение данных из Clipboard (буфера обмена):
import pandas as pd # Чтение данных из буфера обмена (Ctrl+C/Ctrl+V) my_dataframe = pd.read_clipboard() - Чтение данных из HTML-таблицы на веб-странице:
import pandas as pd # Чтение данных из HTML-таблицы на веб-странице url = 'https://example.com/page_with_table.html' tables = pd.read_html(url) my_dataframe = tables[0] # Выбор первой таблицы на странице
Параметры загрузки данных на примере метода read_csv
Функция read_csv в Pandas позволяет читать данные из CSV-файла. Вот некоторые основные параметры, которые можно использовать при вызове этой функции:
filepath_or_buffer(обязательный):import pandas as pd # Чтение данных из CSV-файла my_dataframe = pd.read_csv('путь_к_файлу.csv')- Определяет путь к файлу или URL.
Пример:
sep(по умолчанию,):my_dataframe = pd.read_csv('файл.csv', sep='\t')- Определяет разделитель между данными.
Пример с табуляцией в качестве разделителя:
header(по умолчаниюinfer):- Указывает номер строки, которая содержит заголовки, или использует
infer, чтобы автоматически определить.
Пример с явным указанием строки заголовков:
my_dataframe = pd.read_csv('файл.csv', header=0)- Указывает номер строки, которая содержит заголовки, или использует
names:- Позволяет задать собственные имена для столбцов.
Пример:
my_dataframe = pd.read_csv('файл.csv', names=['Имя', 'Возраст', 'Зарплата'])index_col(по умолчаниюNone):- Указывает номер столбца, который следует использовать в качестве индекса, или
None, если индекс не требуется.
Пример:
- Указывает номер столбца, который следует использовать в качестве индекса, или
skiprows:- Пропускает указанные строки при чтении файла.
Пример:
my_dataframe = pd.read_csv('файл.csv', skiprows=[0, 2, 3])usecols:- Определяет, какие столбцы использовать при чтении данных.
Пример:
my_dataframe = pd.read_csv('файл.csv', usecols=['Имя', 'Возраст'])dtype:- Задает тип данных для столбцов.
Пример:
my_dataframe = pd.read_csv('файл.csv', dtype={'Возраст': 'float64'})
Это только часть параметров. В функции read_csv существует еще множество других параметров, которые позволяют настроить процесс чтения данных в соответствии с конкретными требованиями. При необходимости можно обращаться к официальной документации Pandas для получения подробной информации о всех параметрах функции.
Работа с Excel источниками в Pandas
Класс ExcelFile в библиотеке Pandas предоставляет возможность работы с файлами формата Excel (.xls и .xlsx) без необходимости загрузки всего файла в память. Вместо этого он представляет объект, который может быть использован для чтения данных из листов Excel.
Основные возможности класса ExcelFile:
- Чтение данных из Excel файлов:
ExcelFileпозволяет открыть Excel файл и прочитать данные из него. При этом можно указать определенный лист, который требуется прочитать. - Информация о содержимом: Методы
sheet_namesвозвращает список имен всех листов в файле Excel. Это позволяет предварительно ознакомиться с содержимым файла. - Параллельное чтение данных: При работе с большими файлами, использование
ExcelFileможет быть эффективнее, чем загрузка всего файла в память с помощьюpd.read_excel(), так как он позволяет параллельно читать данные из разных листов.
Пример использования ExcelFile:
import pandas as pd
# Создание объекта ExcelFile
excel_file = pd.ExcelFile('file.xlsx')
# Получение списка имен листов
sheet_names = excel_file.sheet_names
print(sheet_names)
# Чтение данных из конкретного листа
df = excel_file.parse('Sheet1')
# Обработка данных
print(df.head())
В этом примере, 'file.xlsx' — это путь к Excel файлу. Мы создаем объект ExcelFile и используем метод sheet_names для получения списка имен листов. Затем мы читаем данные из листа ‘Sheet1’ с помощью метода parse().
Запись в файл Excel
Класс ExcelWriter в библиотеке Pandas предоставляет возможность записи данных в файлы формата Excel (.xls и .xlsx). Этот класс позволяет создавать новые файлы Excel или дополнять существующие, а также позволяет работать с несколькими листами внутри одного файла.
Основные возможности класса ExcelWriter:
- Создание новых файлов Excel:
ExcelWriterпозволяет создавать новые файлы Excel для записи данных. - Запись данных в файлы Excel: После создания объекта
ExcelWriterможно записывать данные из DataFrame в файл Excel. Это можно делать с помощью методаto_excel()DataFrame. - Работа с несколькими листами:
ExcelWriterпозволяет создавать или записывать данные в несколько листов внутри одного файла Excel. Это может быть полезно при организации данных по различным категориям или при сохранении нескольких DataFrame в один файл. - Управление форматированием:
ExcelWriterпозволяет настраивать различные аспекты форматирования Excel файлов, такие как ширина столбцов, высота строк, формат ячеек и т. д.
Пример использования ExcelWriter:
import pandas as pd
# Создание объекта ExcelWriter и указание пути к файлу
excel_writer = pd.ExcelWriter('output.xlsx')
# Создание DataFrame для записи в Excel
data = {'Name': ['Alice', 'Bob', 'Charlie'],
'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# Запись DataFrame в лист 'Sheet1' файла Excel
df.to_excel(excel_writer, sheet_name='Sheet1', index=False)
# Создание нового листа и запись в него
df2 = pd.DataFrame({'A': [1, 2, 3], 'B': [4, 5, 6]})
df2.to_excel(excel_writer, sheet_name='Sheet2', index=False)
# Сохранение изменений в файл Excel
excel_writer.save()
В этом примере мы создаем объект ExcelWriter с указанием имени файла. Затем мы записываем DataFrame в лист ‘Sheet1’ с помощью метода to_excel(), указывая объект ExcelWriter и имя листа. После этого мы создаем новый лист ‘Sheet2’ и записываем в него другой DataFrame. Наконец, мы сохраняем изменения в файл Excel с помощью метода save().
Основные операции с данными в Pandas
Навигация и просмотр данных
- Просмотр первых и последних строк:
- Используйте методы
head()иtail()для просмотра первых и последних строк соответственно. Это позволяет быстро оценить структуру данных.import pandas as pd # Создание DataFrame для примера data = {'Имя': ['Анна', 'Борис', 'Светлана'], 'Возраст': [25, 30, 22], 'Зарплата': [50000, 70000, 45000]} my_dataframe = pd.DataFrame(data) # Просмотр первых 2 строк print(my_dataframe.head(2)) # Просмотр последних 2 строк print(my_dataframe.tail(2))
- Используйте методы
Имя Возраст Зарплата
0 Анна 25 50000
1 Борис 30 70000
Имя Возраст Зарплата
1 Борис 30 70000
2 Светлана 22 45000- Получение отдельных значений в таблице
- Методы
atиiatв библиотеке Pandas используются для доступа к отдельным значениям в датафрейме по их метке (дляat) или целочисленной позиции (дляiat).Методat:- Параметры:
row_label: метка строки.col_label: метка столбца.
- Пример использования:
import pandas as pd # Создание датафрейма с реальными данными data = { 'A': [1, 2, 3, 4, 5], 'B': [6, 7, 8, 9, 10], 'C': [11, 12, 13, 14, 15] } df = pd.DataFrame(data, index=['a', 'b', 'c', 'd', 'e']) # Получение значения в строке 'b', столбце 'B' с помощью метода at value_at = df.at['b', 'B'] print("Значение в строке 'b', столбце 'B':", value_at)
- Параметры:
- Метод
iat:- Параметры:
row_index: индекс строки (целочисленная позиция).col_index: индекс столбца (целочисленная позиция).
- Пример использования:
import pandas as pd # Создание датафрейма с реальными данными data = { 'A': [1, 2, 3, 4, 5], 'B': [6, 7, 8, 9, 10], 'C': [11, 12, 13, 14, 15] } df = pd.DataFrame(data) # Получение значения в первой строке, втором столбце с помощью метода iat value_iat = df.iat[0, 1] print("Значение в первой строке, втором столбце:", value_iat)
- Параметры:
- Методы
- Получение отдельных строк, столбцов, фрагментов:
- Используйте различные методы для индексации и выборки данных, такие как
loc(для работы с метками) иiloc(для работы с числовыми индексами).# Выбор строки по метке row = my_dataframe.loc[1] # Выбор строки по числовому индексу row = my_dataframe.iloc[1] # Выбор столбца по метке column = my_dataframe['Имя'] # Выбор определенных ячеек value = my_dataframe.at[1, 'Имя'] locв Pandas используется для доступа к группе строк и столбцов по их меткам. Метки могут быть значениями в индексе (строках) или именами столбцов.- Если при создании DataFrame не был явно указан индекс, Pandas создаст целочисленный индекс, начиная с 0. В этом случае метки строк будут значениями целочисленного индекса.
import pandas as pd data = {'Имя': ['Анна', 'Борис', 'Светлана'], 'Возраст': [25, 30, 22], 'Зарплата': [50000, 70000, 45000]} my_dataframe = pd.DataFrame(data) # Использование целочисленных меток индекса first_row = my_dataframe.loc[0] - Метки могут быть явно указаны при создании DataFrame с помощью параметра
index.import pandas as pd data = {'Имя': ['Анна', 'Борис', 'Светлана'], 'Возраст': [25, 30, 22], 'Зарплата': [50000, 70000, 45000]} # Явное указание индекса my_dataframe = pd.DataFrame(data, index=['сотрудник1', 'сотрудник2', 'сотрудник3']) # Использование строковых меток индекса employee2 = my_dataframe.loc['сотрудник2'] - Метки могут также быть использованы для выбора конкретных столбцов.
# Использование меток столбцов age_salary = my_dataframe.loc[:, ['Возраст', 'Зарплата']] - Таким образом, метки берутся из индекса строк или имен столбцов, в зависимости от того, по какому измерению (строки или столбцы) вы осуществляете индексацию. Важно отметить, что при использовании
loc, последний элемент в диапазоне включается в результат, в отличие от среза в Python, где последний элемент исключается. - Взятие диапазона строк и столбцов:

import pandas as pd # Создание DataFrame для примера data = {'Имя': ['Анна', 'Борис', 'Светлана', 'Дмитрий', 'Екатерина'], 'Возраст': [25, 30, 22, 28, 35], 'Зарплата': [50000, 70000, 45000, 60000, 80000]} my_dataframe = pd.DataFrame(data, index=['сотрудник1', 'сотрудник2', 'сотрудник3', 'сотрудник4', 'сотрудник5']) # Использование loc для выбора диапазона строк selected_rows = my_dataframe.loc['сотрудник2':'сотрудник4'] # Использование loc для выбора диапазона строк и столбцов selected_data = my_dataframe.loc['сотрудник2':'сотрудник4', 'Возраст':'Зарплата'] # Вывод результатов print("Выбранные строки:") print(selected_rows) print("\nВыбранные строки и столбцы:") print(selected_data)
- Используйте различные методы для индексации и выборки данных, такие как
Выбранные строки:
Имя Возраст Зарплата
сотрудник2 Борис 30 70000
сотрудник3 Светлана 22 45000
сотрудник4 Дмитрий 28 60000
Выбранные строки и столбцы:
Возраст Зарплата
сотрудник2 30 70000
сотрудник3 22 45000
сотрудник4 28 60000- Просмотр общей информации:
- Используйте методы
info()иdescribe(), а также атрибутаshapeдля получения общей информации о DataFrame.# Вывод общей информации о DataFrame my_dataframe.info() # Вывод статистики по числовым столбцам my_dataframe.describe()<class 'pandas.core.frame.DataFrame'> Index: 5 entries, сотрудник1 to сотрудник5 Data columns (total 3 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Имя 5 non-null object 1 Возраст 5 non-null int64 2 Зарплата 5 non-null int64 dtypes: int64(2), object(1) memory usage: 332.0+ bytes
- Используйте методы
shape: Этот атрибут возвращает кортеж, содержащий количество строк и столбцов DataFrame.
Пример использования:
import pandas as pd
# Создание DataFrame
data = {'Имя': ['Алексей', 'Мария', 'Иван', 'Екатерина', 'Дмитрий']}
df = pd.DataFrame(data)
# Вывод количества строк и столбцов в DataFrame
print(df.shape)
Выбор строк и столбцов.
Выбор строк и столбцов в DataFrame в Pandas можно осуществлять различными способами, включая индексацию, фильтрацию данных и использование булевых условий. Давайте рассмотрим основные методы:
Выбор столбцов:
- По имени столбца:
# Выбор одного столбца по имени column_data = my_dataframe['Имя'] # Выбор нескольких столбцов по списку имен selected_columns = my_dataframe[['Имя', 'Возраст']] - По позиции столбца:
# Выбор одного столбца по позиции column_data = my_dataframe.iloc[:, 0] # Выбор нескольких столбцов по позициям selected_columns = my_dataframe.iloc[:, [0, 1]]
Выбор строк:
- По метке строки (индекс):
# Выбор одной строки по метке row_data = my_dataframe.loc['сотрудник1'] # Выбор нескольких строк по списку меток selected_rows = my_dataframe.loc[['сотрудник1', 'сотрудник3']] - По позиции строки (числовой индекс):
# Выбор одной строки по позиции row_data = my_dataframe.iloc[0] # Выбор нескольких строк по позициям selected_rows = my_dataframe.iloc[[0, 2]]
Получение случайной выборки
Метод sample в Pandas используется для получения случайной выборки из датафрейма. Вот основные параметры метода sample:
n: количество строк, которые вы хотите получить из датафрейма.frac: доля строк, которую вы хотите получить из датафрейма (от 0 до 1).replace: определяет, могут ли строки повторяться в выборке (по умолчанию False).weights: определяет вероятности для каждой строки, чтобы быть выбранной (по умолчанию None).random_state: устанавливает начальное значение для генератора случайных чисел (по умолчанию None).import pandas as pd # Создание датафрейма с реальными данными data = { 'Name': ['John', 'Alice', 'Bob', 'Emma', 'James'], 'Age': [25, 30, 35, 40, 45], 'City': ['New York', 'Los Angeles', 'Chicago', 'Houston', 'Philadelphia'] } df = pd.DataFrame(data) # Получение случайной выборки из датафрейма (3 случайные строки) sample1 = df.sample(n=3) print("Случайная выборка (3 строки):\n", sample1) # Получение случайной выборки из датафрейма (доля выборки) sample2 = df.sample(frac=0.5) print("\nСлучайная выборка (доля выборки):\n", sample2)
Этот код создает небольшой датафрейм с данными о людях и затем использует метод sample, чтобы получить случайную выборку из этого датафрейма. Вы можете использовать параметры метода sample, чтобы настроить размер и характеристики выборки в соответствии с вашими потребностями.
Фильтрация данных
- Фильтрация по условию:
# Фильтрация данных по условию filtered_data = my_dataframe[my_dataframe['Возраст'] > 25] - Использование метода
query():# Фильтрация данных с использованием метода query filtered_data = my_dataframe.query('Возраст > 25 and Зарплата > 50000')
Условия фильтрации:
Можно использовать следующие условия для фильтрации данных:
==(равно)!=(не равно)<(меньше)>(больше)<=(меньше или равно)>=(больше или равно)
Комбинирование условий:
Для комбинирования условий используйте логические операторы & (и), | (или) и ~ (не). Например:
# Комбинирование нескольких условий (И)
result_and = my_dataframe[(my_dataframe['Возраст'] > 25) & (my_dataframe['Зарплата'] > 50000)]
# Комбинирование нескольких условий (ИЛИ)
result_or = my_dataframe[(my_dataframe['Возраст'] > 30) | (my_dataframe['Зарплата'] > 60000)]
# Отрицание условия (НЕ)
result_not = my_dataframe[~(my_dataframe['Имя'] == 'Анна')]
Логические операторы и операторы сравнения. Полный список и описание.
В библиотеке Pandas доступны различные логические операторы и операторы сравнения для работы с данными в датафреймах. Давайте рассмотрим каждый из них:
- И (или логическое И): Обозначается символом
&. ВозвращаетTrue, если оба условия истинны. - ИЛИ (логическое ИЛИ): Обозначается символом
|. ВозвращаетTrue, если хотя бы одно из условий истинно. - НЕ (логическое НЕ): Обозначается символом
~. Используется для инвертирования значения условия. - ИСКЛЮЧАЮЩЕЕ ИЛИ: В Python представлено как
^. В Pandas его нет, но можно использовать логические операторы и инверсию для достижения подобного эффекта. - Равно: Обозначается
==. ВозвращаетTrue, если значения равны. - Не равно: Обозначается
!=. ВозвращаетTrue, если значения не равны. - Больше: Обозначается
>. ВозвращаетTrue, если первое значение больше второго. - Меньше: Обозначается
<. ВозвращаетTrue, если первое значение меньше второго. - Больше или равно: Обозначается
>=. ВозвращаетTrue, если первое значение больше или равно второму. - Меньше или равно: Обозначается
<=. ВозвращаетTrue, если первое значение меньше или равно второму. - Проверка на пустоту: Метод
isna()илиisnull()возвращаетTrue, если значение является пустым (NaN). - Проверка на не пустоту: Метод
notna()илиnotnull()возвращаетTrue, если значение не является пустым (NaN). - Проверка наличия значения в списке: Метод
isin()возвращаетTrue, если значение содержится в заданном списке. - all: Функция
all()возвращаетTrue, если все значения в объекте являютсяTrue. - any: Функция
any()возвращаетTrue, если хотя бы одно значение в объекте являетсяTrue.
Эти операторы и методы могут использоваться для создания условий фильтрации в методе query(), а также для фильтрации данных в обычном синтаксисе Pandas.
Пример использования на датафрейме бронирования авиаблиетов.
import pandas as pd
# Загрузка данных
bookings_df = pd.read_csv('bookings.csv')
# Проверка на пустоту (NaN)
print("Проверка на пустоту (NaN):")
print(bookings_df.isnull().head())
print()
# Проверка на не пустоту (не NaN)
print("Проверка на не пустоту (не NaN):")
print(bookings_df.notnull().head())
print()
# Проверка на наличие значений в списке
print("Проверка на наличие значений в списке:")
print(bookings_df['book_ref'].isin(['00000F', '000012', '000068']).head())
print()
# Проверка, что все значения в объекте истинны
print("Проверка, что все значения в объекте истинны:")
print(bookings_df['book_ref'].notnull().all())
print()
# Проверка, что хотя бы одно значение в объекте истинно
print("Проверка, что хотя бы одно значение в объекте истинно:")
print(bookings_df['book_ref'].notnull().any())
Текстовые фильтры
В Pandas можно создать фильтр «содержит» с помощью метода str.contains() для столбцов типа str и метода apply() с регулярным выражением для более общего случая.
1. Фильтр «содержит» с использованием метода str.contains():
# Создание фильтра для столбца 'column_name', где значения содержат подстроку 'substring'
filter_contains = df['column_name'].str.contains('substring')
Этот метод применяется к столбцам типа str и возвращает булеву серию, где True указывает на то, что значение содержит указанную подстроку, а False указывает на то, что значение не содержит эту подстроку.
2. Фильтр с помощью регулярных выражений с использованием метода apply():
import re
# Создание фильтра с использованием регулярного выражения
pattern = re.compile(r'regex_pattern')
filter_regex = df['column_name'].apply(lambda x: bool(pattern.search(str(x))))
В этом примере regex_pattern должен быть вашим регулярным выражением, которое будет применяться к значениям в столбце column_name. pattern.search(str(x)) ищет совпадения в каждом значении столбца с регулярным выражением.
Затем apply() применяет лямбда-функцию ко всем значениям в столбце, возвращая булеву серию, где True указывает на совпадение с регулярным выражением, а False — на отсутствие совпадения.
Примеры работы с фильтрами
Для примера использования различных методов фильтрации данных на практике возьмем датафрейм с данными о бронированиях авиабилетов из файла bookings.csv. Давайте загрузим данные и выполним несколько операций фильтрации:
import pandas as pd
# Загрузка данных
bookings_df = pd.read_csv('bookings.csv')
# Вывод первых нескольких строк датафрейма
print("До фильтрации:")
print(bookings_df.head())
# Фильтрация данных: выберем только бронирования с общей суммой больше 50 000
filtered_df_1 = bookings_df[bookings_df['total_amount'] > 50000]
# Фильтрация данных: выберем бронирования с датой более ранней, чем 2017-08-01
filtered_df_2 = bookings_df[pd.to_datetime(bookings_df['book_date']).dt.date < pd.to_datetime('2017-08-01').date()]
# Фильтрация данных: выберем бронирования с общей суммой больше 50 000 и совершенные после 2017-07-01
filtered_df_3 = bookings_df[(bookings_df['total_amount'] > 50000) & (pd.to_datetime(bookings_df['book_date']).dt.date > pd.to_datetime('2017-07-01').date())]
# Вывод результатов фильтрации
print("\nПосле фильтрации 1 (бронирования с общей суммой больше 50 000):")
print(filtered_df_1.head())
print("\nПосле фильтрации 2 (бронирования с датой более ранней, чем 2017-08-01):")
print(filtered_df_2.head())
print("\nПосле фильтрации 3 (бронирования с общей суммой больше 50 000 и совершенные после 2017-07-01):")
print(filtered_df_3.head())
Результаты работы фильтров
До фильтрации:
book_ref book_date total_amount
0 00000F 2017-07-05 05:12:00.000 +0500 265700.0
1 000012 2017-07-14 11:02:00.000 +0500 37900.0
2 000068 2017-08-15 16:27:00.000 +0500 18100.0
3 000181 2017-08-10 15:28:00.000 +0500 131800.0
4 0002D8 2017-08-07 23:40:00.000 +0500 23600.0
После фильтрации 1 (бронирования с общей суммой больше 50 000):
book_ref book_date total_amount
0 00000F 2017-07-05 05:12:00.000 +0500 265700.0
11 000374 2017-08-12 12:13:00.000 +0500 136200.0
20 00067B 2017-07-12 04:35:00.000 +0500 296700.0
После фильтрации 2 (бронирования с датой более ранней, чем 2017-08-01):
book_ref book_date total_amount
0 00000F 2017-07-05 05:12:00.000 +0500 265700.0
1 000012 2017-07-14 11:02:00.000 +0500 37900.0
5 0002DB 2017-07-29 08:30:00.000 +0500 101500.0
6 0002E0 2017-07-11 18:09:00.000 +0500 89600.0
7 0002F3 2017-07-10 07:31:00.000 +0500 69600.0
После фильтрации 3 (бронирования с общей суммой больше 50 000 и совершенные после 2017-07-01):
book_ref book_date total_amount
0 00000F 2017-07-05 05:12:00.000 +0500 265700.0
5 0002DB 2017-07-29 08:30:00.000 +0500 101500.0
6 0002E0 2017-07-11 18:09:00.000 +0500 89600.0
7 0002F3 2017-07-10 07:31:00.000 +0500 69600.0
10 000352 2017-07-06 04:02:00.000 +0500 109500.0
Фильтрация с помощью query()
Метод query() в библиотеке Pandas предназначен для фильтрации данных в датафрейме на основе условий, заданных в виде строкового выражения. Этот метод позволяет написать условия фильтрации в виде строки, что делает код более компактным и легким для чтения.
Основные параметры метода query():
expr: Строковое выражение, содержащее условия фильтрации.inplace: Логический параметр, определяющий, изменять ли оригинальный датафрейм или возвращать новый.
Пример использования метода query() с несколькими логическими операторами:
import pandas as pd
# Создание датафрейма
data = {'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
# Фильтрация данных с помощью метода query()
result = df.query('A > 2 & B < 40') # Фильтрация, где значение в столбце A больше 2 и значение в столбце B меньше 40
print(result)
Этот код отфильтрует датафрейм df таким образом, что будут выбраны строки, удовлетворяющие условиям «значение в столбце A больше 2» И «значение в столбце B меньше 40».
Если нужно использовать другие логические операторы, например, или или не, можно использовать соответствующие операторы в строковом выражении. Например:
result = df.query('A > 2 | B == 30') # Фильтрация, где значение в столбце A больше 2 или значение в столбце B равно 30
В этом случае будут выбраны строки, удовлетворяющие условиям «значение в столбце A больше 2» ИЛИ «значение в столбце B равно 30».
Работа с пропущенными значениями
Работа с пропущенными данными (NaN или None) в DataFrame важна при анализе данных, и Pandas предоставляет различные методы для обнаружения и обработки таких значений. Давайте рассмотрим основные аспекты работы с пропущенными данными:
Обнаружение пропущенных значений:
- Метод
isna()иisnull():- Методы возвращают DataFrame той же формы, что и исходный, но с булевыми значениями, где
Trueуказывает на пропущенные значения.# Обнаружение пропущенных значений missing_values = my_dataframe.isna()
- Методы возвращают DataFrame той же формы, что и исходный, но с булевыми значениями, где
- Метод
info():- Метод
info()выводит общую информацию о DataFrame, включая количество непропущенных значений и тип данных каждого столбца.# Вывод информации о DataFrame my_dataframe.info()
- Метод
- Метод
describe():
- Метод
describe()также может использоваться для вывода статистической информации, включая количество непропущенных значений.# Вывод статистики, включая количество непропущенных значений my_dataframe.describe()
- Метод
Обработка пропущенных значений:
- Удаление строк/столбцов с пропущенными значениями:
- Метод
dropna()позволяет удалить строки или столбцы с пропущенными значениями.# Удаление строк с пропущенными значениями my_dataframe_cleaned_rows = my_dataframe.dropna() # Удаление столбцов с пропущенными значениями my_dataframe_cleaned_columns = my_dataframe.dropna(axis=1)
- Метод
- Заполнение пропущенных значений:
- Метод
fillna()используется для заполнения пропущенных значений определенным значением или результатом операции.# Заполнение пропущенных значений средним значением по столбцу mean_age = my_dataframe['Возраст'].mean() my_dataframe_filled = my_dataframe.fillna({'Возраст': mean_age, 'Зарплата': 0})
- Метод
- Интерполяция значений:
- Метод
interpolate()позволяет интерполировать пропущенные значения на основе соседних значений.# Интерполяция пропущенных значений my_dataframe_interpolated = my_dataframe.interpolate()
- Метод
- Замена пропущенных значений другими значениями:
- Метод
replace()может использоваться для замены пропущенных значений другими значениями.# Замена пропущенных значений на -1 my_dataframe_replaced = my_dataframe.replace({pd.NA: -1, None: -1})
- Метод
Параметры функций dropna() и fillna()
dropna()
DataFrame.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)
- axis: Определяет ось, по которой будет производиться удаление пропущенных значений. По умолчанию
axis=0, что означает удаление строк с пропущенными значениями. Еслиaxis=1, то удаляются столбцы. - how: Определяет, какие строки или столбцы удалять. Возможные значения:
'any': Удаляет строки или столбцы, содержащие хотя бы одно пропущенное значение.'all': Удаляет строки или столбцы, содержащие только пропущенные значения.
- thresh: Определяет минимальное количество непропущенных значений, необходимых для сохранения строки или столбца.
- subset: Список столбцов или индексов, для которых нужно рассматривать пропущенные значения при принятии решения о удалении.
- inplace: Если
True, изменения будут применены к самому DataFrame и функция ничего не возвращает. ЕслиFalse(по умолчанию), функция возвращает новый DataFrame без пропущенных значений.
fillna()
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
- value: Значение, которым нужно заполнить пропущенные ячейки.
- method: Метод, который можно использовать для заполнения пропущенных значений. Возможные значения:
'ffill'или'pad': Заполняет пропущенные значения предыдущими ненулевыми значениями.'bfill'или'backfill': Заполняет пропущенные значения следующими ненулевыми значениями.
- axis: Определяет ось, по которой будут заполняться пропущенные значения. По умолчанию (
axis=None) значения заполняются по столбцам. - inplace: Если
True, изменения будут применены к самому DataFrame и функция ничего не возвращает. ЕслиFalse(по умолчанию), функция возвращает новый DataFrame с заполненными значениями. - limit: Определяет максимальное количество последовательных пропущенных значений, которые будут заполнены.
- downcast: Указывает, можно ли понизить типы данных для оптимизации.
Вычисления в данных и применение функций к значениям датафрейма
В Pandas арифметические операции и функции могут быть применены к данным в DataFrame с помощью встроенных методов и функций библиотеки. Основные способы применения арифметических операций и функций к данным в DataFrame:
Арифметические операции:
- Сложение, вычитание, умножение и деление:
- Арифметические операции между DataFrame и другими структурами данных (другими DataFrame, Series, скалярными значениями) происходят поэлементно.
import pandas as pd # Создание DataFrame для примера data = {'A': [1, 2, 3], 'B': [4, 5, 6]} df = pd.DataFrame(data) # Сложение с скаляром result = df + 10 # Вычитание другого DataFrame other_data = {'A': [10, 20, 30], 'B': [40, 50, 60]} other_df = pd.DataFrame(other_data) result = df - other_df # Умножение на Series series = pd.Series([2, 2, 2], index=['A', 'B', 'C']) result = df * series # Деление на число result = df / 2
- Арифметические операции между DataFrame и другими структурами данных (другими DataFrame, Series, скалярными значениями) происходят поэлементно.
Применение функций:
- Применение функции к каждому элементу:
- Используйте метод
apply()для применения функции к каждому элементу в DataFrame.# Применение функции к каждому элементу result = df.apply(lambda x: x ** 2)
- Используйте метод
- Применение функции к столбцам или строкам:
- Используйте параметр
axisдля указания направления применения функции: 0 (по столбцам) или 1 (по строкам).# Применение функции к каждому столбцу result = df.apply(lambda x: x.max()) # Применение функции к каждой строке result = df.apply(lambda x: x.sum(), axis=1)
- Используйте параметр
- Применение встроенных функций:
- Pandas предоставляет множество встроенных функций для анализа данных, таких как
mean(),sum(),min(),max()и другие.# Вычисление среднего значения каждого столбца result = df.mean() # Вычисление суммы по строкам result = df.sum(axis=1)
- Pandas предоставляет множество встроенных функций для анализа данных, таких как
Пример работы с арифметическими операциями и функциями
Для примера работы с арифметическими операциями и применением функций на прикладных данных давайте возьмем данные о билетах из файла tickets.csv. Допустим, что мы хотим добавить новый столбец, который будет содержать количество символов в имени пассажира. Затем мы проведем арифметические операции с данными в этом столбце.
import pandas as pd
# Загрузка данных
tickets_df = pd.read_csv('tickets.csv')
# Функция для подсчета количества символов в имени пассажира
def count_characters(name):
return len(name)
# Применение функции к столбцу 'passenger_name' и создание нового столбца 'name_length'
tickets_df['name_length'] = tickets_df['passenger_name'].apply(count_characters)
# Вывод первых нескольких строк датафрейма с новым столбцом
print("Данные с новым столбцом:")
print(tickets_df.head())
# Пример арифметической операции: сумма длин идентификаторов билетов и идентификаторов пассажиров
total_length = tickets_df['ticket_no'].apply(len).sum() + tickets_df['passenger_id'].apply(len).sum()
print("\nОбщая длина всех идентификаторов билетов и пассажиров:", total_length)
Результаты:
Данные с новым столбцом:
ticket_no book_ref passenger_id passenger_name \
0 0005432000987 06B046 8149 604011 VALERIY TIKHONOV
1 0005432000988 06B046 8499 420203 EVGENIYA ALEKSEEVA
2 0005432000989 E170C3 1011 752484 ARTUR GERASIMOV
3 0005432000990 E170C3 4849 400049 ALINA VOLKOVA
4 0005432000991 F313DD 6615 976589 MAKSIM ZHUKOV
contact_data name_length
0 {"phone": "+70127117011"} 16
1 {"phone": "+70378089255"} 16
2 {"phone": "+70760429203"} 15
3 {"email": "volkova.alina_03101973@po... 11
4 {"email": "m-zhukov061972@postgrespr... 11
Общая длина всех идентификаторов билетов и пассажиров: 179
Как видно из результатов:
- Мы успешно добавили новый столбец «name_length», который содержит количество символов в имени пассажира.
- Проведена арифметическая операция, которая вычисляет сумму длин всех идентификаторов билетов и пассажиров.
Обработка пропущенных данных:
- Обнаружение пропущенных данных:
- Используйте методы
isna()илиisnull()для обнаружения пропущенных значений.# Обнаружение пропущенных значений missing_values = df.isna()
- Используйте методы
- Заполнение пропущенных данных:
- Используйте метод
fillna()для заполнения пропущенных значений определенным значением или методом.# Заполнение пропущенных значений нулями filled_df = df.fillna(0) # Заполнение пропущенных значений средним по столбцу filled_df = df.fillna(df.mean())
- Используйте метод
Пример работы с пропусками
Для демонстрации работы с пропущенными значениями давайте используем данные о рейсах из файла flights.csv. В этих данных возможно наличие пропущенных значений в столбцах «actual_departure» и «actual_arrival», которые указывают на фактическое время вылета и прибытия рейса.
Пример работы с пропущенными значениями будет заключаться в их обнаружении и обработке, например, заполнении пропущенных значений средним или медианным значением времени вылета и прибытия.
import pandas as pd
# Загрузка данных
flights_df = pd.read_csv('flights.csv')
# Вывод информации о пропущенных значениях
print("Информация о пропущенных значениях до обработки:")
print(flights_df.isnull().sum())
# Заполнение пропущенных значений средними значениями времени вылета и прибытия
flights_df['actual_departure'].fillna(flights_df['actual_departure'].mean(), inplace=True)
flights_df['actual_arrival'].fillna(flights_df['actual_arrival'].mean(), inplace=True)
# Вывод информации о пропущенных значениях после обработки
print("\nИнформация о пропущенных значениях после обработки:")
print(flights_df.isnull().sum())
Результаты:
Информация о пропущенных значениях до обработки:
flight_id 0
flight_no 0
scheduled_departure 0
scheduled_arrival 0
departure_airport 0
arrival_airport 0
status 0
aircraft_code 0
actual_departure 2017
actual_arrival 2356
dtype: int64
Информация о пропущенных значениях после обработки:
flight_id 0
flight_no 0
scheduled_departure 0
scheduled_arrival 0
departure_airport 0
arrival_airport 0
status 0
aircraft_code 0
actual_departure 0
actual_arrival 0
dtype: int64
В этом примере мы сначала выявили количество пропущенных значений в каждом столбце с помощью метода isnull().sum(). Затем мы заполнили пропущенные значения средними значениями времени вылета и прибытия с помощью метода fillna() с указанием среднего значения каждого столбца. После обработки пропущенных значений, выводим информацию о пропущенных значениях, чтобы убедиться, что они успешно заполнены.
Конвертация типов данных
Чтобы поменять тип данных у существующего столбца в DataFrame в Pandas, вы можете использовать метод astype() или функцию pd.to_numeric(), pd.to_datetime() или pd.to_timedelta(), в зависимости от типа данных, который вы хотите преобразовать.
Вот примеры использования этих методов:
- Метод
astype():import pandas as pd # Создание DataFrame для примера data = {'A': ['1', '2', '3', '4', '5'], 'B': [1, 2, 3, 4, 5]} df = pd.DataFrame(data) # Преобразование столбца 'A' к числовому типу данных df['A'] = df['A'].astype(int) print(df.dtypes) # Проверка типов данных после преобразования
- Функция
pd.to_numeric():import pandas as pd # Создание DataFrame для примера data = {'A': ['1', '2', '3', '4', '5'], 'B': [1, 2, 3, 4, 5]} df = pd.DataFrame(data) # Преобразование столбца 'A' к числовому типу данных df['A'] = pd.to_numeric(df['A']) print(df.dtypes) # Проверка типов данных после преобразования
- Функция
pd.to_datetime()(пример для преобразования столбца с датами):import pandas as pd # Создание DataFrame для примера data = {'Date': ['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04', '2022-01-05'], 'Value': [1, 2, 3, 4, 5]} df = pd.DataFrame(data) # Преобразование столбца 'Date' к типу данных datetime df['Date'] = pd.to_datetime(df['Date']) print(df.dtypes) # Проверка типов данных после преобразования
- Функция
pd.to_timedelta()(пример для преобразования столбца с временными интервалами):import pandas as pd # Создание DataFrame для примера data = {'Date': ['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04', '2022-01-05'], 'Value': [1, 2, 3, 4, 5]} df = pd.DataFrame(data) # Преобразование столбца 'Date' к типу данных datetime df['Date'] = pd.to_datetime(df['Date']) print(df.dtypes) # Проверка типов данных после преобразования
После выполнения преобразований вы можете проверить типы данных с помощью метода dtypes.
Пример работы с конвертацией данных
Для демонстрации конвертации типов данных и использования категориальных данных давайте возьмем данные о билетах из файла tickets.csv. Допустим, что столбец «fare_conditions» (условия тарифа) может быть конвертирован в категориальный тип данных.
import pandas as pd
# Загрузка данных
tickets_df = pd.read_csv('tickets.csv')
# Вывод информации о типах данных до конвертации
print("Типы данных до конвертации:")
print(tickets_df.dtypes)
# Конвертация типа данных столбца "fare_conditions" в категориальный тип
tickets_df['fare_conditions'] = tickets_df['fare_conditions'].astype('category')
# Вывод информации о типах данных после конвертации
print("\nТипы данных после конвертации:")
print(tickets_df.dtypes)
Результаты:
Типы данных до конвертации:
ticket_no object
book_ref object
passenger_id object
passenger_name object
contact_data object
fare_conditions object
dtype: object
Типы данных после конвертации:
ticket_no object
book_ref object
passenger_id object
passenger_name object
contact_data object
fare_conditions category
dtype: object
Как видно из результатов, столбец «fare_conditions» был успешно конвертирован в категориальный тип данных после использования метода astype('category'). Это позволит оптимизировать использование памяти и улучшить производительность операций с этим столбцом, особенно при работе с большими объемами данных.
Работа с мультииндексом
Мультииндекс (MultiIndex) в Pandas — это инструмент для работы с данными, где индексом может быть несколько уровней, что позволяет организовать иерархическую структуру данных. Мультииндексы особенно полезны для представления многомерных или многотерминальных данных.
Создание мультииндекса:

- Создание мультииндекса при создании DataFrame:
import pandas as pd # Создание DataFrame с мультииндексом data = { ('Группа 1', 'Понедельник'): [10, 20, 30], ('Группа 1', 'Вторник'): [40, 50, 60], ('Группа 2', 'Понедельник'): [70, 80, 90], ('Группа 2', 'Вторник'): [100, 110, 120] } df = pd.DataFrame(data, index=['Иван', 'Мария', 'Алексей']) - Создание мультииндекса из существующего DataFrame:
# Создание мультииндекса из существующего столбца df.set_index(['Группа 1', 'Группа 2'], inplace=True)
Работа с мультииндексами:
- Индексация по мультииндексу:
# Выбор данных по индексу верхнего уровня group1_data = df.loc['Группа 1'] # Выбор данных по индексу нижнего уровня monday_data = df.loc[:, 'Понедельник'] - Переименование индексов:
# Переименование индексов df.index.names = ['Группа', 'День'] - Обращение к данным по мультииндексу:
# Доступ к конкретному значению по индексу value = df.loc[('Группа 1', 'Понедельник'), 'Иван'] - Группировка и агрегирование по мультииндексу:
# Группировка данных по верхнему уровню индекса group1_mean = df.groupby(level='Группа').mean()
Результат работы:
print(df)
Группа Группа 1 Группа 2
День Понедельник Вторник Понедельник Вторник
Иван 10 40 70 100
Мария 20 50 80 110
Алексей 30 60 90 120
В результате выполнения указанных операций мы создали DataFrame с мультииндексом, а также продемонстрировали различные способы работы с данными, включая индексацию, обращение, переименование индексов, группировку и агрегирование данных.
Добавление новых строк:
- Использование метода
append():- Метод
append()позволяет добавить новую строку в DataFrame. Обратите внимание, что он возвращает новый объект DataFrame, поэтому исходный объект остается неизменным.import pandas as pd # Создание DataFrame для примера data = {'Имя': ['Анна', 'Борис'], 'Возраст': [25, 30]} df = pd.DataFrame(data) # Добавление новой строки с помощью append() new_row = pd.Series(['Светлана', 22], index=df.columns) df = df.append(new_row, ignore_index=True)
- Метод
- Использование списков или словарей:
- Можно создать новую строку в виде списка или словаря и добавить ее как новый элемент в DataFrame.
# Создание новой строки в виде списка и добавление ее в DataFrame new_row = ['Светлана', 22] df.loc[len(df)] = new_row # Создание новой строки в виде словаря и добавление ее в DataFrame new_row = {'Имя': 'Светлана', 'Возраст': 22} df = df.append(new_row, ignore_index=True)
- Можно создать новую строку в виде списка или словаря и добавить ее как новый элемент в DataFrame.
Добавление новых столбцов:
- Простое присваивание:
- Новый столбец может быть добавлен простым присваиванием значения или Series.
# Присваивание значения новому столбцу df['Зарплата'] = [50000, 60000, 45000] # Присваивание Series новому столбцу new_column = pd.Series([50000, 60000, 45000], name='Зарплата') df['Зарплата'] = new_column
- Новый столбец может быть добавлен простым присваиванием значения или Series.
- Использование метода
insert():- Метод
insert()позволяет добавить новый столбец на определенную позицию в DataFrame.# Добавление нового столбца на определенную позицию df.insert(loc=1, column='Зарплата', value=[50000, 60000, 45000])
- Метод
Полная программа:
import pandas as pd
# Создание DataFrame для примера
data = {'Имя': ['Анна', 'Борис'],
'Возраст': [25, 30]}
df = pd.DataFrame(data)
# Добавление новой строки с помощью append()
new_row = pd.Series(['Светлана', 22], index=df.columns)
df = df.append(new_row, ignore_index=True)
# Создание новой строки в виде списка и добавление ее в DataFrame
new_row = ['Светлана', 22]
df.loc[len(df)] = new_row
# Создание новой строки в виде словаря и добавление ее в DataFrame
new_row = {'Имя': 'Светлана', 'Возраст': 22}
df = df.append(new_row, ignore_index=True)
# Присваивание значения новому столбцу
df['Зарплата'] = [50000, 60000, 45000]
# Присваивание Series новому столбцу
new_column = pd.Series([50000, 60000, 45000], name='Зарплата')
df['Зарплата'] = new_column
# Добавление нового столбца на определенную позицию
df.insert(loc=1, column='Зарплата', value=[50000, 60000, 45000])
print(df)
Вывод
Имя Зарплата Возраст
0 Анна 50000 25
1 Борис 60000 30
2 Светлана 45000 22
Удаление строк и столбцов
Чтобы удалить строки или столбцы по их индексам или именам (значениям), можно использовать методы drop() для удаления строк и drop(columns=[]) для удаления столбцов. Давайте рассмотрим примеры.
Удаление строк по индексам
import pandas as pd
# Создание DataFrame для примера
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
# Удаление строк по индексам
df.drop([0, 2], inplace=True)
print(df)
Этот код удалит строки с индексами 0 и 2 из DataFrame.
Удаление строк по значениям в столбце
import pandas as pd
# Создание DataFrame для примера
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
# Удаление строк по значениям в столбце
df = df[df['A'] != 2]
print(df)
Этот код удалит строки с индексами 0 и 2 из DataFrame.
Удаление строк по значениям в столбце
import pandas as pd
# Создание DataFrame для примера
data = {'A': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
# Удаление строк по значениям в столбце
df = df[df['A'] != 2]
print(df)
Этот код удалит строки, в которых значение в столбце ‘A’ равно 2.
Удаление столбцов по именам
import pandas as pd
# Создание DataFrame для примера
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)
# Удаление столбцов по именам
df.drop(columns=['B'], inplace=True)
print(df)
Этот код удалит столбец ‘B’ из DataFrame.
Удаление столбцов по индексам
import pandas as pd
# Создание DataFrame для примера
data = {'A': [1, 2, 3], 'B': [4, 5, 6], 'C': [7, 8, 9]}
df = pd.DataFrame(data)
# Удаление столбцов по индексам
df.drop(df.columns[[1]], axis=1, inplace=True)
print(df)
Этот код удалит столбец с индексом 1 из DataFrame.
Обратите внимание, что параметр inplace=True используется для изменения исходного DataFrame. Если inplace=False (по умолчанию), метод drop() вернет новый DataFrame без удаленных строк или столбцов, не изменяя исходный DataFrame.
Переименование столбцов
Чтобы переименовать столбец в Pandas DataFrame, можно использовать метод rename() с параметром columns.
Переименование одного столбца
import pandas as pd
# Создание DataFrame для примера
data = {'old_name': [1, 2, 3], 'B': [4, 5, 6]}
df = pd.DataFrame(data)
# Переименование столбца 'old_name' на 'new_name'
df.rename(columns={'old_name': 'new_name'}, inplace=True)
print(df)
Переименование нескольких столбцов
import pandas as pd
# Создание DataFrame для примера
data = {'old_name_1': [1, 2, 3], 'old_name_2': [4, 5, 6]}
df = pd.DataFrame(data)
# Переименование столбцов 'old_name_1' и 'old_name_2' на 'new_name_1' и 'new_name_2'
df.rename(columns={'old_name_1': 'new_name_1', 'old_name_2': 'new_name_2'}, inplace=True)
print(df)
Обратите внимание, что параметр inplace=True используется для изменения исходного DataFrame. Если inplace=False (по умолчанию), метод rename() вернет новый DataFrame с переименованными столбцами, не изменяя исходный DataFrame.
Вычисляемые столбцы
Чтобы добавить новый столбец в DataFrame в Pandas, вы можете просто присвоить новый столбец и присвоить ему значения, вычисленные на основе значений других столбцов или с использованием функций. Вот несколько примеров:
Пример 1: Добавление столбца с вычисленными значениями:
import pandas as pd
# Создание DataFrame для примера
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
# Добавление нового столбца "C" с вычисленными значениями
df['C'] = df['A'] + df['B']
print(df)
Вывод:
A B C
0 1 4 5
1 2 5 7
2 3 6 9
Пример 2: Добавление столбца с применением функции:
import pandas as pd
# Создание DataFrame для примера
data = {'A': [1, 2, 3],
'B': [4, 5, 6]}
df = pd.DataFrame(data)
# Функция, которая будет применена к столбцам для вычисления нового значения
def custom_function(row):
return row['A'] * 2 + row['B'] * 3
# Добавление нового столбца "C" с применением функции
df['C'] = df.apply(custom_function, axis=1)
print(df)
Вывод:
A B C
0 1 4 14
1 2 5 19
2 3 6 24
Создание вычисляемого столбца с помощью assign()
df.assign:
- Назначение: Создает новые столбцы в DataFrame на основе существующих данных.
- Параметры: Принимает именованные аргументы, где ключи — это названия новых столбцов, а значения — это выражения, определяющие их значения.
- Пример использования:
import pandas as pd # Создаем DataFrame df = pd.DataFrame({'A': [1, 2, 3, 4], 'B': [5, 6, 7, 8]}) # Используем метод assign для создания нового столбца df = df.assign(C=lambda x: x['A'] + x['B']) print(df) - Результат работы
A B C 0 1 5 6 1 2 6 8 2 3 7 10 3 4 8 12
Преобразование столбцов в строки. Метод melt()
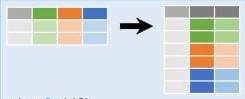
Метод melt в библиотеке Pandas используется для преобразования «широкого» формата данных в «длинный» формат. Этот процесс иногда называют «расплавлением» данных. То есть, имеется много «типовых» столбцов.
Например: у нас есть данные по продажам. Отдельные столбцы — месяцы продаж, в строках — сумма продаж за конкретный месяц. Мы можем, оставить два столбца — сумма продаж и название месяца. Таким образом, данные из столбцов уйдут в строки. Это сделает анализ данных гораздо удобнее. Например, проще будет найти среднюю сумму продаж.
Основная цель melt — сделать данные более удобными для анализа и визуализации, особенно при работе с временными рядами, многомерными данными и данными, собранными в широком формате.
Например, если у нас есть датафрейм, где переменные представлены в столбцах, и каждая строка представляет наблюдение, можно использовать melt, чтобы преобразовать этот формат данных в формат, где переменные будут представлены в столбце «variable», а соответствующие значения — в столбце «value».
Основные параметры метода melt:
- id_vars: Список или кортеж названий столбцов, которые нужно оставить в исходном виде (например, идентификаторы или категории).
- value_vars: Список или кортеж названий столбцов, которые нужно преобразовать в значения в новом столбце.
- var_name: Название нового столбца, в который будут записаны имена переменных из старых столбцов (по умолчанию «variable»).
- value_name: Название нового столбца, в который будут записаны значения переменных (по умолчанию «value»).
Пример использования melt:
Допустим, у нас есть следующий датафрейм с данными о продажах товаров в различных магазинах за разные месяцы:
import pandas as pd
data = {
'Месяц': ['Январь', 'Февраль', 'Март'],
'Магазин A': [1000, 1500, 1200],
'Магазин B': [900, 1400, 1100],
'Магазин C': [1100, 1600, 1300]
}
df = pd.DataFrame(data)
print(df)
Этот датафрейм имеет широкий формат, где каждый месяц представлен в отдельном столбце. Мы можем преобразовать его в длинный формат, используя melt:
melted_df = df.melt(id_vars=['Месяц'], var_name='Магазин', value_name='Продажи')
print(melted_df)
Результат:
Месяц Магазин Продажи
0 Январь Магазин A 1000
1 Февраль Магазин A 1500
2 Март Магазин A 1200
3 Январь Магазин B 900
4 Февраль Магазин B 1400
5 Март Магазин B 1100
6 Январь Магазин C 1100
7 Февраль Магазин C 1600
8 Март Магазин C 1300
Теперь каждая строка содержит информацию о продажах в конкретном месяце и магазине, что делает данные более удобными для анализа.
Задания на закрепление
Для выполнения заданий, скачайте и распакуйте источник данных в папку с вашим Python файлом.
Задание 1. Получите информацию о типах данных в датафрейме.
Задание 2. Выведите первые 5 строк датафрейма.
Задание 3. Выведите список уникальных стран, представленных в датафрейме.
Задание 4. Отфильтруйте строки, где количество подписчиков больше 70 миллионов.
Задание 5. Создайте новый столбец «Total Followers», который будет представлять сумму подписчиков и дополнительных подписчиков бренда (если указано).
Задание 6. Выведите количество аккаунтов из каждой страны.
Задание 7. Переименуйте столбец «Followers (millions)» в «Followers» и удалите лишние символы из значений этого столбца.
Задание 8. Сортируйте датафрейм по убыванию количества подписчиков.
Задание 9. Создайте новый датафрейм, который будет содержать только пользователей из США.
Задание 10. Создайте сводную таблицу, показывающую среднее количество подписчиков для каждой страны.
import pandas as pd
# Загрузка данных
df = pd.read_csv("List of most-followed TikTok accounts (1).csv")
# Задание 1. Получите информацию о типах данных в датафрейме.
print("Задание 1:")
print(df.dtypes)
print()
# Задание 2. Выведите первые 5 строк датафрейма.
print("Задание 2:")
print(df.head())
print()
# Задание 3. Выведите список уникальных стран, представленных в датафрейме.
print("Задание 3:")
print(df['Country'].unique())
print()
# Задание 4. Отфильтруйте строки, где количество подписчиков больше 70 миллионов.
print("Задание 4:")
print(df[df['Followers (millions)'] > 70])
print()
# Задание 5. Создайте новый столбец "Total Followers", который будет представлять сумму подписчиков и дополнительных подписчиков бренда (если указано).
print("Задание 5:")
df['Total Followers'] = df['Followers (millions)'] + df['Brand\nAccount'].fillna(0)
print(df)
print()
# Задание 6. Выведите количество аккаунтов из каждой страны.
print("Задание 6:")
print(df['Country'].value_counts())
print()
# Задание 7. Переименуйте столбец "Followers (millions)" в "Followers" и удалите лишние символы из значений этого столбца.
print("Задание 7:")
df.rename(columns={'Followers (millions)': 'Followers'}, inplace=True)
df['Followers'] = df['Followers'].str.replace(',', '').astype(float)
print(df)
print()
# Задание 8. Сортируйте датафрейм по убыванию количества подписчиков.
print("Задание 8:")
df_sorted = df.sort_values(by='Followers', ascending=False)
print(df_sorted)
print()
# Задание 9. Создайте новый датафрейм, который будет содержать только пользователей из США.
print("Задание 9:")
df_usa = df[df['Country'] == 'United States']
print(df_usa)
print()
# Задание 10. Создайте сводную таблицу, показывающую среднее количество подписчиков для каждой страны.
print("Задание 10:")
pivot_table = df.pivot_table(values='Followers', index='Country', aggfunc='mean')
print(pivot_table)
Сортировка, группировка и агрегация данных в Pandas
Сортировка данных
Простая сортировка по одному полю:
import pandas as pd
# Создание DataFrame для примера
data = {'Name': ['John', 'Alice', 'Bob'],
'Age': [25, 30, 22],
'Salary': [50000, 60000, 45000]}
df = pd.DataFrame(data)
# Простая сортировка по возрасту (по умолчанию - в порядке возрастания)
sorted_df = df.sort_values(by='Age')
print(sorted_df)
Сложная сортировка по нескольким полям:
# Сложная сортировка: сначала по возрасту, затем по зарплате (по умолчанию - в порядке возрастания)
sorted_df = df.sort_values(by=['Age', 'Salary'])
print(sorted_df)
Сортировка, использующая выражения в качестве критерия сравнения:
# Сортировка по длине имени в алфавитном порядке
sorted_df = df.iloc[df['Name'].str.len().sort_values().index]
print(sorted_df)
В этих примерах sort_values() используется для сортировки данных. Метод принимает аргумент by, который может быть именем столбца или списком имен столбцов для сортировки. По умолчанию сортировка происходит в порядке возрастания, но это можно изменить, установив параметр ascending=False. Кроме того, для более сложной сортировки вы можете использовать выражения в качестве критерия сравнения.
Получение наибольших и наименьших значений к столбцу (series)
Методы nsmallest и nlargest в библиотеке Pandas используются для нахождения наименьших или наибольших значений в заданной серии или столбце данных. Эти методы предпочтительны, когда необходимо найти ограниченное количество значений среди большого набора данных, так как они выполняют поиск среди первых n наименьших или наибольших значений, не требуя сортировки всего набора данных.
Обзор основных параметров методов nsmallest и nlargest:
- n: Количество наименьших или наибольших значений, которые нужно найти.
- keep: Указывает, должны ли быть сохранены все значения с одинаковым рангом. Параметр может принимать значения ‘first’, ‘last’ или False. Если ‘first’, сохраняется первое встреченное значение с указанным рангом, если ‘last’ — последнее, если False — все значения удаляются.
Примеры использования методов nsmallest и nlargest:
- Пример использования метода
nsmallest:import pandas as pd # Создание датафрейма с данными data = {'Name': ['John', 'Alice', 'Bob', 'Emily', 'David'], 'Score': [85, 90, 75, 80, 95]} df = pd.DataFrame(data) # Нахождение двух наименьших значений в столбце 'Score' smallest_scores = df['Score'].nsmallest(2) print("Две наименьшие оценки:") print(smallest_scores)Результат:
Две наименьшие оценки: 2 75 3 80 Name: Score, dtype: int64 - Пример использования метода
nlargest:import pandas as pd # Создание датафрейма с данными data = {'Name': ['John', 'Alice', 'Bob', 'Emily', 'David'], 'Score': [85, 90, 75, 80, 95]} df = pd.DataFrame(data) # Нахождение трех наибольших значений в столбце 'Score' largest_scores = df['Score'].nlargest(3) print("Три наибольшие оценки:") print(largest_scores)Результат:
Три наибольшие оценки: 4 95 1 90 0 85 Name: Score, dtype: int64
Таким образом, методы nsmallest и nlargest удобны для быстрого нахождения наименьших или наибольших значений в столбце данных без необходимости полной сортировки всего набора данных.
Получение уникальных значений
Для получения уникальных значений одного или нескольких столбцов в Pandas вы можете использовать метод unique().
Получение уникальных значений одного столбца:
import pandas as pd
# Создание DataFrame для примера
data = {'Name': ['John', 'Alice', 'Bob', 'Alice', 'John'],
'Age': [25, 30, 22, 30, 25]}
df = pd.DataFrame(data)
# Получение уникальных значений столбца "Name"
unique_names = df['Name'].unique()
print(unique_names)
Этот код выведет:
['John' 'Alice' 'Bob']
Получение уникальных значений нескольких столбцов:
# Получение уникальных значений столбцов "Name" и "Age"
unique_values = df[['Name', 'Age']].drop_duplicates()
print(unique_values)
Этот код выведет:
Name Age
0 John 25
1 Alice 30
2 Bob 22
Метод unique() возвращает массив уникальных значений для указанного столбца. Если вам нужно получить уникальные значения из нескольких столбцов, вы можете использовать метод drop_duplicates() после выбора этих столбцов.
import pandas as pd
# Создание DataFrame для примера
data = {'Name': ['John', 'Alice', 'Bob', 'Alice', 'John'],
'Age': [25, 30, 22, 30, 25]}
df = pd.DataFrame(data)
# Получение уникальных значений столбцов "Name" и "Age"
unique_values = df[['Name', 'Age']].drop_duplicates()
print("Уникальные значения столбцов 'Name' и 'Age':")
print(unique_values)
Этот код выведет:
Name Age
0 John 25
1 Alice 30
2 Bob 22
Метод drop_duplicates() удаляет повторяющиеся строки в DataFrame, сохраняя только первое вхождение каждой уникальной строки. В данном случае он сохраняет только уникальные комбинации значений столбцов «Name» и «Age».
Количество уникальных значений
- Метод
nunique()возвращает количество уникальных значений в столбце данных. - Этот метод возвращает число, представляющее количество уникальных значений в столбце.
- Это полезно для быстрой проверки количества уникальных значений в столбце без необходимости создавать массив уникальных значений.
import pandas as pd
data = {'A': [1, 2, 3, 1, 2, 3]}
df = pd.DataFrame(data)
num_unique_values = df['A'].nunique()
print(num_unique_values)
# Output: 3
Агрегатные функции
Агрегатные функции в Pandas позволяют вычислять статистические метрики для данных в DataFrame.
- len(): Этf функция возвращает количество элементов в объекте. Если применяется к DataFrame, он возвращает количество строк.
value_counts(): Этот метод используется для подсчета уникальных значений в столбце или серии данных. Возвращает серию, в которой индексы — уникальные значения, а значения — количество их появлений.Параметры:normalize: если установлен в True, возвращает относительные частоты вместо абсолютных.ascending: если установлен в True, сортирует результаты по возрастанию.
Пример использования:
import pandas as pd # Создание DataFrame data = {'Город': ['Москва', 'Санкт-Петербург', 'Москва', 'Санкт-Петербург', 'Казань']} df = pd.DataFrame(data) # Подсчет количества уникальных значений в столбце "Город" counts = df['Город'].value_counts() print(counts)nunique(): Этот метод возвращает количество уникальных значений в столбце или серии данных.Пример использования:import pandas as pd # Создание DataFrame data = {'Город': ['Москва', 'Санкт-Петербург', 'Москва', 'Санкт-Петербург', 'Казань']} df = pd.DataFrame(data) # Вывод количества уникальных значений в столбце "Город" print(df['Город'].nunique())- sum(): Вычисляет сумму значений в столбце или строке.
- mean(): Вычисляет среднее значение.
- median(): Вычисляет медиану (серединное значение в упорядоченном ряду).
- min(): Находит минимальное значение.
- max(): Находит максимальное значение.
- count(): Подсчитывает количество непустых значений.
- std(): Вычисляет стандартное отклонение (меру разброса данных относительно среднего значения).
- var(): Вычисляет дисперсию (средний квадрат отклонения от среднего).
- agg(): Выполняет пользовательскую агрегацию, применяя одну или несколько агрегатных функций к столбцам или строкам в DataFrame.
- describe(): Предоставляет сводную статистическую информацию о числовых столбцах в DataFrame (среднее, стандартное отклонение, минимум, 25-й, 50-й, и 75-й перцентили, максимум).
- quantile(): Вычисляет квантили (значения, разделяющие упорядоченный набор данных на равные части).
Простая агрегация:
import pandas as pd
# Создание DataFrame для примера
data = {'Name': ['John', 'Alice', 'Bob'],
'Age': [25, 30, 22],
'Salary': [50000, 60000, 45000]}
df = pd.DataFrame(data)
# Вычисление среднего значения зарплаты
mean_salary = df['Salary'].mean()
print("Средняя зарплата:", mean_salary)
# Вычисление суммы возрастов
total_age = df['Age'].sum()
print("Сумма возрастов:", total_age)
# Получение максимального возраста
max_age = df['Age'].max()
print("Максимальный возраст:", max_age)
Множественная агрегация:
# Множественная агрегация: вычисление среднего, суммы и максимального значения для нескольких столбцов
aggregated_data = df.agg({'Age': ['mean', 'sum', 'max'], 'Salary': ['mean', 'sum', 'max']})
print(aggregated_data)
Агрегация с условием:
# Агрегация с условием: вычисление среднего возраста для записей, где зарплата больше 50000
average_age_high_salary = df[df['Salary'] > 50000]['Age'].mean()
print("Средний возраст для зарплаты больше 50000:", average_age_high_salary)
Группировка данных
Группировка данных — это одна из важных операций в анализе данных, позволяющая разделить данные на группы по определенным критериям и применить к каждой группе агрегатные функции или другие операции. В Pandas для этого используется метод groupby().
Разбиение данных на группы:
Для разбиения данных на группы вы указываете столбец(ы), по которым нужно произвести группировку.
import pandas as pd
# Создание DataFrame для примера
data = {'Name': ['John', 'Alice', 'Bob', 'Alice', 'John'],
'Age': [25, 30, 22, 30, 25],
'Salary': [50000, 60000, 45000, 55000, 52000]}
df = pd.DataFrame(data)
# Группировка данных по столбцу "Name"
grouped = df.groupby('Name')
Применение функций к группам:
После группировки вы можете применить агрегатные функции или пользовательские функции к каждой группе.
# Примеры применения агрегатных функций
print(grouped.mean()) # Вычисление средних значений для каждой группы
print(grouped.max()) # Нахождение максимальных значений для каждой группы
print(grouped['Age'].min()) # Нахождение минимального возраста для каждой группы
# Пример применения пользовательской функции
def age_range(group):
return group['Age'].max() - group['Age'].min()
print(grouped.apply(age_range)) # Вычисление диапазона возрастов для каждой группы
Работа с множественными ключами группировки:
Также можно проводить группировку по нескольким столбцам, передав список столбцов в groupby().
# Группировка данных по столбцам "Name" и "Age"
grouped = df.groupby(['Name', 'Age'])
# Примеры применения агрегатных функций
print(grouped.mean()) # Вычисление средних значений для каждой группы
print(grouped.max()) # Нахождение максимальных значений для каждой группы
Применение нескольких функций к группам:
Можно также применять несколько агрегатных функций к группам с помощью метода agg().
# Пример применения нескольких функций к группам
result = grouped['Salary'].agg(['mean', 'sum', 'max'])
print(result)
Функции agg и size
Функция группировки agg (от «aggregate») в библиотеке Pandas позволяет применять одну или несколько агрегирующих функций к данным внутри групп. Она обычно используется вместе с методом groupby для выполнения агрегации на группах данных.
Основные моменты использования agg:
- Применение одной агрегирующей функции к нескольким столбцам:
df.groupby('группировочный столбец').agg({'столбец1': 'агрегирующая_функция1', 'столбец2': 'агрегирующая_функция2'}) - Применение нескольких агрегирующих функций к одному столбцу:
df.groupby('группировочный столбец')['столбец'].agg(['агрегирующая_функция1', 'агрегирующая_функция2']) - Применение различных агрегирующих функций к разным столбцам:
df.groupby('группировочный столбец').agg({'столбец1': 'агрегирующая_функция1', 'столбец2': 'агрегирующая_функция2'}) - Применение пользовательских функций:
def custom_function(x): # логика вашей пользовательской функции return результат df.groupby('группировочный столбец').agg({'столбец': custom_function})
Функция size, с другой стороны, просто возвращает количество элементов в каждой группе, без применения каких-либо агрегирующих функций. Она особенно удобна, когда вам нужно просто посчитать количество элементов в каждой группе без дополнительной обработки.
Пример использования обеих функций:
import pandas as pd
# Создание DataFrame
data = {
'Группа': ['A', 'B', 'A', 'B', 'A'],
'Значение1': [10, 20, 30, 40, 50],
'Значение2': [1, 2, 3, 4, 5]
}
df = pd.DataFrame(data)
# Применение agg для подсчета суммы и среднего по каждой группе
agg_result = df.groupby('Группа').agg({'Значение1': 'sum', 'Значение2': 'mean'})
# Применение size для подсчета количества элементов в каждой группе
size_result = df.groupby('Группа').size()
print("Результат агрегации:")
print(agg_result)
print("\nРезультат подсчета размера:")
print(size_result)
Этот код выведет следующие результаты:
Результат агрегации:
Value1 Value2
Group
A 90 3.0
B 60 3.0
Результат подсчета размера:
Group
A 3
B 2
dtype: int64
В результате агрегации мы получаем сумму значений в столбце Value1 и среднее значение в столбце Value2 для каждой группы. В результате использования size мы получаем количество элементов в каждой группе.
Применение сдвигов, рангов и накопительных подсчетов, совместно с группировкой данных.
Функции shift, rank, cumsum, cummax, cummin, cumprod могут быть применены совместно с группировкой данных для выполнения различных операций над группами данных. Давайте рассмотрим примеры использования каждой из этих функций на прикладных данных:
- shift: Эта функция сдвигает значения в столбце на определенное количество строк. Пример использования:
import pandas as pd # Создаем DataFrame с данными о продажах data = { 'Date': ['2022-01-01', '2022-01-02', '2022-01-03', '2022-01-04'], 'Sales': [100, 150, 200, 250] } df = pd.DataFrame(data) # Добавляем столбец с предыдущими продажами df['Previous_Sales'] = df.groupby(pd.to_datetime(df['Date']).dt.month)['Sales'].shift() print(df)Результат:
Date Sales Previous_Sales 0 2022-01-01 100 NaN 1 2022-01-02 150 100.0 2 2022-01-03 200 150.0 3 2022-01-04 250 200.0 - rank: Эта функция присваивает ранг каждому элементу в группе данных. Пример использования:
# Создаем DataFrame с данными о баллах учеников data = { 'Student': ['Alice', 'Bob', 'Alice', 'Bob'], 'Score': [80, 75, 90, 85] } df = pd.DataFrame(data) # Добавляем столбец с рангом баллов каждого ученика df['Rank'] = df.groupby('Student')['Score'].rank(ascending=False) print(df)Результат:
Student Score Rank 0 Alice 80 2.0 1 Bob 75 2.0 2 Alice 90 1.0 3 Bob 85 1.0 - cumsum, cummax, cummin, cumprod: Эти функции вычисляют кумулятивную (накопительную) сумму, максимум, минимум и произведение для каждой группы данных. Пример использования:
# Создаем DataFrame с данными о продажах data = { 'Month': ['Jan', 'Jan', 'Feb', 'Feb'], 'Sales': [100, 150, 200, 250] } df = pd.DataFrame(data) # Вычисляем кумулятивную сумму продаж для каждого месяца df['Cumulative_Sales'] = df.groupby('Month')['Sales'].cumsum() print(df)Результат:
Month Sales Cumulative_Sales 0 Jan 100 100 1 Jan 150 250 2 Feb 200 200 3 Feb 250 450
Примеры использования rank()
Функция rank() в библиотеке Pandas используется для присвоения рангов значениям внутри группы или DataFrame. Различные параметры этой функции позволяют настраивать способ вычисления рангов. Давайте рассмотрим примеры их использования:
rank(method='dense'): Этот метод присваивает каждому уникальному значению наименьший возможный ранг без пропусков, увеличивая ранг на 1 за каждое новое уникальное значение. Если несколько значений совпадают, они получают один и тот же ранг, который равен наименьшему рангу среди них.rank(method='min'): Этот метод присваивает каждому уникальному значению наименьший возможный ранг без пропусков, но не увеличивает ранг на 1 за каждое новое уникальное значение. Если несколько значений совпадают, они получают один и тот же ранг, который равен наименьшему рангу среди них.rank(pct=True): Этот параметр вычисляет процентные ранги для значений, присваивая каждому значению процент его позиции в группе.rank(method='first'): Этот метод присваивает каждому уникальному значению наименьший возможный ранг без пропусков, увеличивая ранг на 1 за каждое новое уникальное значение. Если несколько значений совпадают, они получают разные ранги, начиная с наименьшего.
Примеры:
import pandas as pd
# Создание DataFrame
df = pd.DataFrame({'A': [1, 2, 2, 3, 4], 'B': [5, 6, 6, 7, 8]})
# Применение rank(method='dense')
df['rank_dense'] = df['A'].rank(method='dense')
# Применение rank(method='min')
df['rank_min'] = df['A'].rank(method='min')
# Применение rank(pct=True)
df['rank_pct'] = df['B'].rank(pct=True)
# Применение rank(method='first')
df['rank_first'] = df['A'].rank(method='first')
print(df)
A B rank_dense rank_min rank_pct rank_first
0 1 5 1.0 1.0 0.2 1.0
1 2 6 2.0 2.0 0.6 2.0
2 2 6 2.0 2.0 0.6 3.0
3 3 7 3.0 4.0 0.8 4.0
4 4 8 4.0 5.0 1.0 5.0
Использование оконных функций
Методы expanding и rolling в Pandas используются для вычисления накопительных статистик и скользящих статистик соответственно.
- Метод
expanding:- Назначение: Рассчитывает накопительные статистики по всему набору данных.
- Параметры:
min_periods: Минимальное количество наблюдений для вычисления статистики.axis: Ось, по которой производятся вычисления.
- Пример использования на прикладных данных. Представим, что у нас есть данные о продажах за несколько месяцев. Мы хотим рассчитать накопительную сумму продаж для каждого месяца.
import pandas as pd # Создание DataFrame с данными о продажах sales_data = { 'Date': pd.date_range(start='2024-01-01', periods=6, freq='M'), 'Sales': [1000, 1500, 800, 2000, 1200, 1700] } sales_df = pd.DataFrame(sales_data) # Рассчет накопительной суммы продаж sales_df['Cumulative Sales'] = sales_df['Sales'].expanding().sum() print(sales_df) - Результат.
Date Sales Cumulative Sales 0 2024-01-31 1000 1000.0 1 2024-02-29 1500 2500.0 2 2024-03-31 800 3300.0 3 2024-04-30 2000 5300.0 4 2024-05-31 1200 6500.0 5 2024-06-30 1700 8200.0
- Метод
rolling:- Назначение: Рассчитывает скользящие статистики на заданном окне.
- Параметры:
window: Размер окна для расчета статистики.min_periods: Минимальное количество наблюдений в окне для вычисления статистики.axis: Ось, по которой производятся вычисления.
- Пример использования на прикладных данных. Представим, что у нас есть данные о температуре за несколько дней. Мы хотим рассчитать скользящее среднее температуры за последние 3 дня.
import pandas as pd # Создание DataFrame с данными о температуре temperature_data = { 'Date': pd.date_range(start='2024-01-01', periods=10), 'Temperature': [20, 22, 24, 21, 23, 25, 27, 26, 28, 30] } temperature_df = pd.DataFrame(temperature_data) # Рассчет скользящего среднего температуры за последние 3 дня temperature_df['Rolling Mean'] = temperature_df['Temperature'].rolling(window=3).mean() print(temperature_df) - Результат.
Date Temperature Rolling Mean 0 2024-01-01 20 NaN 1 2024-01-02 22 NaN 2 2024-01-03 24 22.000000 3 2024-01-04 21 22.333333 4 2024-01-05 23 22.666667 5 2024-01-06 25 23.000000 6 2024-01-07 27 25.000000 7 2024-01-08 26 26.000000 8 2024-01-09 28 27.000000 9 2024-01-10 30 28.000000
Сводные таблицы
Сводные таблицы в Pandas создаются с помощью метода pivot_table(). Сводная таблица представляет собой специальный вид таблицы, который позволяет агрегировать данные по одному или нескольким столбцам и отображать результат в удобном виде.
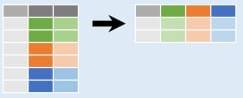
Создание сводной таблицы без указания агрегатной функции:
import pandas as pd
# Создание DataFrame для примера
data = {'Name': ['John', 'Alice', 'Bob', 'Alice', 'John'],
'Age': [25, 30, 22, 30, 25],
'Salary': [50000, 60000, 45000, 55000, 52000]}
df = pd.DataFrame(data)
# Создание сводной таблицы без указания агрегатной функции
pivot_table = df.pivot_table(index='Name', columns='Age')
print(pivot_table)
Этот код создаст сводную таблицу, в которой строки будут отображать уникальные значения столбца «Name», а столбцы — уникальные значения столбца «Age». В значениях таблицы будут находиться значения столбца «Salary».
Создание сводной таблицы с указанием агрегатной функции:
# Создание сводной таблицы с указанием агрегатной функции
pivot_table = df.pivot_table(index='Name', columns='Age', values='Salary', aggfunc='mean')
print(pivot_table)
Здесь мы указали агрегатную функцию mean(), которая будет вычислять среднее значение зарплаты для каждой комбинации «Name» и «Age».
Добавление общего значения (итогов) к сводной таблице:
# Добавление общего значения (итогов) к сводной таблице
pivot_table = df.pivot_table(index='Name', columns='Age', values='Salary', aggfunc='mean', margins=True)
print(pivot_table)
Установив параметр margins=True, мы добавляем итоговые значения по каждому столбцу и каждой строке.
Задания на закрепление
Задание 11. Получите суммарную аудиторию всех блогеров.
Задание 12. Отсортируйте данные по количеству подписчиков (по убыванию).
Задание 13. Найдите количество уникальных стран, представленных в данных.
Задание 14. Подсчитайте количество блогеров из каждой страны.
Задание 15. Выведите среднее количество подписчиков для каждой страны.
Задание 16. Сгруппируйте данные по стране и найдите максимальное количество подписчиков в каждой стране.
Задание 17. Создайте сводную таблицу, где строки — это страны, столбцы — это возраст блогеров, а значения — среднее количество подписчиков.
Задание 18. Добавьте столбец «Процентное соотношение от общего числа подписчиков» и вычислите его для каждого блогера.
Задание 19. Создайте сводную таблицу, где строки — это страны, столбцы — это тип аккаунта (личный или брендовый), а значения — количество блогеров.
Задание 20. Отсортируйте данные по странам и количеству подписчиков в каждой стране (по убыванию).
import pandas as pd
# Загрузка данных
df = pd.read_csv("List of most-followed TikTok accounts (1).csv")
# Задание 11. Получите суммарную аудиторию всех блогеров.
total_followers = df["Followers\n(millions)"].sum()
print("Задание 11: Суммарная аудитория всех блогеров:", total_followers)
# Задание 12. Отсортируйте данные по количеству подписчиков (по убыванию).
sorted_df = df.sort_values(by="Followers\n(millions)", ascending=False)
print("Задание 12:")
print(sorted_df.head())
# Задание 13. Найдите количество уникальных стран, представленных в данных.
unique_countries = df["Country"].nunique()
print("Задание 13: Количество уникальных стран:", unique_countries)
# Задание 14. Подсчитайте количество блогеров из каждой страны.
bloggers_by_country = df["Country"].value_counts()
print("Задание 14:")
print(bloggers_by_country)
# Задание 15. Выведите среднее количество подписчиков для каждой страны.
mean_followers_by_country = df.groupby("Country")["Followers\n(millions)"].mean()
print("Задание 15:")
print(mean_followers_by_country)
# Задание 16. Сгруппируйте данные по стране и найдите максимальное количество подписчиков в каждой стране.
max_followers_by_country = df.groupby("Country")["Followers\n(millions)"].max()
print("Задание 16:")
print(max_followers_by_country)
# Задание 17. Создайте сводную таблицу, где строки - это страны, столбцы - это возраст блогеров, а значения - среднее количество подписчиков.
pivot_table_age_followers = df.pivot_table(index="Country", columns="Age", values="Followers\n(millions)", aggfunc="mean")
print("Задание 17:")
print(pivot_table_age_followers)
# Задание 18. Добавьте столбец "Процентное соотношение от общего числа подписчиков" и вычислите его для каждого блогера.
df["Percentage of Total Followers"] = (df["Followers\n(millions)"] / total_followers) * 100
print("Задание 18:")
print(df.head())
# Задание 19. Создайте сводную таблицу, где строки - это страны, столбцы - это тип аккаунта (личный или брендовый), а значения - количество блогеров.
pivot_table_account_type = df.pivot_table(index="Country", columns="Brand\nAccount", aggfunc="size", fill_value=0)
print("Задание 19:")
print(pivot_table_account_type)
# Задание 20. Отсортируйте данные по странам и количеству подписчиков в каждой стране (по убыванию).
sorted_by_country_followers = df.sort_values(by=["Country", "Followers\n(millions)"], ascending=[True, False])
print("Задание 20:")
print(sorted_by_country_followers)
Объединение и соединение данных
Объединение данных
Функция concat():
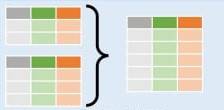
Функция concat() объединяет данные вдоль определенной оси (по умолчанию это ось (axis) 0, т.е. по строкам).
import pandas as pd
# Создание двух DataFrame для примера
df1 = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6]})
df2 = pd.DataFrame({'A': [7, 8, 9],
'B': [10, 11, 12]})
# Объединение по строкам (добавление строк в конец)
result_concat = pd.concat([df1, df2])
print(result_concat)
2. Функция append():
Метод append() добавляет строки другого DataFrame к текущему, аналогично объединению по строкам с помощью concat().
# Добавление строк из df2 к df1
result_append = df1.append(df2)
print(result_append)
Соединение столбцов и индексов:
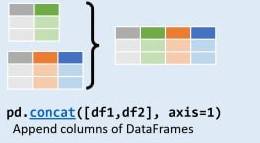
Обе функции могут также использоваться для объединения столбцов или индексов, устанавливая параметр axis=1 для объединения по столбцам и используя метод set_index() для объединения по индексам.
# Объединение по столбцам
result_concat_columns = pd.concat([df1, df2], axis=1)
print(result_concat_columns)
# Объединение по индексам
df1.set_index('A', inplace=True)
df2.set_index('A', inplace=True)
result_concat_index = pd.concat([df1, df2], axis=1)
print(result_concat_index)
Пример работы с результатами:
import pandas as pd
# Создание двух DataFrame для примера
df1 = pd.DataFrame({'A': [1, 2, 3],
'B': [4, 5, 6]})
df2 = pd.DataFrame({'A': [7, 8, 9],
'B': [10, 11, 12]})
# Результаты объединения данных до и после
print("До объединения:")
print(df1)
print(df2)
# Объединение по строкам с использованием concat
result_concat = pd.concat([df1, df2])
print("\nПосле объединения с помощью concat:")
print(result_concat)
# Объединение по строкам с использованием append
result_append = df1.append(df2)
print("\nПосле объединения с помощью append:")
print(result_append)
Результаты:
До объединения:
A B
0 1 4
1 2 5
2 3 6
A B
0 7 10
1 8 11
2 9 12
После объединения с помощью concat:
A B
0 1 4
1 2 5
2 3 6
0 7 10
1 8 11
2 9 12
После объединения с помощью append:
A B
0 1 4
1 2 5
2 3 6
0 7 10
1 8 11
2 9 12
Соединение нескольких датафреймов
В Pandas соединения нескольких датасетов можно выполнять с помощью функции merge(). Эта функция позволяет объединять два или более DataFrame по заданным ключам (столбцам) и типам соединений.
Обзор типов соединений:

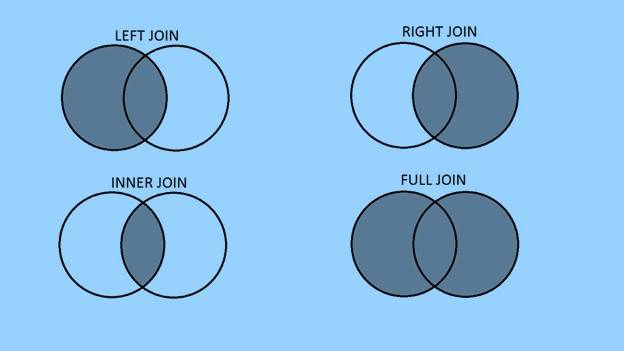
1. Inner Join (внутреннее соединение):
Inner Join объединяет только те строки, для которых есть совпадающие значения в обоих DataFrame по указанным ключам.
2. Outer Join (внешнее соединение):
Outer Join объединяет все строки из обоих DataFrame, заполняя отсутствующие значения NaN, если в одном из DataFrame нет соответствия по указанным ключам.
3. Left Join (левое соединение):
Left Join сохраняет все строки из левого DataFrame и добавляет значения из правого DataFrame, заполняя отсутствующие значения NaN, если соответствия по ключам в правом DataFrame нет.
4. Right Join (правое соединение):
Right Join работает аналогично Left Join, но сохраняет все строки из правого DataFrame и добавляет значения из левого DataFrame.
Примеры работы различных соединений
Предположим, у нас есть два набора данных: один содержит информацию о сотрудниках, а другой — информацию о проектах, над которыми работают эти сотрудники. Давайте посмотрим на примеры их данных и выполним различные типы соединений.
Набор данных о сотрудниках:
import pandas as pd
employees_data = {
'EmployeeID': [101, 102, 103, 104],
'Name': ['John', 'Alice', 'Bob', 'Mary'],
'Department': ['HR', 'Finance', 'IT', 'Marketing']
}
employees_df = pd.DataFrame(employees_data)
print("Данные о сотрудниках:")
print(employees_df)
Данные о сотрудниках:
EmployeeID Name Department
0 101 John HR
1 102 Alice Finance
2 103 Bob IT
3 104 Mary Marketing
Набор данных о проектах:
projects_data = {
'ProjectID': [201, 202, 203, 204],
'ProjectName': ['ProjectA', 'ProjectB', 'ProjectC', 'ProjectD'],
'EmployeeID': [101, 102, 105, 103]
}
projects_df = pd.DataFrame(projects_data)
print("\nДанные о проектах:")
print(projects_df)
Данные о проектах:
ProjectID ProjectName EmployeeID
0 201 ProjectA 101
1 202 ProjectB 102
2 203 ProjectC 105
3 204 ProjectD 103
Inner Join (внутреннее соединение):
inner_join = pd.merge(employees_df, projects_df, on='EmployeeID', how='inner')
print("\nРезультат внутреннего соединения:")
print(inner_join)
Результат внутреннего соединения:
EmployeeID Name Department ProjectID ProjectName
0 101 John HR 201 ProjectA
1 102 Alice Finance 202 ProjectB
3 103 Bob IT 204 ProjectD
Outer Join (внешнее соединение):
outer_join = pd.merge(employees_df, projects_df, on='EmployeeID', how='outer')
print("\nРезультат внешнего соединения:")
print(outer_join)
Результат внешнего соединения:
EmployeeID Name Department ProjectID ProjectName
0 101 John HR 201.0 ProjectA
1 102 Alice Finance 202.0 ProjectB
2 103 Bob IT 204.0 ProjectD
3 104 Mary Marketing NaN NaN
4 105 NaN NaN 203.0 ProjectC
Left Join (левое соединение):
left_join = pd.merge(employees_df, projects_df, on='EmployeeID', how='left')
print("\nРезультат левого соединения:")
print(left_join)
Результат левого соединения:
EmployeeID Name Department ProjectID ProjectName
0 101 John HR 201.0 ProjectA
1 102 Alice Finance 202.0 ProjectB
2 103 Bob IT 204.0 ProjectD
3 104 Mary Marketing NaN NaN
Right Join (правое соединение):
right_join = pd.merge(employees_df, projects_df, on='EmployeeID', how='right')
print("\nРезультат правого соединения:")
print(right_join)
Результат правого соединения:
EmployeeID Name Department ProjectID ProjectName
0 101 John HR 201 ProjectA
1 102 Alice Finance 202 ProjectB
2 103 Bob IT 204 ProjectD
3 105 NaN NaN 203 ProjectC
Из данных примеров можно сделать следующие выводы о различных типах соединений:
- Внутреннее соединение (Inner Join):
- В результате внутреннего соединения попадают только те строки, для которых есть совпадения по ключам в обоих DataFrame. То есть в итоговый датафрейм попали только те сотрудники, которые работают над каким-либо проектом (EmployeeID 101, 102 и 103).
- Внешнее соединение (Outer Join):
- В результате внешнего соединения попадают все строки из обоих DataFrame, причем если для какого-то сотрудника нет соответствующей записи о проекте или наоборот, то в соответствующих столбцах будут значения NaN. Таким образом, в итоговый датафрейм попали все сотрудники и все проекты, но для сотрудника с EmployeeID 104 нет информации о проекте, а для проекта с ProjectID 203 нет информации о сотруднике.
- Левое соединение (Left Join):
- В результате левого соединения попадают все строки из левого DataFrame (employees_df), а также соответствующие строки из правого DataFrame (projects_df), если они существуют. Если для какого-то сотрудника нет соответствующей записи о проекте, то в соответствующих столбцах о проекте будут значения NaN. Таким образом, в итоговый датафрейм попали все сотрудники из employees_df, и информация о проектах добавлена для тех сотрудников, которые над ними работают.
- Правое соединение (Right Join):
- В результате правого соединения попадают все строки из правого DataFrame (projects_df), а также соответствующие строки из левого DataFrame (employees_df), если они существуют. Если для какого-то проекта нет соответствующей записи о сотруднике, то в соответствующих столбцах о сотруднике будут значения NaN. Таким образом, в итоговый датафрейм попали все проекты из projects_df, и информация о сотрудниках добавлена для тех проектов, над которыми они работают.
Параметры функции merge
Основные параметры функции merge и их назначение:
- left: DataFrame или Series.
- Назначение: Левый объект для объединения.
- right: DataFrame или Series.
- Назначение: Правый объект для объединения.
- how: {‘left’, ‘right’, ‘outer’, ‘inner’}, по умолчанию ‘inner’.
- Назначение: Определяет тип объединения.
- Возможные значения:
- ‘left’: Использует ключи из левого DataFrame.
- ‘right’: Использует ключи из правого DataFrame.
- ‘outer’: Использует объединение ключей.
- ‘inner’: Использует пересечение ключей.
- on: label или список.
- Назначение: Название столбца или столбцов, используемых как ключи для объединения.
- Если параметр
onне указан,mergeиспользует пересечение столбцов с одинаковыми именами в обоих DataFrame.
- left_on: label или список.
- Назначение: Название столбца или столбцов в левом DataFrame, используемых как ключи для объединения.
- right_on: label или список.
- Назначение: Название столбца или столбцов в правом DataFrame, используемых как ключи для объединения.
- left_index: bool, по умолчанию False.
- Назначение: Если True, использует индекс левого DataFrame в качестве ключа объединения.
- right_index: bool, по умолчанию False.
- Назначение: Если True, использует индекс правого DataFrame в качестве ключа объединения.
- sort: bool, по умолчанию False.
- Назначение: Сортирует результат по ключам.
- suffixes: tuple, по умолчанию (‘_x’, ‘_y’).
- Назначение: Если в результате объединения появятся столбцы с одинаковыми именами, добавляет суффиксы к их именам.
Фильтрационное соединение с помощью isin()
Можно использовать функцию isin для фильтрации значений одного датафрейма по значениям из другого датафрейма:

adf = {
'x1': ['A', 'B', 'C'],
'x2': [1, 2, 3],
}
bdf = {
'x1': ['A', 'B', 'D'],
'x3': ['T', 'F', 'T'],
}
import pandas as pd
adf = pd.DataFrame(adf)
bdf = pd.DataFrame(bdf)
fdf = adf[adf.x1.isin(bdf.x1)]
fdf2 = adf[~adf.x1.isin(bdf.x1)]
print('adf:', adf, sep = '\n')
print('bdf:', bdf, sep = '\n')
print('fdf:', fdf, sep = '\n')
print('fdf2:', fdf2, sep = '\n')
adf:
x1 x2
0 A 1
1 B 2
2 C 3
bdf:
x1 x3
0 A T
1 B F
2 D T
fdf:
x1 x2
0 A 1
1 B 2
fdf2:
x1 x2
2 C 3Этот пример демонстрирует использование метода isin() для фильтрации данных в DataFrame adf на основе значений столбца x1, которые присутствуют в DataFrame bdf.
- Создаются два DataFrame:
adfиbdf, каждый из которых содержит два столбцаx1иx2дляadfиx1иx3дляbdf. - Затем происходит фильтрация DataFrame
adfс использованием методаisin(). fdf— это подмножествоadf, где значения в столбцеx1присутствуют в столбцеx1DataFramebdf.fdf2— это подмножествоadf, где значения в столбцеx1отсутствуют в столбцеx1DataFramebdf.
Итак, fdf содержит строки из adf, где значение столбца x1 присутствует в bdf, в то время как fdf2 содержит строки, где значение столбца x1 отсутствует в bdf.
Задания на закрепление
Для решения заданий, нам понадобятся новые источники данных: перелеты и аэропорты. Скачайте их и изучите содержимое перед началом выполнения заданий.
Задание 21: Получите название аэропорта вылета и прилета на русском языке для каждого вылета.
Задание 22: Объедините данные из файлов «Перелеты» и «Аэропорты» по кодам аэропортов вылета и прилета.
Задание 23: Получите количество вылетов из каждого города.
Задание 24: Выясните, сколько рейсов в среднем выполняется в день из каждого аэропорта.
Задание 25: Получите список всех аэропортов, из которых рейсы вылетают, но которые не являются аэропортами назначения.
Задание 26: Получите список аэропортов, из которых вылетают рейсы, но в которые не прилетают рейсы.
Задание 27: Соедините данные о перелетах с данными о самолетах, используя коды типов самолетов.
Задание 28: Получите среднее время задержки вылетов по каждому аэропорту вылета.
Задание 29: Объедините данные о перелетах с данными о погоде в каждом аэропорту в момент вылета.
Задание 30: Получите количество вылетов в различных статусах (Scheduled, Departed, Cancelled и т. д.) для каждого аэропорта вылета.
# Решения
# Задание 21
# Получение названия аэропорта вылета и прилета на русском языке для каждого вылета
flights_airports = flights.merge(airports, left_on='departure_airport', right_on='airport_code').merge(airports, left_on='arrival_airport', right_on='airport_code')
flight_info_russian = flights_airports[['airport_name_x', 'airport_name_y']]
# Задание 22
# Объединение данных из файлов "Перелеты" и "Аэропорты" по кодам аэропортов вылета и прилета
flights_airports = flights.merge(airports, left_on='departure_airport', right_on='airport_code').merge(airports, left_on='arrival_airport', right_on='airport_code')
# Задание 23
# Получение количества вылетов из каждого города
departure_city_counts = flights['departure_city'].value_counts()
# Задание 24
# Получение среднего количества рейсов в день из каждого аэропорта
flights['scheduled_departure'] = pd.to_datetime(flights['scheduled_departure'])
flights['departure_date'] = flights['scheduled_departure'].dt.date
flights_per_day_per_airport = flights.groupby(['departure_airport', 'departure_date']).size().groupby('departure_airport').mean()
# Задание 25
# Получение списка аэропортов вылета, но не прилета
departure_only_airports = set(flights['departure_airport']) - set(flights['arrival_airport'])
# Задание 26
# Получение списка аэропортов прилета, но не вылета
arrival_only_airports = set(flights['arrival_airport']) - set(flights['departure_airport'])
# Задание 27
# Соединение данных о перелетах с данными о самолетах
flights_aircraft = flights.merge(aircraft_data, on='aircraft_code')
# Задание 28
# Получение среднего времени задержки вылетов по каждому аэропорту вылета
average_departure_delay = flights.groupby('departure_airport')['departure_delay'].mean()
# Задание 29
# Объединение данных о перелетах с данными о погоде в каждом аэропорту в момент вылета
flights_weather = flights.merge(weather_data, on=['departure_airport', 'departure_date'])
# Задание 30
# Получение количества вылетов в различных статусах для каждого аэропорта вылета
departure_status_counts = flights.groupby(['departure_airport', 'status']).size()
Работа с дубликатами и дублирующими ключами
Работа с дубликатами и дублирующими ключами важна при анализе данных, так как они могут привести к искажениям результатов и неверным выводам.
Работа с дубликатами:
- Поиск дубликатов: Сначала необходимо определить, есть ли в данных дубликаты. Это можно сделать с помощью метода
duplicated()илиdrop_duplicates(). - Удаление дубликатов: После обнаружения дубликатов их можно удалить с помощью метода
drop_duplicates(). При необходимости можно указать столбцы, по которым нужно искать дубликаты, а также опции, контролирующие, какой из дубликатов оставить.
Работа с дублирующими ключами:
- Объединение с дублирующими ключами: Если при объединении двух DataFrame встречаются дублирующие ключи, то в итоговом DataFrame будут присутствовать все комбинации строк для каждого дублирующегося ключа.
- Обработка дублирующих ключей: Если дублирующиеся ключи не представляют интереса и необходимо избежать их в итоговом DataFrame, можно использовать методы
merge()илиjoin(), в которых можно явно указать, каким образом обрабатывать дубликаты ключей (например, с помощью параметраsuffixesилиvalidate). - Удаление дублирующихся ключей: Если дублирующиеся ключи не нужны и могут быть удалены без потери информации, можно использовать методы
drop_duplicates()илиduplicated(), указав столбец с ключами.
Пример работы с дубликатами
Представим, что у нас есть два набора данных: один содержит информацию о заказах, а второй — информацию о клиентах, которые совершили эти заказы.
Набор данных о заказах:
import pandas as pd
orders_data = {
'OrderID': [101, 102, 103, 104, 105, 106, 107],
'CustomerID': [201, 202, 203, 204, 205, 206, 207],
'Product': ['Phone', 'Laptop', 'Tablet', 'Phone', 'Headphones', 'Laptop', 'Phone'],
'Quantity': [1, 1, 2, 1, 1, 2, 1]
}
orders_df = pd.DataFrame(orders_data)
print("Данные о заказах:")
print(orders_df)
Данные о заказах:
OrderID CustomerID Product Quantity
0 101 201 Phone 1
1 102 202 Laptop 1
2 103 203 Tablet 2
3 104 204 Phone 1
4 105 205 Headphones 1
5 106 206 Laptop 2
6 107 207 Phone 1
Набор данных о клиентах:
customers_data = {
'CustomerID': [201, 202, 203, 204, 205, 206, 207],
'Name': ['John', 'Alice', 'Bob', 'Mary', 'David', 'Emma', 'Michael'],
'Email': ['john@example.com', 'alice@example.com', 'bob@example.com', 'mary@example.com',
'david@example.com', 'emma@example.com', 'michael@example.com']
}
customers_df = pd.DataFrame(customers_data)
print("\nДанные о клиентах:")
print(customers_df)
Данные о клиентах:
CustomerID Name Email
0 201 John john@example.com
1 202 Alice alice@example.com
2 203 Bob bob@example.com
3 204 Mary mary@example.com
4 205 David david@example.com
5 206 Emma emma@example.com
6 207 Michael michael@example.com
Поиск дубликатов в данных о заказах:
# Поиск дубликатов в данных о заказах
duplicate_orders = orders_df[orders_df.duplicated()]
print("\nДубликаты в данных о заказах:")
print(duplicate_orders)
Дубликаты в данных о заказах:
Empty DataFrame
Columns: [OrderID, CustomerID, Product, Quantity]
Index: []
Поиск дубликатов в данных о клиентах:
# Поиск дубликатов в данных о клиентах
duplicate_customers = customers_df[customers_df.duplicated()]
print("\nДубликаты в данных о клиентах:")
print(duplicate_customers)
Дубликаты в данных о клиентах:
Empty DataFrame
Columns: [CustomerID, Name, Email]
Index: []
Удаление дубликатов в данных о заказах:
# Удаление дубликатов в данных о заказах
orders_df_unique = orders_df.drop_duplicates()
print("\nДанные о заказах без дубликатов:")
print(orders_df_unique)
Данные о заказах без дубликатов:
OrderID CustomerID Product Quantity
0 101 201 Phone 1
1 102 202 Laptop 1
2 103 203 Tablet 2
3 104 204 Phone 1
4 105 205 Headphones 1
5 106 206 Laptop 2
6 107 207 Phone 1
Объединение данных о заказах и клиентах:
# Объединение данных о заказах и клиентах по CustomerID
merged_data = pd.merge(orders_df, customers_df, on='CustomerID', how='inner')
print("\nОбъединенные данные:")
print(merged_data)
Объединенные данные:
OrderID CustomerID Product Quantity Name Email
0 101 201 Phone 1 John john@example.com
1 102 202 Laptop 1 Alice alice@example.com
2 103 203 Tablet 2 Bob bob@example.com
3 104 204 Phone 1 Mary mary@example.com
4 105 205 Headphones 1 David david@example.com
5 106 206 Laptop 2 Emma emma@example.com
6 107 207 Phone 1 Michael michael@example.com
Обработка дублирующихся ключей при объединении:
# Создание дублирующегося ключа в данных о заказах
orders_data_with_duplicate = {
'OrderID': [101, 102, 103, 104, 101, 106, 107],
'CustomerID': [201, 202, 203, 204, 205, 206, 207],
'Product': ['Phone', 'Laptop', 'Tablet', 'Phone', 'Headphones', 'Laptop', 'Phone'],
'Quantity': [1, 1, 2, 1, 1, 2, 1]
}
orders_df_with_duplicate = pd.DataFrame(orders_data_with_duplicate)
# Объединение данных с дублирующимся ключом
merged_data_with_duplicate = pd.merge(orders_df_with_duplicate, customers_df, on='CustomerID', how='inner')
print("\nОбъединенные данные с дублирующим ключом:")
print(merged_data_with_duplicate)
Объединенные данные с дублирующим ключом:
OrderID CustomerID Product Quantity Name Email
0 101 201 Phone 1 John john@example.com
1 102 202 Laptop 1 Alice alice@example.com
2 103 203 Tablet 2 Bob bob@example.com
3 104 204 Phone 1 Mary mary@example.com
4 101 205 Headphones 1 David david@example.com
5 106 206 Laptop 2 Emma emma@example.com
6 107 207 Phone 1Michael michael@example.com
Удаление дублирующихся ключей в объединенных данных:
# Удаление дублирующихся ключей в объединенных данных
merged_data_unique = merged_data_with_duplicate.drop_duplicates(subset=['OrderID', 'CustomerID'])
print("\nОбъединенные данные без дублирующихся ключей:")
print(merged_data_unique)
Объединенные данные без дублирующихся ключей:
OrderID CustomerID Product Quantity Name Email
0 101 201 Phone 1 John john@example.com
1 102 202 Laptop 1 Alice alice@example.com
2 103 203 Tablet 2 Bob bob@example.com
3 104 204 Phone 1 Mary mary@example.com
4 101 205 Headphones 1 David david@example.com
5 106 206 Laptop 2 Emma emma@example.com
6 107 207 Phone 1Michael michael@example.com
Задания для тренировки
Задание 31: Получите название аэропорта вылета и прилета на русском языке для каждого вылета. Сформируйте удаление дублирующих записей.
Задание 32: Проверьте наличие дубликатов в данных о перелетах и удалите их.
Задание 33: Проверьте наличие дублирующих ключей в данных о перелетах и аэропортах и объедините данные без дублирующих ключей.
Задание 34: Посчитайте количество пропусков в столбцах «actual_departure» и «actual_arrival» в данных о перелетах.
Задание 35: Удалите строки с пропусками в столбцах «actual_departure» и «actual_arrival» из данных о перелетах.
Задание 36: Замените пропуски в столбцах «actual_departure» и «actual_arrival» в данных о перелетах на значения «Scheduled» (запланированное время).
Задание 37: Получите количество дубликатов в данных о перелетах и аэропортах.
Задание 38: Удалите строки с дублирующими значениями в данных о перелетах и аэропортах.
Задание 39: Проверьте уникальность ключей в данных о перелетах и аэропортах.
[spoler title = ‘Решения’]Задание 40: Обработайте дублирующие ключи в данных о перелетах и аэропортах.
# Решения
# Задание 31
# Получение названия аэропорта вылета и прилета на русском языке для каждого вылета
flight_airports = flights.merge(airports, left_on='departure_airport', right_on='airport_code').merge(airports, left_on='arrival_airport', right_on='airport_code')
flight_info_russian = flight_airports[['airport_name_x', 'airport_name_y']]
# Удаление дублирующих записей
flights_no_duplicates = flights.drop_duplicates()
# Задание 32
# Проверка наличия дубликатов и удаление их
flights_no_duplicates = flights.drop_duplicates()
# Задание 33
# Проверка наличия дублирующих ключей и объединение данных без дублирующих ключей
flights_no_duplicates = flights.drop_duplicates()
airports_no_duplicates = airports.drop_duplicates()
# Задание 34
# Подсчет количества пропусков в столбцах "actual_departure" и "actual_arrival"
missing_values_actual_departure = flights['actual_departure'].isnull().sum()
missing_values_actual_arrival = flights['actual_arrival'].isnull().sum()
# Задание 35
# Удаление строк с пропусками в столбцах "actual_departure" и "actual_arrival"
flights_cleaned = flights.dropna(subset=['actual_departure', 'actual_arrival'])
# Задание 36
# Замена пропусков в столбцах "actual_departure" и "actual_arrival" на значения "Scheduled"
flights_filled = flights.fillna({'actual_departure': 'Scheduled', 'actual_arrival': 'Scheduled'})
# Задание 37
# Получение количества дубликатов
duplicate_count_flights = flights.duplicated().sum()
duplicate_count_airports = airports.duplicated().sum()
# Задание 38
# Удаление строк с дублирующими значениями
flights_cleaned = flights.drop_duplicates()
airports_cleaned = airports.drop_duplicates()
# Задание 39
# Проверка уникальности ключей
unique_keys_flights = flights.index.is_unique
unique_keys_airports = airports.index.is_unique
# Задание 40
# Обработка дублирующих ключей
flights.reset_index(inplace=True, drop=True)
airports.reset_index(inplace=True, drop=True)
Статистические метрики и исследование распределения данных
- Среднее (среднее арифметическое):
- Это сумма всех значений, деленная на их количество.
- Пример: Если у вас есть набор чисел [3, 5, 7], то среднее будет (3 + 5 + 7) / 3 = 5.
- В Pandas:
DataFrame.mean()илиSeries.mean().
- Медиана:
- Это значение, которое делит распределение данных на две равные части, где половина значений меньше медианы, а другая половина больше.
- Пример: Для набора чисел [3, 5, 7], медиана будет 5.
- В Pandas:
DataFrame.median()илиSeries.median().
- Стандартное отклонение:
- Это мера разброса данных относительно их среднего значения.
- Чем больше стандартное отклонение, тем больше разброс значений относительно среднего.
- В Pandas:
DataFrame.std()илиSeries.std().
- Квартили:
- Квартили разбивают данные на четыре части, где каждая часть содержит 25% данных.
- 25-й процентиль — это значение, которое меньше или равно 25% значений.
- 50-й процентиль — это медиана.
- 75-й процентиль — это значение, которое меньше или равно 75% значений.
- В Pandas:
DataFrame.quantile(q), гдеq— это желаемый процентиль (например, 0.25, 0.5, 0.75).
Исследование распределения данных:
При исследовании распределения данных обычно проводят следующие шаги:
- Визуализация данных:
- Используйте гистограммы, диаграммы размаха, графики плотности и другие графические методы для визуального представления данных.
- Описательная статистика:
- Рассчитайте основные статистические метрики, такие как среднее, медиана, стандартное отклонение, квартили и т. д.
- Проверка на нормальность:
- Проверьте, имеют ли ваши данные нормальное распределение, используя статистические тесты, такие как тест Шапиро-Уилка или тест Колмогорова-Смирнова.
- Исследование выбросов:
- Определите наличие выбросов в данных, используя диаграммы размаха или критерии для определения выбросов.
- Построение выводов:
- Основываясь на визуализации и описательной статистике, сделайте выводы о характере распределения данных и наличии выбросов или аномалий.
В Pandas все эти шаги можно выполнить с помощью встроенных методов для анализа данных, визуализации и статистики.
Пример простейшего исследования данных
Рассмотрим пример исследования распределения данных на конкретных данных о росте и весе детей. Для начала загрузим данные и ознакомимся с ними:
import pandas as pd
# Загрузка данных о росте и весе детей
data = {
'Age': [6, 7, 8, 9, 10, 11, 12, 13, 14, 15],
'Height_cm': [110, 115, 120, 125, 130, 135, 140, 145, 150, 155],
'Weight_kg': [20, 22, 25, 28, 32, 36, 40, 45, 50, 55]
}
children_df = pd.DataFrame(data)
print(children_df)
Age Height_cm Weight_kg
0 6 110 20
1 7 115 22
2 8 120 25
3 9 125 28
4 10 130 32
5 11 135 36
6 12 140 40
7 13 145 45
8 14 150 50
9 15 155 55Это данные о росте и весе детей в зависимости от их возраста. Теперь мы можем проанализировать распределение данных.
Исследование распределения данных:
- Описательная статистика:
- Среднее значение (mean): это среднее арифметическое значение данных.
- Медиана (median): это значение, которое делит упорядоченный набор данных пополам.
- Стандартное отклонение (standard deviation): это мера разброса данных относительно их среднего значения.
# Описательная статистика для роста и веса детей height_mean = children_df['Height_cm'].mean() height_median = children_df['Height_cm'].median() height_std = children_df['Height_cm'].std() weight_mean = children_df['Weight_kg'].mean() weight_median = children_df['Weight_kg'].median() weight_std = children_df['Weight_kg'].std() print("Распределение роста детей:") print(f"Среднее значение: {height_mean}") print(f"Медиана: {height_median}") print(f"Стандартное отклонение: {height_std}\n") print("Распределение веса детей:") print(f"Среднее значение: {weight_mean}") print(f"Медиана: {weight_median}") print(f"Стандартное отклонение: {weight_std}")
Распределение роста детей:
Среднее значение: 132.5
Медиана: 132.5
Стандартное отклонение: 15.138251770487457
Распределение веса детей:
Среднее значение: 35.3
Медиана: 34.0
Стандартное отклонение: 12.028207587906762Распределение роста детей:
- Среднее значение роста составляет 132.5 см.
- Медиана также равна 132.5 см, что указывает на равномерное распределение значений в наборе данных.
- Стандартное отклонение составляет приблизительно 15.14 см, что означает, что данные отклоняются в среднем на 15.14 см от среднего значения.
Распределение веса детей:
- Среднее значение веса составляет 35.3 кг.
- Медиана равна 34.0 кг, что может указывать на наличие некоторого смещения данных в сторону меньших значений.
- Стандартное отклонение составляет приблизительно 12.03 кг, что означает, что данные отклоняются в среднем на 12.03 кг от среднего значения.
Выводы:
- Распределение роста детей близко к нормальному с небольшим разбросом данных.
- Распределение веса детей имеет некоторое смещение и более широкий разброс, возможно, из-за различий в физиологии детей в данной выборке.
- Гистограмма:
- Гистограмма показывает распределение значений в виде столбцов, где каждый столбец представляет диапазон значений, а высота столбца соответствует количеству наблюдений в этом диапазоне.
import matplotlib.pyplot as plt # Построение гистограммы для роста детей plt.hist(children_df['Height_cm'], bins=5, color='skyblue', edgecolor='black') plt.title('Распределение роста детей') plt.xlabel('Рост (см)') plt.ylabel('Частота') plt.grid(True) plt.show() # Построение гистограммы для веса детей plt.hist(children_df['Weight_kg'], bins=5, color='lightgreen', edgecolor='black') plt.title('Распределение веса детей') plt.xlabel('Вес (кг)') plt.ylabel('Частота') plt.grid(True) plt.show()
- Гистограмма показывает распределение значений в виде столбцов, где каждый столбец представляет диапазон значений, а высота столбца соответствует количеству наблюдений в этом диапазоне.
Гистограммы позволяют визуализировать форму распределения данных и оценить их характер. Например, можно определить, является ли распределение нормальным, равномерным или скошенным.
Равномерное распределение роста:
- Равномерное распределение роста детей может быть связано с тем, что выборка охватывает детей разных возрастов, где каждый возрастный период вносит свой вклад в общую картину. В таком случае, среднее значение и медиана оказываются примерно одинаковыми, что указывает на равномерное распределение данных.
Скошенное распределение веса:
- Скошенное распределение веса детей может быть связано с естественной изменчивостью веса в зависимости от возраста и других факторов, таких как пол, физическая активность, питание и т. д. Возможно, в выборке преобладают дети с определенными физическими характеристиками, что приводит к смещению веса в одну из сторон.
- Среднее значение и медиана отличаются, что указывает на наличие скошенности в распределении данных в сторону более высоких или низких значений.
- Стандартное отклонение также может быть выше в скошенном распределении, так как разброс данных относительно среднего значения может быть больше.
Выводы:
- Равномерное распределение роста детей может свидетельствовать о том, что в выборке представлены дети с различными характеристиками, что может быть характерно для общей популяции детей.
- Скошенное распределение веса может указывать на наличие определенных факторов или особенностей среди детей в выборке, что требует дополнительного изучения для понимания причин смещения веса в одну из сторон.
Задания на закрепление.
Вам предстоит исследовать задержки вылетов и сделать выводы на основании исследования.
Задание 41: Вычислите среднее время задержки вылета (разница между запланированным временем вылета и фактическим временем вылета) и среднее время задержки прилета (разница между запланированным временем прилета и фактическим временем прилета).
Задание 42: Постройте гистограмму распределения задержек вылетов и прилетов.
Задание 43: Вычислите медианное время задержки вылета и прилета.
Задание 44: Определите наиболее частые рейсы с задержками вылетов и прилетов.
Задание 45: Постройте ящик с усами для времени задержек вылетов и прилетов для выявления выбросов.
# Решения
# Задание 41
# Вычисление среднего времени задержки вылета и прилета
flights['departure_delay'] = flights['actual_departure'] - flights['scheduled_departure']
flights['arrival_delay'] = flights['actual_arrival'] - flights['scheduled_arrival']
mean_departure_delay = flights['departure_delay'].mean()
mean_arrival_delay = flights['arrival_delay'].mean()
# Задание 42
# Построение гистограммы распределения задержек вылетов и прилетов
import matplotlib.pyplot as plt
plt.hist(flights['departure_delay'], bins=30, alpha=0.5, label='Departure Delay')
plt.hist(flights['arrival_delay'], bins=30, alpha=0.5, label='Arrival Delay')
plt.xlabel('Delay Time')
plt.ylabel('Frequency')
plt.title('Distribution of Flight Delays')
plt.legend()
plt.show()
# Задание 43
# Вычисление медианного времени задержки вылета и прилета
median_departure_delay = flights['departure_delay'].median()
median_arrival_delay = flights['arrival_delay'].median()
# Задание 44
# Определение наиболее частых причин задержек вылетов и прилетов
common_departure_delays = flights['departure_delay'].value_counts().head(5)
common_arrival_delays = flights['arrival_delay'].value_counts().head(5)
# Задание 45
# Построение ящика с усами для времени задержек вылетов и прилетов
plt.boxplot([flights['departure_delay'], flights['arrival_delay']])
plt.xticks([1, 2], ['Departure Delay', 'Arrival Delay'])
plt.ylabel('Delay Time')
plt.title('Boxplot of Flight Delays')
plt.show()
Какие выводы вы можете сделать, на основе исследования?
Выбросы данных
Выбросы данных — это значения, которые существенно отличаются от остальных в наборе данных.
Они могут быть результатом ошибок ввода, аномалий или просто необычных ситуаций. Удаление или заполнение выбросов зависит от контекста данных и задачи анализа.
- Удаление выбросов: В некоторых случаях, особенно если выбросы являются результатом ошибок или аномалий, их можно безболезненно удалить из набора данных. Для этого можно использовать статистические критерии, такие как удаление всех значений за пределами определенного числа стандартных отклонений от среднего.
- Заполнение выбросов: В других случаях, выбросы могут содержать важную информацию или могут быть реальными, но редкими событиями. В таких случаях можно заполнить выбросы средним или медианой, чтобы не потерять информацию. Или можно использовать методы интерполяции для заполнения выбросов соседними значениями.
Важно помнить, что решение о том, что делать с выбросами, должно приниматься с учетом особенностей данных и цели анализа.
Примеры работы с выбросами
Допустим, у нас есть данные о продажах квартир в определенном городе. Рассмотрим пример такого датафрейма:
import pandas as pd
# Создаем пример данных о продажах квартир
data = {
'Price': [250000, 280000, 320000, 300000, 270000, 310000, 400000, 260000, 295000, 310000, 2000000],
'Area': [120, 140, 130, 125, 135, 128, 145, 122, 138, 131, 150]
}
df = pd.DataFrame(data)
print(df)
Price Area
0 250000 120
1 280000 140
2 320000 130
3 300000 125
4 270000 135
5 310000 128
6 400000 145
7 260000 122
8 295000 138
9 310000 131
10 2000000 150Это пример данных о ценах на квартиры и их площади. В этом датафрейме есть выброс в столбце «Price» — квартира с ценой 2 миллиона, что явно не типично для остальных данных о ценах на квартиры.
Теперь давайте проанализируем выбросы и решим, что с ними делать:
# Посмотрим описательную статистику данных
print(df.describe())
# Найдем выбросы в столбце 'Price' с помощью межквартильного размаха
Q1 = df['Price'].quantile(0.25)
Q3 = df['Price'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['Price'] < lower_bound) | (df['Price'] > upper_bound)]
print("Выбросы в столбце 'Price':")
print(outliers)
# Удаление выбросов
df_cleaned = df[(df['Price'] >= lower_bound) & (df['Price'] <= upper_bound)]
print("Данные без выбросов:")
print(df_cleaned)
Этот код выведет выбросы в столбце ‘Price’ с использованием межквартильного размаха и удалит их из датафрейма.
Таким образом, выброс с ценой в 2 миллиона был удален из данных.
Давайте рассмотрим пример с заполнением выбросов в столбце «Price» средним значением остальных цен на квартиры.
import pandas as pd
# Создаем пример данных о продажах квартир
data = {
'Price': [250000, 280000, 320000, 300000, 270000, 310000, 400000, 260000, 295000, 310000, 2000000],
'Area': [120, 140, 130, 125, 135, 128, 145, 122, 138, 131, 150]
}
df = pd.DataFrame(data)
print("Исходные данные:")
print(df)
# Найдем выбросы в столбце 'Price' с помощью межквартильного размаха
Q1 = df['Price'].quantile(0.25)
Q3 = df['Price'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = df[(df['Price'] < lower_bound) | (df['Price'] > upper_bound)]
print("Выбросы в столбце 'Price':")
print(outliers)
# Заполним выбросы средним значением цен на квартиры
mean_price = df[(df['Price'] >= lower_bound) & (df['Price'] <= upper_bound)]['Price'].mean()
df['Price_filled'] = df['Price'].apply(lambda x: mean_price if (x < lower_bound or x > upper_bound) else x)
print("\nДанные с заполненными выбросами:")
print(df)
В этом примере мы сначала находим выбросы с помощью межквартильного размаха, а затем заполняем их средним значением цен на квартиры.
Таким образом, выброс с ценой в 2 миллиона был заменен средним значением цен на квартиры.
Практическое задание на исследование выбросов
Задание 46. Получите продолжительность всех перелетов. Исследуйте на аномальные данные.
import pandas as pd
# Загрузка данных о перелетах
flights_df = pd.read_csv("flights.csv", sep=";", parse_dates=["scheduled_departure", "scheduled_arrival", "actual_departure", "actual_arrival"])
# Вычисление продолжительности перелетов
flights_df['duration'] = flights_df['actual_arrival'] - flights_df['actual_departure']
# Исследование на выбросы
Q1 = flights_df['duration'].quantile(0.25)
Q3 = flights_df['duration'].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
outliers = flights_df[(flights_df['duration'] < lower_bound) | (flights_df['duration'] > upper_bound)]
print("Аномальные данные (выбросы) в продолжительности перелетов:")
print(outliers)
Смещение данных
Вы можете сместить данные одного столбца относительно другого, используя методы Pandas для работы с DataFrame.
- Используя арифметические операции:
import pandas as pd # Создание DataFrame df = pd.DataFrame({'A': [1, 2, 3, 4, 5], 'B': [6, 7, 8, 9, 10]}) # Смещение столбца 'A' на 1 вверх df['A'] = df['A'].shift(-1)
- Используя методы сдвига:
# Смещение столбца 'A' на 1 вниз df['A'] = df['A'].shift(1)
- Используя присваивание срезов:
# Смещение столбца 'A' на 1 вверх df['A'][:-1] = df['A'][1:].values
- Используя функцию
numpy.roll():import numpy as np # Смещение столбца 'A' на 1 вверх df['A'] = np.roll(df['A'], -1)
Пример работы со смещением
Допустим, у нас есть данные о температуре воздуха за несколько дней, и мы хотим сместить значения температуры на один день вперед
import pandas as pd
# Создаем DataFrame с данными о температуре
data = {'Дата': pd.date_range(start='2024-03-01', periods=5),
'Температура': [20, 22, 18, 25, 23]}
df = pd.DataFrame(data)
# Выводим исходные данные
print("Исходные данные:")
print(df)
# Смещаем значения температуры на один день вперед
df['Температура'] = df['Температура'].shift(-1)
# Выводим результат смещения
print("\nРезультат смещения на один день вперед:")
print(df)
Этот код создает DataFrame с данными о температуре за несколько дней, а затем смещает значения температуры на один день вперед, путем использования метода shift() для столбца ‘Температура’. В результате значения температуры смещаются на один день вперед, а последнее значение удаляется.
Задание 47. Получите продолжительность времени между рейсами для каждой пары аэропортов отправления и прибытия.
import pandas as pd
# Загрузка данных о перелетах
flights = pd.read_csv('flights.csv', sep=';', parse_dates=['scheduled_departure', 'scheduled_arrival'])
# Сортировка данных по аэропорту отправления и времени отправления
flights_sorted = flights.sort_values(by=['departure_airport', 'scheduled_departure'])
# Добавление столбца с продолжительностью времени между рейсами
flights_sorted['duration_between_flights'] = flights_sorted.groupby(['departure_airport', 'arrival_airport'])['scheduled_departure'].diff().fillna(pd.Timedelta(seconds=0))
# Вывод результатов
print(flights_sorted[['departure_airport', 'arrival_airport', 'scheduled_departure', 'duration_between_flights']])
Этот код сначала загружает данные о перелетах и сортирует их по аэропорту отправления и времени отправления. Затем он добавляет новый столбец duration_between_flights, который содержит продолжительность времени между рейсами для каждой пары аэропортов отправления и прибытия. Если между рейсами нет данных о продолжительности (например, для первого рейса), используется значение 0.
Работа с временем и датой в Pandas
В Pandas для работы с датой и временем существуют следующие типы данных:
- datetime64: Этот тип данных представляет комбинацию даты и времени с разрешением до наносекунд. Он обычно используется для хранения меток времени с фиксированным часовым поясом.
- timedelta64: Тип данных timedelta64 представляет разницу между двумя моментами времени. Он может использоваться для выполнения арифметических операций с временными интервалами, такими как сложение, вычитание и смещение времени.
- Period: Этот тип данных используется для представления временного периода фиксированной длины. Например, период может быть одним месяцем, одним днем или одним часом.
- PeriodIndex: Индекс типа PeriodIndex используется для индексации данных временных периодов в структурах данных Pandas, таких как серии и фреймы данных.
Получение даты и времени из датафреймов
Чтобы получить информацию о дате и времени из столбца данных датафрейма в Pandas, можно использовать методы доступа к атрибутам .dt и .dt.strftime().
- Метод доступа к атрибутам
.dt: Этот метод позволяет обращаться к различным атрибутам даты и времени, таким как год, месяц, день, час, минута и т.д. Например:df['datetime_column'].dt.year # Доступ к году df['datetime_column'].dt.month # Доступ к месяцу df['datetime_column'].dt.day # Доступ к дню - Метод `.dt.strftime()«: Этот метод позволяет форматировать дату и время в строку с помощью спецификаторов формата. Например:
df['datetime_column'].dt.strftime('%Y-%m-%d') # Преобразование в строку в формате ГГГГ-ММ-ДД df['datetime_column'].dt.strftime('%H:%M:%S') # Преобразование в строку в формате ЧЧ:ММ:СС
Временные сдвиги
Временные сдвиги и окна — это методы анализа данных, которые используются для работы с временными рядами или последовательностями данных, упорядоченными по времени.
Временные сдвиги: Временные сдвиги позволяют перемещать данные во времени. Например, если у вас есть временной ряд с данными о продажах по месяцам, вы можете сдвинуть его на один месяц вперед или назад. Это может быть полезно, например, для прогнозирования будущих значений на основе прошлых данных или для выявления временных зависимостей между различными переменными.
Скользящие окна: Скользящие окна — это метод вычисления статистик (например, среднего, суммы, стандартного отклонения) для определенного количества последовательных значений временного ряда. Например, если у вас есть временной ряд с данными о цене акций на каждый день, вы можете вычислить скользящее среднее за последние 7 дней. Это позволит вам выявить общие тенденции или сгладить краткосрочные колебания.
Применение временных сдвигов и скользящих окон может помочь вам лучше понять динамику данных во времени и выявить интересные закономерности или тренды.
Пример работы с временными сдвигами
Для примера создадим небольшой DataFrame с данными о ежедневных продажах и применим временный сдвиг для анализа изменений продаж во времени.
import pandas as pd
# Создаем DataFrame с данными о ежедневных продажах
data = {
'date': pd.date_range(start='2022-01-01', end='2022-01-10'),
'sales': [100, 120, 130, 110, 150, 140, 160, 170, 180, 190]
}
df = pd.DataFrame(data)
# Добавляем столбец со сдвинутыми значениями продаж (на один день вперед)
df['shifted_sales'] = df['sales'].shift(periods=1)
# Выводим DataFrame с результатами
print(df)
Этот код создает DataFrame с данными о ежедневных продажах за 10 дней и добавляет новый столбец shifted_sales, в котором хранятся значения продаж, сдвинутые на один день вперед. Результат работы:
date sales shifted_sales
0 2022-01-01 100 NaN
1 2022-01-02 120 100.0
2 2022-01-03 130 120.0
3 2022-01-04 110 130.0
4 2022-01-05 150 110.0
5 2022-01-06 140 150.0
6 2022-01-07 160 140.0
7 2022-01-08 170 160.0
8 2022-01-09 180 170.0
9 2022-01-10 190 180.0
Пример работы со скользящими окнами для вычисления скользящего среднего
Давайте создадим пример на основе данных о ежедневных продажах, чтобы проиллюстрировать работу со скользящими окнами для вычисления скользящего среднего продаж.
Этот код создает DataFrame с данными о ежедневных продажах за 10 дней и добавляет новый столбец rolling_mean, в котором хранятся значения скользящего среднего продаж по окну шириной в 3 дня. Результат работы:
import pandas as pd
# Создаем DataFrame с данными о ежедневных продажах
data = {
'date': pd.date_range(start='2022-01-01', end='2022-01-10'),
'sales': [100, 120, 130, 110, 150, 140, 160, 170, 180, 190]
}
df = pd.DataFrame(data)
# Вычисляем скользящее среднее по окну шириной в 3 дня
df['rolling_mean'] = df['sales'].rolling(window=3).mean()
# Выводим DataFrame с результатами
print(df)
date sales rolling_mean
0 2022-01-01 100 NaN
1 2022-01-02 120 NaN
2 2022-01-03 130 116.666667
3 2022-01-04 110 120.000000
4 2022-01-05 150 130.000000
5 2022-01-06 140 133.333333
6 2022-01-07 160 150.000000
7 2022-01-08 170 156.666667
8 2022-01-09 180 170.000000
9 2022-01-10 190 180.000000
Обратите внимание, что для первых двух строк столбца rolling_mean значения равны NaN, так как для них не существует достаточного количества предыдущих значений для вычисления скользящего среднего.
Временные периоды и временные индексы
Временные периоды в контексте анализа данных обозначают промежутки времени, которые могут быть использованы для агрегации, фильтрации и анализа временных данных. В Pandas временные периоды представлены классом Period и могут быть использованы для работы с временными данными.
Прежде всего, временные периоды можно создать с помощью класса Period. Например, для создания временного периода одного месяца, можно использовать следующий код:
import pandas as pd
# Создание временного периода с помощью Period
period = pd.Period('2022-01', freq='M')
print(period)
Этот код создаст временной период января 2022 года. Параметр freq='M' указывает на то, что это период одного месяца.
Для создания временных индексов в Pandas можно использовать функцию pd.date_range(). Например, чтобы создать временной ряд с шагом в один день за период с января по март 2022 года:
# Создание временного ряда с шагом в один день за период с января по март 2022 года
date_index = pd.date_range(start='2022-01-01', end='2022-03-31', freq='D')
print(date_index)
Этот код создаст временной ряд, состоящий из всех дней с января по март 2022 года.
После создания временных индексов можно использовать их для индексации и фильтрации данных. Например, чтобы выбрать данные только за январь 2022 года:
# Выбор данных только за январь 2022 года
january_data = df.loc['2022-01']
print(january_data)
Этот код выберет все строки из DataFrame df, относящиеся к январю 2022 года.
Также временные периоды можно использовать для группировки и агрегации данных по времени. Например, чтобы вычислить сумму продаж за каждый квартал:
# Группировка и агрегация данных по кварталам
quarterly_sales = df.resample('Q').sum()
print(quarterly_sales)
Этот код сгруппирует данные по кварталам и вычислит сумму продаж за каждый квартал.
Пример работы с временными индексами
Пример работы с временными индексами, диапазонами и периодами на основе данных о ежедневных продажах.
import pandas as pd
# Создаем временной диапазон с ежедневными значениями с января по март 2022 года
date_range = pd.date_range(start='2022-01-01', end='2022-03-31', freq='D')
# Создаем DataFrame с данными о ежедневных продажах
sales_data = {
'sales': [100, 120, 130, 110, 150, 140, 160, 170, 180, 190, 200, 210, 220, 230, 240, 250, 260, 270, 280, 290, 300,
310, 320, 330, 340, 350, 360, 370, 380, 390, 400, 410, 420, 430],
'expenses': [50, 60, 55, 65, 70, 75, 80, 85, 90, 95, 100, 105, 110, 115, 120, 125, 130, 135, 140, 145, 150,
155, 160, 165, 170, 175, 180, 185, 190, 195, 200, 205, 210, 215],
}
df = pd.DataFrame(sales_data, index=date_range)
# Выводим первые 5 строк DataFrame
print(df.head())
Этот код создает DataFrame с данными о ежедневных продажах и расходах с января по март 2022 года. Используя временной диапазон pd.date_range, мы создаем индекс, содержащий ежедневные даты. Затем мы создаем DataFrame, используя этот индекс, и заполняем его данными о продажах и расходах. Результат работы:
sales expenses
2022-01-01 100 50
2022-01-02 120 60
2022-01-03 130 55
2022-01-04 110 65
2022-01-05 150 70
Основные функции и методы для работы с датой и временем
- Создание временных меток:
pd.to_datetime(): Преобразует строковые значения или числовые значения Unix в объектыTimestamp.pd.date_range(): Создает регулярные временные метки на основе заданного диапазона.
- Работа с временным индексом:
DataFrame.set_index(): Устанавливает столбец как индекс, при этом преобразует его во временной индекс.DataFrame.reset_index(): Сбрасывает индекс и преобразует временной индекс обратно в столбец.
- Извлечение информации о времени:
Series.dt.year,Series.dt.month,Series.dt.day: Извлекают год, месяц и день соответственно.Series.dt.hour,Series.dt.minute,Series.dt.second: Извлекают час, минуту и секунду соответственно.Series.dt.weekday: Возвращает день недели в виде числа (0 — понедельник, 6 — воскресенье).Series.dt.strftime(): Преобразует временные метки в строки по заданному формату.
- Сдвиги и смещения:
Series.shift(): Сдвигает значения в серии на указанное количество строк вперед или назад.DataFrame.shift(): Сдвигает значения во всех столбцах DataFrame на указанное количество строк вперед или назад.
- Скользящие окна и агрегации:
Series.rolling(): Выполняет скользящее окно над серией с заданной шириной, позволяя вычислять статистики, такие как среднее или сумма.DataFrame.resample(): Изменяет частоту временного индекса, позволяя агрегировать данные по определенным периодам времени.
- Фильтрация и срезы:
- Использование индексирования: Можно использовать временной индекс для фильтрации данных по дате или времени.
DataFrame.loc[],DataFrame.iloc[]: Позволяют выбирать данные по временному индексу или номеру строки.
- Работа с периодами:
pd.Period(): Создает период времени.Series.dt.to_period(): Преобразует временные метки в периоды.
- Обработка временных данных с разными часовыми поясами:
Series.dt.tz_localize(): Устанавливает часовой пояс для временных меток.Series.dt.tz_convert(): Конвертирует временные метки в другой часовой пояс.
Задания для подготовки
Задание 48. Получите максимальную и минимальную дату перелета.
Задание 49. Вычислите среднее время задержки отправления рейсов.
Задание 50. Вычислите количество перелетов в каждый из дней недели.
Задание 51. Определите самый популярный день для отправления рейсов.
Задание 52. Вычислите среднее время полета для каждого аэропорта отправления.
Задание 53. Подсчитайте количество перелетов для каждого месяца.
Задание 54. Определите аэропорт с самым большим количеством отправленных рейсов.
Задание 55. Найдите день, в который было больше всего задержек отправления.
Задание 56. Вычислите среднее время задержки прибытия для каждого аэропорта прибытия.
Задание 57. Найдите самый популярный час для отправления рейсов.
Задание 58. Вычислите среднее время полета для каждого направления (пара аэропортов).
# Импортируем библиотеки
import pandas as pd
# Загружаем данные
flights = pd.read_csv('flights.csv', sep=';')
# Решение задания 48
# Преобразуем столбцы с датами в формат datetime
flights['scheduled_departure'] = pd.to_datetime(flights['scheduled_departure'])
flights['scheduled_arrival'] = pd.to_datetime(flights['scheduled_arrival'])
# Получаем максимальную и минимальную даты перелета
min_date = flights['scheduled_departure'].min()
max_date = flights['scheduled_departure'].max()
print("Минимальная дата перелета:", min_date)
print("Максимальная дата перелета:", max_date)
# Решение задания 49
# Вычисляем время задержки отправления рейсов
flights['departure_delay'] = flights['actual_departure'] - flights['scheduled_departure']
# Вычисляем среднее время задержки отправления
mean_departure_delay = flights['departure_delay'].mean()
print("Среднее время задержки отправления:", mean_departure_delay)
# Решение задания 50
# Извлекаем день недели из столбца с запланированным отправлением
flights['weekday'] = flights['scheduled_departure'].dt.weekday
# Подсчитываем количество перелетов в каждый из дней недели
flight_count_per_weekday = flights['weekday'].value_counts()
print("Количество перелетов в каждый из дней недели:")
print(flight_count_per_weekday)
# Решение задания 51
# Определяем самый популярный день для отправления рейсов
most_popular_day = flights['weekday'].mode()[0]
print("Самый популярный день для отправления рейсов:", most_popular_day)
# Решение задания 52
# Вычисляем время полета для каждого рейса
flights['flight_duration'] = flights['actual_arrival'] - flights['actual_departure']
# Группируем данные по аэропорту отправления и вычисляем среднее время полета
mean_flight_duration_per_departure_airport = flights.groupby('departure_airport')['flight_duration'].mean()
print("Среднее время полета для каждого аэропорта отправления:")
print(mean_flight_duration_per_departure_airport)
# Решение задания 53
# Извлекаем месяц из столбца с запланированным отправлением
flights['month'] = flights['scheduled_departure'].dt.month
# Подсчитываем количество перелетов для каждого месяца
flight_count_per_month = flights['month'].value_counts()
print("Количество перелетов для каждого месяца:")
print(flight_count_per_month)
# Решение задания 54
# Определяем аэропорт с самым большим количеством отправленных рейсов
most_departures_airport = flights['departure_airport'].value_counts().idxmax()
print("Аэропорт с самым большим количеством отправленных рейсов:", most_departures_airport)
# Решение задания 55
# Создаем временный столбец с флагом задержки отправления
flights['departure_delayed'] = flights['actual_departure'].notnull()
# Группируем данные по дням и подсчитываем количество задержек отправления
day_with_most_departure_delays = flights.groupby(flights['scheduled_departure'].dt.date)['departure_delayed'].sum().idxmax()
print("День, в который было больше всего задержек отправления:", day_with_most_departure_delays)
# Решение задания 56
# Вычисляем время задержки прибытия для каждого рейса
flights['arrival_delay'] = flights['actual_arrival'] - flights['scheduled_arrival']
# Группируем данные по аэропорту прибытия и вычисляем среднее время задержки прибытия
mean_arrival_delay_per_arrival_airport = flights.groupby('arrival_airport')['arrival_delay'].mean()
print("Среднее время задержки прибытия для каждого аэропорта прибытия:")
print(mean_arrival_delay_per_arrival_airport)
# Решение задания 57
# Извлекаем час из столбца с запланированным отправлением
flights['hour'] = flights['scheduled_departure'].dt.hour
# Определяем самый популярный час для отправления рейсов
most_popular_hour = flights['hour'].mode()[0]
print("Самый популярный час для отправления рейсов:", most_popular_hour)
# Решение задания 58
# Вычисляем время полета для каждого рейса
flights['flight_duration'] = flights['actual_arrival'] - flights['actual_departure']
# Группируем данные по направлению (паре аэропортов) и вычисляем среднее время полета
mean_flight_duration_per_route = flights.groupby(['departure_airport', 'arrival_airport'])['flight_duration'].mean()
print("Среднее время полета для каждого направления:")
print(mean_flight_duration_per_route)
Работа с текстом
В Pandas работа с текстовыми данными осуществляется с помощью строковых методов и функций, предоставляемых для объектов типа Series, содержащих текстовую информацию. Ниже представлен обзор основных операций работы с текстовыми данными в Pandas:
- Доступ к строковым методам: В Pandas строковые методы могут быть применены к объектам типа Series с использованием атрибута
.str. - Поиск подстрок: С помощью методов
contains(),startswith(),endswith()можно искать подстроки в тексте и возвращать булеву маску, указывающую на соответствие условию. - Изменение регистра: Строковые методы
lower(),upper()иcapitalize()позволяют преобразовывать текст в нижний, верхний и начальный регистры соответственно. - Разделение и объединение строк: Методы
split()иjoin()используются для разделения строки на подстроки и объединения списка строк в одну строку. - Замена подстрок: Метод
replace()позволяет заменять одну подстроку на другую. - Извлечение подстрок: Методы
slice()иextract()позволяют извлекать подстроки из текста. - Удаление пробелов: Методы
strip(),lstrip()иrstrip()используются для удаления пробельных символов с начала, конца или обоих концов строки. - Проверка наличия определенных символов: Методы
isdigit(),isalpha(),isspace()и другие позволяют проверять строки на наличие цифр, букв, пробелов и т.д.
Пример использования:
import pandas as pd
# Создание DataFrame с текстовыми данными
data = {'text': ['Hello World', 'Python is awesome', 'Data Science']}
df = pd.DataFrame(data)
# Доступ к строковым методам через .str
df['text_lower'] = df['text'].str.lower() # Преобразование к нижнему регистру
df['word_count'] = df['text'].str.split().apply(len) # Подсчет количества слов в каждой строке
df['contains_python'] = df['text'].str.contains('Python') # Проверка наличия подстроки 'Python'
# Вывод результата
print(df)
text text_lower word_count contains_python
0 Hello World hello world 2 False
1 Python is awesome python is awesome 3 True
2 Data Science data science 2 FalseПримеры обработки текста
- Очистка текста от знаков препинания:
import pandas as pd import re # Создание DataFrame с текстовыми данными data = {'text': ['Hello, World!', 'Python is awesome!', 'Data Science, really?']} df = pd.DataFrame(data) # Удаление знаков препинания df['clean_text'] = df['text'].apply(lambda x: re.sub(r'[^\w\s]', '', x)) # Вывод результата print(df)
text clean_text
0 Hello, World! Hello World
1 Python is awesome! Python is awesome
2 Data Science, really? Data Science really- Перевод кириллицы в транслитерацию:
import pandas as pd import transliterate # Создание DataFrame с текстовыми данными data = {'text': ['Привет, мир!', 'Python это здорово!', 'Наука о данных']} df = pd.DataFrame(data) # Перевод кириллицы в транслитерацию df['transliterated_text'] = df['text'].apply(lambda x: transliterate.translit(x, 'ru', reversed=True)) # Вывод результата print(df)
text transliterated_text
0 Привет, мир! Privet, mir!
1 Python это здорово! Python eto zdorovo!
2 Наука о данных Nauka o dannyhСоздание пользовательских функций для работы с данными
- Создание пользовательской функции:
- Определите функцию, которая будет выполнять необходимые операции над данными. В этой функции можно использовать любую логику и методы Pandas для манипуляции данными.
- Обычно пользовательские функции определяются с использованием ключевого слова
def.
- Применение пользовательской функции к датафрейму:
- Используйте методы
.apply()или.applymap()для применения пользовательской функции к датафрейму или отдельным столбцам.
- Используйте методы
Пример создания и применения пользовательской функции к датафрейму:
import pandas as pd
# Пример пользовательской функции для преобразования строки в верхний регистр
def to_uppercase(text):
return text.upper()
# Создание датафрейма с текстовыми данными
data = {'Name': ['John', 'Alice', 'Bob'],
'Age': [25, 30, 35]}
df = pd.DataFrame(data)
# Применение пользовательской функции к столбцу 'Name'
df['Name_upper'] = df['Name'].apply(to_uppercase)
# Вывод результата
print(df)
Этот код создает датафрейм с именами и возрастами, а затем применяет пользовательскую функцию to_uppercase() к столбцу ‘Name’, чтобы преобразовать все имена в верхний регистр. Результат будет содержать новый столбец ‘Name_upper’ с именами в верхнем регистре.
Анонимные функции
В Python анонимные функции создаются с помощью ключевого слова lambda. Они часто используются для создания небольших функций, которые используются в качестве аргументов в других функциях. В Pandas анонимные функции могут быть полезны для быстрой обработки данных без необходимости создания отдельной именованной функции. Вот пример создания и использования анонимной функции в Pandas:
import pandas as pd
# Создание датафрейма с числовыми данными
data = {'A': [1, 2, 3, 4, 5],
'B': [10, 20, 30, 40, 50]}
df = pd.DataFrame(data)
# Применение анонимной функции к столбцу 'A' для умножения каждого значения на 2
df['A_doubled'] = df['A'].apply(lambda x: x * 2)
# Вывод результата
print(df)
В этом примере анонимная функция lambda x: x * 2 используется для умножения каждого значения в столбце ‘A’ на 2. Затем результат сохраняется в новом столбце ‘A_doubled’. В результате получается датафрейм с новым столбцом, содержащим удвоенные значения из столбца ‘A’.
Метод map() для получения категориальных данных
Метод map в библиотеке Pandas используется для преобразования значений в столбце с помощью словаря, серии или функции. Он позволяет заменить каждое значение в столбце на другое значение в соответствии с указанным отображением.
Основные параметры метода map:
- arg: Словарь, серия или функция, используемая для отображения значений.
- na_action: Определяет, как обрабатывать отсутствующие значения. Возможные значения: ‘ignore’ (оставить отсутствующие значения без изменений) или ‘raise’ (вызвать исключение при наличии отсутствующих значений).
Примеры использования метода map:
- Применение словаря для замены значений:
import pandas as pd # Создание датафрейма data = {'Класс': ['A', 'B', 'C', 'A', 'B']} df = pd.DataFrame(data) # Словарь для замены значений mapping = {'A': 'Эконом', 'B': 'Бизнес', 'C': 'Первый'} # Применение метода map для замены значений в столбце 'Класс' df['Класс'] = df['Класс'].map(mapping) print(df)Результат:
Класс 0 Эконом 1 Бизнес 2 Первый 3 Эконом 4 Бизнес - Применение функции для преобразования значений:
import pandas as pd # Создание датафрейма data = {'Оценка': [90, 85, 75, 60, 95]} df = pd.DataFrame(data) # Функция для преобразования оценок в буквенные обозначения def grade_conversion(score): if score >= 90: return 'A' elif score >= 80: return 'B' elif score >= 70: return 'C' elif score >= 60: return 'D' else: return 'F' # Применение метода map с использованием функции для преобразования значений в столбце 'Оценка' df['Оценка'] = df['Оценка'].map(grade_conversion) print(df)Результат:
Оценка 0 A 1 B 2 C 3 D 4 A
Метод cut() для создания категориальных данных
pd.cut:
- Назначение: Разбивает значения на интервалы и присваивает соответствующие метки интервалам.
- Параметры: Принимает массив данных, количество интервалов или границы интервалов, а также другие параметры, такие как метки интервалов.
- Пример использования:
import pandas as pd # Создаем DataFrame df = pd.DataFrame({'Age': [25, 35, 45, 55, 65, 75]}) # Используем метод pd.cut для создания столбца с категориями возрастных групп df['Age_Group'] = pd.cut(df['Age'], bins=[0, 30, 50, 100], labels=['Young', 'Middle-aged', 'Elderly']) print(df) - Результат:
Age Age_Group 0 25 Young 1 35 Middle-aged 2 45 Middle-aged 3 55 Elderly 4 65 Elderly 5 75 Elderly
Разбивка на квантили с помощью qcut()
qcut:
- Назначение: Разбивает значения на квантили с заданным количеством интервалов.
- Параметры: Принимает массив данных, количество интервалов (
q), а также другие параметры, такие как метки квантилей. - Пример использования:
import pandas as pd # Создаем DataFrame с данными data = {'value': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]} df = pd.DataFrame(data) # Используем метод qcut для разделения значений на квантили df['quantile_bins'] = pd.qcut(df['value'], q=4, labels=False) print(df) - Результат:
value quantile_bins 0 1 0 1 2 0 2 3 1 3 4 1 4 5 2 5 6 2 6 7 3 7 8 3 8 9 4 9 10 4
Задание границ значений с помощью clip()
clip:
- Назначение: Ограничивает значения в столбце в пределах заданных границ.
- Параметры: Может принимать значения для минимальной и максимальной границы.
- Пример использования:
import pandas as pd # Создаем DataFrame с данными data = {'value': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]} df = pd.DataFrame(data) # Используем метод clip для ограничения значений в столбце df['clipped_value'] = df['value'].clip(lower=3, upper=7) print(df) - Результат работы:
value clipped_value 0 1 3 1 2 3 2 3 3 3 4 4 4 5 5 5 6 6 6 7 7 7 8 7 8 9 7 9 10 7
Задания на закрепление
Задание 58. Создайте новый столбец в датафрейме аэропортов с названием аэропорта на русском языке.
Задание 59. Очистите текстовые данные в столбце «airport_name» от лишних символов и оставьте только название аэропорта на русском языке.
Задание 60. Напишите функцию для транслитерации текста из кириллицы в латиницу и примените её к столбцу «city» в датафрейме аэропортов.
Задание 61. Создайте новый столбец в датафрейме перелетов, содержащий день недели, когда должен был состояться вылет (scheduled_departure).
Задание 62. Напишите функцию для проверки, является ли статус перелета «Scheduled» и примените её к столбцу «status» в датафрейме перелетов, создав новый столбец с булевыми значениями.
Задание 63. Создайте новый столбец в датафрейме перелетов, содержащий продолжительность каждого перелета (scheduled_duration), вычисленную как разница между запланированным временем прибытия и временем вылета.
Задание 64. Напишите функцию для преобразования временных данных из строки в формат datetime и примените её к столбцам «scheduled_departure» и «scheduled_arrival» в датафрейме перелетов.
Задание 65. Создайте новый столбец в датафрейме перелетов, содержащий информацию о времени задержки (delay), если перелет был задержан, иначе 0.
Задание 66. Напишите функцию для вычисления долготы и широты аэропортов на основе координат в столбце «coordinates» и примените её для создания двух новых столбцов в датафрейме аэропортов.
Задание 67. Создайте новый столбец в датафрейме аэропортов с информацией о временной зоне в формате UTC.
import pandas as pd
import string
# Загрузка данных из файлов
flights_df = pd.read_csv("flights.csv", sep=';', parse_dates=['scheduled_departure', 'scheduled_arrival'])
airports_df = pd.read_csv("airports_data.csv", sep=';', converters={'coordinates': eval})
# Задание 58
airports_df['russian_airport_name'] = airports_df['airport_name'].apply(lambda x: x.split('"ru": "')[1].split('"')[0])
# Задание 59
def clean_airport_name(text):
return text.split('"ru": "')[1].split('"')[0]
airports_df['cleaned_airport_name'] = airports_df['airport_name'].apply(clean_airport_name)
# Задание 60
def transliterate(text):
# Словарь для транслитерации кириллических символов
translit_dict = {'а': 'a', 'б': 'b', 'в': 'v', 'г': 'g', 'д': 'd', 'е': 'e', 'ё': 'yo', 'ж': 'zh', 'з': 'z',
'и': 'i', 'й': 'y', 'к': 'k', 'л': 'l', 'м': 'm', 'н': 'n', 'о': 'o', 'п': 'p', 'р': 'r',
'с': 's', 'т': 't', 'у': 'u', 'ф': 'f', 'х': 'kh', 'ц': 'ts', 'ч': 'ch', 'ш': 'sh', 'щ': 'sch',
'ъ': '', 'ы': 'y', 'ь': '', 'э': 'e', 'ю': 'yu', 'я': 'ya', 'А': 'A', 'Б': 'B', 'В': 'V', 'Г': 'G',
'Д': 'D', 'Е': 'E', 'Ё': 'Yo', 'Ж': 'Zh', 'З': 'Z', 'И': 'I', 'Й': 'Y', 'К': 'K', 'Л': 'L',
'М': 'M', 'Н': 'N', 'О': 'O', 'П': 'P', 'Р': 'R', 'С': 'S', 'Т': 'T', 'У': 'U', 'Ф': 'F', 'Х': 'Kh',
'Ц': 'Ts', 'Ч': 'Ch', 'Ш': 'Sh', 'Щ': 'Sch', 'Ъ': '', 'Ы': 'Y', 'Ь': '', 'Э': 'E', 'Ю': 'Yu', 'Я': 'Ya'}
# Транслитерация текста
translit_text = ''.join([translit_dict.get(char, char) for char in text])
return translit_text
airports_df['transliterated_city'] = airports_df['city'].apply(transliterate)
# Задание 61
flights_df['scheduled_weekday'] = flights_df['scheduled_departure'].dt.weekday_name
# Задание 62
def check_scheduled(status):
return status == 'Scheduled'
flights_df['is_scheduled'] = flights_df['status'].apply(check_scheduled)
# Задание 63
flights_df['scheduled_duration'] = flights_df['scheduled_arrival'] - flights_df['scheduled_departure']
# Задание 64
flights_df['scheduled_departure'] = pd.to_datetime(flights_df['scheduled_departure'])
flights_df['scheduled_arrival'] = pd.to_datetime(flights_df['scheduled_arrival'])
# Задание 65
def calculate_delay(actual_departure, scheduled_departure):
if pd.isnull(actual_departure):
return 0
else:
return (actual_departure - scheduled_departure).seconds // 60
flights_df['delay'] = flights_df.apply(lambda row: calculate_delay(row['actual_departure'], row['scheduled_departure']), axis=1)
# Задание 66
airports_df['longitude'] = airports_df['coordinates'].apply(lambda x: x[0])
airports_df['latitude'] = airports_df['coordinates'].apply(lambda x: x[1])
# Задание 67
from pytz import country_timezones
def get_utc_timezone(timezone):
country_code = timezone.split('/')[0]
try:
return country_timezones(country_code)[0]
except IndexError:
return None
airports_df['utc_timezone'] = airports_df['timezone'].apply(get_utc_timezone)
# Вывод результатов
print(airports_df)
print(flights_df)
Заполнение датафрейма случайными данными
Вы можете заполнить датафрейм случайными данными с помощью библиотеки NumPy.
import pandas as pd
import numpy as np
# Создание пустого датафрейма
df = pd.DataFrame()
# Задание размеров датафрейма
rows = 10
cols = 5
# Заполнение датафрейма случайными значениями
for i in range(cols):
col_name = f"col_{i+1}"
df[col_name] = np.random.randint(0, 100, rows)
# Вывод датафрейма
print(df)
Этот код создает пустой датафрейм и затем заполняет его случайными целыми числами от 0 до 100. Вы можете настроить диапазон случайных значений, а также размеры датафрейма, изменяя параметры rows и cols.
Визуализация данных в Pandas
Pandas предоставляет удобные инструменты для визуализации данных в интеграции с библиотеками визуализации, такими как Matplotlib и Seaborn.
- Matplotlib: Matplotlib является одной из основных библиотек для визуализации данных в Python. Pandas интегрируется с Matplotlib, позволяя использовать функции для построения графиков непосредственно с объектами DataFrame и Series. Например, метод
plot()DataFrame или Series может быть использован для построения графиков различных типов, таких как линейные, столбчатые, круговые диаграммы и гистограммы.
Пример:
import pandas as pd
import matplotlib.pyplot as plt
# Создание DataFrame
data = {'Year': [2010, 2011, 2012, 2013, 2014],
'Revenue': [10000, 12000, 15000, 18000, 20000]}
df = pd.DataFrame(data)
# Построение линейного графика с помощью Matplotlib
df.plot(x='Year', y='Revenue', kind='line')
plt.title('Revenue Over Years')
plt.xlabel('Year')
plt.ylabel('Revenue')
plt.show()
- Seaborn: Seaborn является еще одной библиотекой для визуализации данных в Python, предоставляющей более высокоуровневый интерфейс, чем Matplotlib, и более красивые стандартные графики. Pandas можно использовать вместе с Seaborn для создания более сложных и красивых графиков.
Пример:
import pandas as pd
import seaborn as sns
# Создание DataFrame
data = {'Year': [2010, 2011, 2012, 2013, 2014],
'Revenue': [10000, 12000, 15000, 18000, 20000]}
df = pd.DataFrame(data)
# Построение графика с помощью Seaborn
sns.lineplot(data=df, x='Year', y='Revenue')
plt.title('Revenue Over Years')
plt.xlabel('Year')
plt.ylabel('Revenue')
plt.show()
Оптимизация производительности Pandas
Оптимизация производительности в Pandas может быть критически важной при работе с большими объемами данных.
- Использование правильных типов данных: Выбор правильных типов данных для каждого столбца может значительно уменьшить использование памяти и ускорить операции. Например, использование целочисленных типов данных вместо вещественных или замена строковых значений на категориальные, если количество уникальных значений ограничено.
# До оптимизации df['column_name'] = df['column_name'].astype('float64') # После оптимизации df['column_name'] = df['column_name'].astype('int32') - Предварительная фильтрация данных: Если вам нужно выполнить операции только над подмножеством данных, предварительно отфильтруйте DataFrame, чтобы уменьшить объем данных, с которым нужно работать.
# До оптимизации subset = df[df['column_name'] > threshold] # После оптимизации filtered_df = df[df['column_name'] > threshold] - Использование векторизации: Вместо циклов и итераций попробуйте использовать векторизованные операции Pandas, которые выполняются быстрее и эффективнее.
# До оптимизации for index, row in df.iterrows(): df.at[index, 'new_column'] = row['old_column'] * 2 # После оптимизации df['new_column'] = df['old_column'] * 2 - Использование методов .apply() и .map(): При необходимости выполнения пользовательских операций на столбцах можно использовать методы
.apply()и.map(), которые могут быть более производительными, чем циклы.# До оптимизации df['new_column'] = df['old_column'].apply(lambda x: custom_function(x)) # После оптимизации df['new_column'] = df['old_column'].map(custom_function) - Использование метода .query(): Метод
.query()позволяет писать более читаемый код и может быть более эффективным при выполнении сложных условий фильтрации.# До оптимизации subset = df[(df['column1'] > 0) & (df['column2'] < 100)] # После оптимизации subset = df.query('column1 > 0 and column2 < 100') - Использование метода .nunique(): При работе с категориальными данными, использование метода
.nunique()может быть более эффективным, чем.unique(), особенно для больших DataFrame.# До оптимизации unique_values = df['column_name'].unique() # После оптимизации unique_count = df['column_name'].nunique()
Категориальные данные
Категориальные данные в Pandas представляют собой особый тип данных, который используется для хранения переменных с ограниченным и известным набором уникальных значений. Тип данных category позволяет эффективно использовать память, так как каждое уникальное значение сохраняется только один раз, а затем используется ссылка на это значение для всех экземпляров.
Вот несколько примеров, когда можно использовать категориальные данные:
- Категории товаров или услуг: Если у вас есть столбец, содержащий категории товаров или услуг, то использование типа данных category может быть эффективным, особенно если у вас есть большой набор уникальных категорий.
- Классификация: Категориальные данные могут использоваться для классификации, например, при кодировании уровней образования, категорий дохода или типов занятости.
- Кодирование: Категориальные данные могут быть использованы для кодирования строковых значений, что упрощает сравнение и анализ данных.
Преимущества использования типа данных category:
- Экономия памяти: Использование типа данных category позволяет сократить использование памяти по сравнению с типом данных object или string, особенно при работе с большими объемами данных.
- Улучшенная производительность: Операции с категориальными данными могут выполняться быстрее, чем с данными других типов, так как сокращается количество уникальных значений.
Пример того, как можно преобразовать столбец в категориальный тип данных в Pandas:
import pandas as pd
# Создание DataFrame
data = {'category': ['A', 'B', 'A', 'C', 'B', 'A']}
df = pd.DataFrame(data)
# Преобразование столбца в категориальный тип данных
df['category'] = df['category'].astype('category')
Итоги
- Импорт библиотеки: Всегда импортируйте Pandas в начале скрипта с помощью
import pandas as pd. - Чтение и запись данных: Используйте методы
read_csv(),read_excel(),read_sql(),to_csv(),to_excel(),to_sql()для чтения и записи данных в различных форматах. - Обзор данных: В начале работы с данными выполните обзор с помощью методов
head(),tail(),info(),describe()для получения общей информации о структуре и содержимом DataFrame. - Обработка пропущенных значений: Используйте методы
isnull(),notnull(),dropna(),fillna()для работы с пропущенными значениями. - Выборка данных: Используйте методы индексации и фильтрации, такие как
loc[]иiloc[], для выборки данных по меткам и позициям. - Добавление и удаление столбцов: Добавляйте новые столбцы с помощью простого присваивания значений. Удаляйте столбцы с помощью метода
drop(). - Группировка и агрегация: Используйте методы
groupby()и агрегатные функции, такие какsum(),mean(),count(),max(),min()для группировки и агрегации данных. - Объединение данных: Используйте методы
merge(),join(),concat()для объединения данных из разных источников. - Визуализация данных: Используйте интеграцию Pandas с библиотеками визуализации, такими как Matplotlib и Seaborn, для создания информативных графиков и диаграмм.
- Оптимизация производительности: При работе с большими объемами данных используйте методы оптимизации производительности, такие как использование типа данных
category, предварительная фильтрация данных перед операциями и выборка только необходимых столбцов.
Проектное задание
Проектное задание: «Анализ данных авиакомпании». Данные можно скачать по ссылке.
Цель проекта: Анализировать данные авиакомпании для выявления основных трендов и паттернов, помогающих принимать решения по улучшению бизнеса и оптимизации ресурсов.
Шаги проекта:
- Загрузка и предобработка данных:
- Загрузить данные из всех CSV файлов.
- Преобразовать необходимые столбцы в соответствующие типы данных (например, даты).
- Обработать отсутствующие значения и дубликаты, если они есть.
- Исследовательский анализ данных:
- Провести анализ количества перелетов по направлениям и времени.
- Изучить популярные направления и их динамику.
- Проверить распределение билетов по классам обслуживания и выручку от них.
- Оценить загруженность рейсов и аэропортов.
- Анализ бронирований и продаж:
- Изучить общее количество бронирований и их динамику по времени.
- Оценить средний чек и выручку от бронирований.
- Изучить поведение пассажиров (частота покупок, популярные направления).
- Сегментация пассажиров:
- Провести сегментацию пассажиров на основе данных о бронированиях и полетах.
- Определить наиболее ценные сегменты для компании.
- Прогнозирование спроса (выходит за рамки данной статьи, необходимо изучить тему «Машинное обучение»):
- Построить модель для прогнозирования спроса на перелеты по разным направлениям.
- Оценить точность прогноза и определить факторы, влияющие на спрос.
- Визуализация результатов:
- Построить графики и диаграммы для наглядного отображения результатов анализа.
- Подготовить отчет с основными выводами и рекомендациями для руководства.
- Создание дашборда (выходит за рамки данной статьи, необходимо изучить тему «Создание интерактивных дашбордов»)::
- Разработать интерактивный дашборд для мониторинга ключевых метрик и параметров бизнеса.
- Обеспечить возможность фильтрации и детального анализа данных.
Это проектное задание позволит провести полный цикл анализа данных в авиакомпании: от предварительной обработки данных до исследовательского анализа, сегментации пассажиров, прогнозирования спроса и создания визуализаций для презентации результатов.
Индивидуальное и групповое обучение «Аналитик данных»
Если вы хотите стать экспертом в аналитике, могу помочь. Запишитесь на мой курс «Аналитик данных» и начните свой путь в мир ИТ уже сегодня!
Контакты
Для получения дополнительной информации и записи на курсы свяжитесь со мной:
Телеграм: https://t.me/Vvkomlev
Email: victor.komlev@mail.ru
Объясняю сложное простыми словами. Даже если вы никогда не работали с ИТ и далеки от программирования, теперь у вас точно все получится! Проверено десятками примеров моих учеников.
Гибкий график обучения. Я предлагаю занятия в мини-группах и индивидуально, что позволяет каждому заниматься в удобном темпе. Вы можете совмещать обучение с работой или учебой.
Практическая направленность. 80%: практики, 20% теории. У меня множество авторских заданий, которые фокусируются на практике. Вы не просто изучаете теорию, а сразу применяете знания в реальных проектах и задачах.
Разнообразие учебных материалов: Теория представлена в виде текстовых уроков с примерами и видео, что делает обучение максимально эффективным и удобным.
Понимаю, что обучение информационным технологиям может быть сложным, особенно для новичков. Моя цель – сделать этот процесс максимально простым и увлекательным. У меня персонализированный подход к каждому ученику. Максимальный фокус внимания на ваши потребности и уровень подготовки.