В этой статье вы начнете изучать реальные задачи, где краулеры (пауки) будут проходить по нескольким страницам и даже нескольким сайтам.
Веб-пауки называются так потому, что они «ползут» по интернету. В их основе лежит элемент рекурсии. Они должны получить содержимое страницы по URL, исследовать эту страницу на наличие других URL и затем переходить по ним, и так до бесконечности.
Однако будьте осторожны: то, что вы можете сканировать веб, не всегда означает, что вам следует это делать. С веб-краулерами вы должны быть очень внимательны к тому, сколько пропускной способности вы используете, и стараться минимизировать нагрузку на целевой сервер.
Перемещение по одному домену
Даже если вы не слышали о «Шести степенях Википедии», вы могли слышать о его аналоге, «Шести степенях Кевина Бейкона». В обеих играх цель состоит в том, чтобы связать двух маловероятных субъектов (в первом случае — статьи Википедии, а во втором — актеров, снимавшихся в одном фильме) через цепочку, содержащую не более шести звеньев (включая начальные и конечные субъекты).
Например, Эрик Айдл снимался в фильме «Дадли Справедливо» с Бренданом Фрейзером, который снимался в «Воздухе, которым я дышу» с Кевином Бейконом. В этом случае цепочка от Эрика Айдла до Кевина Бейкона состоит всего из трех звеньев.
В этом разделе вы начнете проект, который станет решателем задачи «Шести степеней Википедии»: вы сможете взять страницу Гоши Куценко и найти минимальное количество кликов по ссылкам, которые приведут вас на страницу Сергея Бондарчука.
Но что насчет нагрузки на серверы Википедии?
Согласно Фонду Викимедиа (материнской организации Википедии), веб-сайты проекта получают примерно 2500 запросов в секунду, причем более 99% из них приходится на домен Википедии. Из-за огромного объема трафика, ваши веб-краулеры вряд ли окажут заметное влияние на нагрузку серверов Википедии. Однако, если вы будете часто запускать примеры кода из этой книги или создавать свои собственные проекты по сканированию Википедии, я призываю вас сделать налоговый вычет и пожертвовать Фонду Викимедиа — не только для компенсации нагрузки на серверы, но и для поддержки образовательных ресурсов, доступных для всех.
Также имейте в виду, что если вы планируете большой проект, связанный с данными из Википедии, стоит проверить, не доступны ли эти данные через API Википедии. Википедия часто используется как сайт для демонстрации сканеров и краулеров из-за простой структуры HTML и относительной стабильности. Однако её API часто позволяет более эффективно получать те же данные.
Для поиска русской версии статей Википедии можно использовать сайт ru.wikipedia.org.
Теперь давайте рассмотрим, как написать скрипт на Python, который извлекает произвольную страницу Википедии и создает список ссылок на этой странице. В нашем примере будем использовать страницы Гоши Куценко и Сергея Бондарчука.
Шаг 1: Извлечение всех ссылок со страницы
Начнем с простого скрипта, который получает HTML-код страницы и извлекает все ссылки.
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.parse import quote
# Кодируем URL для работы с кириллическими символами
url = 'https://ru.wikipedia.org/wiki/Куценко,_Гоша'
encoded_url = quote(url, safe=':/')
html = urlopen(encoded_url)
bs = BeautifulSoup(html, 'html.parser')
for link in bs.find_all('a'):
if 'href' in link.attrs:
print(link.attrs['href'])
Этот скрипт выведет все ссылки, включая ссылки на служебные страницы Википедии, такие как «Политика конфиденциальности» и «Связаться с нами».
Шаг 2: Фильтрация ссылок
Для извлечения только тех ссылок, которые ведут на статьи, мы можем использовать следующие правила:
- Ссылки находятся в элементе
divс идентификаторомbodyContent. - URL не содержат двоеточий.
- URL начинаются с
/wiki/.
Используем эти правила для фильтрации ссылок с помощью регулярного выражения ^(/wiki/)((?!:).)*$.
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.parse import quote
import re
# Кодируем URL для работы с кириллическими символами
url = 'https://ru.wikipedia.org/wiki/Куценко,_Гоша'
encoded_url = quote(url, safe=':/')
html = urlopen(encoded_url)
bs = BeautifulSoup(html, 'html.parser')
for link in bs.find('div', {'id': 'bodyContent'}).find_all(
'a', href=re.compile('^(/wiki/)((?!:).)*$')):
print(link.attrs['href'])
Этот скрипт выведет только те URL, которые ведут на статьи Википедии со страницы Гоши Куценко.
Пример вывода
Запустив скрипт, вы получите список всех ссылок на статьи, на которые ссылается страница Гоши Куценко.
/wiki/%D0%9A%D0%BE%D0%BC%D1%81%D0%BE%D0%BC%D0%BE%D0%BB%D1%8C%D1%81%D0%BA%D0%B0%D1%8F_%D0%BF%D1%80%D0%B0%D0%B2%D0%B4%D0%B0_%D0%B2_%D0%A3%D0%BA%D1%80%D0%B0%D0%B8%D0%BD%D0%B5
/wiki/%D0%92%D0%BB%D0%B0%D0%B4%D0%B8%D0%BC%D0%B8%D1%80_%D0%92%D0%B0%D1%80%D1%84%D0%BE%D0%BB%D0%BE%D0%BC%D0%B5%D0%B5%D0%B2
/wiki/%D0%AD%D1%85%D0%BE_%D0%9C%D0%BE%D1%81%D0%BA%D0%B2%D1%8B
/wiki/Wayback_Machine
/wiki/Wayback_Machine
/wiki/Wayback_Machine
/wiki/Wayback_Machine
/wiki/%D0%98%D0%B7%D0%B2%D0%B5%D1%81%D1%82%D0%B8%D1%8F
/wiki/%D0%A2%D1%80%D1%83%D0%B4_(%D0%B3%D0%B0%D0%B7%D0%B5%D1%82%D0%B0)
/wiki/%D0%9D%D0%B5%D0%B7%D0%B0%D0%B2%D0%B8%D1%81%D0%B8%D0%BC%D0%B0%D1%8F_%D0%B3%D0%B0%D0%B7%D0%B5%D1%82%D0%B0
/wiki/%D0%A2%D0%B5%D0%BB%D0%B5%D0%BD%D0%B5%D0%B4%D0%B5%D0%BB%D1%8F
/wiki/%D0%A2%D0%B5%D0%BB%D0%B5%D0%BD%D0%B5%D0%B4%D0%B5%D0%BB%D1%8F
/wiki/%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%BE%D0%B5_%D1%80%D0%B0%D0%B4%D0%B8%D0%BE
/wiki/%D0%9A%D0%BE%D0%BC%D1%81%D0%BE%D0%BC%D0%BE%D0%BB%D1%8C%D1%81%D0%BA%D0%B0%D1%8F_%D0%BF%D1%80%D0%B0%D0%B2%D0%B4%D0%B0
/wiki/%D0%9C%D0%BE%D1%81%D0%BA%D0%BE%D0%B2%D1%81%D0%BA%D0%B8%D0%B9_%D0%BA%D0%BE%D0%BC%D1%81%D0%BE%D0%BC%D0%BE%D0%BB%D0%B5%D1%86
/wiki/Gemeinsame_Normdatei
/wiki/%D0%9C%D0%B5%D0%B6%D0%B4%D1%83%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%BD%D1%8B%D0%B9_%D0%B8%D0%B4%D0%B5%D0%BD%D1%82%D0%B8%D1%84%D0%B8%D0%BA%D0%B0%D1%82%D0%BE%D1%80_%D1%81%D1%82%D0%B0%D0%BD%D0%B4%D0%B0%D1%80%D1%82%D0%BD%D1%8B%D1%85_%D0%BD%D0%B0%D0%B8%D0%BC%D0%B5%D0%BD%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B9
/wiki/%D0%9A%D0%BE%D0%BD%D1%82%D1%80%D0%BE%D0%BB%D1%8C%D0%BD%D1%8B%D0%B9_%D0%BD%D0%BE%D0%BC%D0%B5%D1%80_%D0%91%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D0%B8_%D0%9A%D0%BE%D0%BD%D0%B3%D1%80%D0%B5%D1%81%D1%81%D0%B0
/wiki/%D0%A3%D0%BD%D0%B8%D0%B2%D0%B5%D1%80%D1%81%D0%B8%D1%82%D0%B5%D1%82%D1%81%D0%BA%D0%B0%D1%8F_%D1%81%D0%B8%D1%81%D1%82%D0%B5%D0%BC%D0%B0_%D0%B4%D0%BE%D0%BA%D1%83%D0%BC%D0%B5%D0%BD%D1%82%D0%B0%D1%86%D0%B8%D0%B8
/wiki/VIAF
/wiki/WorldCatТеперь мы можем легко изменить URL на страницу Сергея Бондарчука:
from urllib.request import urlopen
from bs4 import BeautifulSoup
from urllib.parse import quote
import re
# Кодируем URL для работы с кириллическими символами
url = 'https://ru.wikipedia.org/wiki/Бондарчук,_Сергей_Фёдорович'
encoded_url = quote(url, safe=':/')
html = urlopen(encoded_url)
bs = BeautifulSoup(html, 'html.parser')
for link in bs.find('div', {'id': 'bodyContent'}).find_all(
'a', href=re.compile('^(/wiki/)((?!:).)*$')):
print(link.attrs['href'])
Конечно, создание скрипта, который просто находит все ссылки на статьи в одной, жестко закодированной статье Википедии, интересно, но мало полезно на практике. Необходимо превратить этот код во что-то более универсальное. Вот как можно это сделать:
- Написать функцию
getLinks, которая принимает URL статьи Википедии в форме/wiki/<Article_Name>и возвращает список всех связанных URL статей в той же форме. - Написать основную функцию, которая вызывает
getLinksс начальной статьей, выбирает случайную ссылку из возвращенного списка и снова вызываетgetLinks, пока программа не будет остановлена или пока на новой странице не будут найдены ссылки на статьи.
Полный код
Вот полный код, который выполняет это:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
# Кодируем URL для работы с кириллическими символами
base_url = 'https://ru.wikipedia.org'
html = urlopen(base_url + articleUrl)
bs = BeautifulSoup(html, 'html.parser')
return bs.find('div', {'id':'bodyContent'}).find_all('a',
href=re.compile('^(/wiki/)((?!:).)*$'))
def main(startArticle):
links = getLinks(startArticle)
while len(links) > 0:
newArticle = links[random.randint(0, len(links) - 1)].attrs['href']
print(newArticle)
links = getLinks(newArticle)
# Запуск основной функции с начальной статьей
main('/wiki/Куценко,_Гоша')
Объяснение кода
- Инициализация генератора случайных чисел:
random.seed(datetime.datetime.now())Устанавливает начальное значение генератора случайных чисел с помощью текущего системного времени, что гарантирует новый и интересный путь по статьям Википедии каждый раз при запуске программы.
- Функция
getLinks:def getLinks(articleUrl): base_url = 'https://ru.wikipedia.org' html = urlopen(base_url + articleUrl) bs = BeautifulSoup(html, 'html.parser') return bs.find('div', {'id':'bodyContent'}).find_all('a', href=re.compile('^(/wiki/)((?!:).)*$'))Эта функция принимает URL статьи, загружает её HTML-код и использует BeautifulSoup для поиска всех ссылок на другие статьи, соответствующие заданному регулярному выражению.
- Основная функция
main:def main(startArticle): links = getLinks(startArticle) while len(links) > 0: newArticle = links[random.randint(0, len(links) - 1)].attrs['href'] print(newArticle) links = getLinks(newArticle)Основная функция вызывает
getLinksс начальной статьей, выбирает случайную ссылку из возвращенного списка и снова вызываетgetLinks, пока не останутся ссылки или пока программа не будет остановлена. - Запуск программы:
main('/wiki/Куценко,_Гоша')Запускает основную функцию с начальной статьей о Гоше Куценко.
Теперь у вас есть универсальный скрипт для случайного перехода по статьям Википедии, начиная с заданной страницы.
Псевдослучайные числа и начальные значения (Seed)
В предыдущем примере использовался генератор случайных чисел Python для случайного выбора статьи на каждой странице, чтобы продолжить случайный обход по Википедии. Однако случайные числа следует использовать с осторожностью.
Хотя компьютеры превосходны в вычислении правильных ответов, они ужасны в придумывании чего-то нового. По этой причине случайные числа могут представлять собой вызов. Большинство алгоритмов генерации случайных чисел стремятся производить равномерно распределенную и труднопредсказуемую последовательность чисел, но для их работы требуется начальное значение, называемое «seed». Одно и то же начальное значение каждый раз будет производить одну и ту же последовательность «случайных» чисел, поэтому в данном примере в качестве стартера используется системные часы для создания новых последовательностей случайных чисел, а значит, и новых последовательностей случайных статей. Это делает программу более интересной при каждом запуске.
Для любопытных: генератор псевдослучайных чисел Python основан на алгоритме Mersenne Twister. Он производит случайные числа, которые трудно предсказать и которые равномерно распределены, однако требует немного больше ресурсов процессора. Хорошие случайные числа не обходятся дешево!
Обработка исключений
В примерах кода исключена большая часть обработки исключений ради краткости. Однако, автономный производственный код требует гораздо более тщательной обработки исключений. Например, если Википедия изменит имя тега bodyContent, программа вызовет AttributeError при попытке извлечь текст из этого тега.
Чтобы справиться с подобными ситуациями, добавлена простая обработка исключений:
def getLinks(articleUrl):
try:
base_url = 'https://ru.wikipedia.org'
html = urlopen(base_url + articleUrl)
bs = BeautifulSoup(html, 'html.parser')
return bs.find('div', {'id':'bodyContent'}).find_all('a',
href=re.compile('^(/wiki/)((?!:).)*$'))
except Exception as e:
print(f"Произошла ошибка при попытке получить ссылки: {e}")
return []
Полный код программы с обработкой исключений
from urllib.request import urlopen
from bs4 import BeautifulSoup
import datetime
import random
import re
# Устанавливаем начальное значение генератора случайных чисел системными часами
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
try:
base_url = 'https://ru.wikipedia.org'
html = urlopen(base_url + articleUrl)
bs = BeautifulSoup(html, 'html.parser')
return bs.find('div', {'id':'bodyContent'}).find_all('a',
href=re.compile('^(/wiki/)((?!:).)*$'))
except Exception as e:
print(f"Произошла ошибка при попытке получить ссылки: {e}")
return []
def main(startArticle):
links = getLinks(startArticle)
while len(links) > 0:
newArticle = links[random.randint(0, len(links) - 1)].attrs['href']
print(newArticle)
links = getLinks(newArticle)
# Запуск основной функции с начальной статьей
main('/wiki/Куценко,_Гоша')
Обход всего сайта
В предыдущем разделе вы выполняли случайный переход по сайту, переходя от одной ссылки к другой. Но что если нужно систематически каталогизировать или искать каждую страницу на сайте? Обход всего сайта, особенно крупного, — это процесс, требующий больших объемов памяти и обычно подходящий для приложений, где есть база данных для хранения результатов обхода. Однако вы можете изучить поведение таких приложений без их полного запуска.
Темный и глубокий веб
Вы, вероятно, слышали такие термины, как «глубокий веб», «темный веб» или «скрытый веб», особенно в последние годы в СМИ. Что они означают?
Глубокий веб — это любая часть веба, которая не является частью поверхностного веба. Поверхностный веб — это та часть интернета, которая индексируется поисковыми системами. Оценки сильно разнятся, но глубокий веб почти наверняка составляет около 90% интернета. Поскольку Google не может, например, отправлять формы, находить страницы, на которые не ссылаются домены верхнего уровня, или исследовать сайты, где это запрещено файлом robots.txt, поверхностный веб остается относительно небольшим.
Темный веб, также известный как даркнет, — это совершенно другое. Он работает на существующей сетевой инфраструктуре, но использует Tor или другой клиент с протоколом приложения, который работает поверх HTTP, обеспечивая защищенный канал для обмена информацией. Хотя теоретически возможно собирать данные с темного веба так же, как с любого другого сайта, это выходит за рамки данной книги.
В отличие от темного веба, глубокий веб относительно легко сканировать. Многие инструменты в этой книге научат вас, как обходить и собирать информацию из многих мест, куда не могут попасть поисковые роботы Google.
Полный обход сайта
Когда обход всего сайта может быть полезен, а когда вреден? Веб-сканеры, которые обходят весь сайт, полезны для множества задач, включая:
- Создание карты сайта Несколько лет назад у меня была проблема: важный клиент хотел оценить редизайн сайта, но не хотел предоставлять доступ к внутренней части их системы управления контентом и не имел общедоступной карты сайта. Я смог использовать сканер для охвата всего сайта, сбора всех внутренних ссылок и организации страниц в фактическую структуру папок, используемую на сайте. Это позволило мне быстро найти разделы сайта, о которых я даже не подозревал, и точно подсчитать, сколько макетов страниц потребуется и сколько контента нужно будет перенести.
- Сбор данных Другой клиент хотел собрать статьи (истории, блоги, новости и т.д.) для создания рабочей модели специализированной поисковой платформы. Хотя обходы этих сайтов не должны были быть исчерпывающими, они должны были быть достаточно обширными (мы были заинтересованы в сборе данных только с нескольких сайтов). Я смог создать сканеры, которые рекурсивно обходили каждый сайт и собирали только данные, найденные на страницах с статьями.
Реализация обхода
Подход к исчерпывающему обходу сайта заключается в том, чтобы начать с верхнего уровня страницы (например, домашней страницы) и искать список всех внутренних ссылок на этой странице. Каждая из этих ссылок затем сканируется, и на каждой из них находятся дополнительные списки ссылок, что вызывает еще один обход.
Очевидно, что это может быстро привести к взрыву количества страниц. Если каждая страница имеет 10 внутренних ссылок, а сайт состоит из 5 уровней страниц (что довольно типично для сайта среднего размера), то количество страниц, которые нужно обойти, составит 10^5, или 100 000 страниц, прежде чем вы сможете быть уверены, что исчерпывающе охватили сайт. Странно, но хотя «5 уровней страниц и 10 внутренних ссылок на страницу» — это довольно типичные размеры для сайта, очень немногие сайты имеют 100 000 или более страниц. Причина в том, что подавляющее большинство внутренних ссылок являются дубликатами.
Чтобы избежать обхода одной и той же страницы дважды, крайне важно, чтобы все обнаруженные внутренние ссылки были отформатированы последовательно и хранились в текущем множестве для легкого поиска во время выполнения программы. Множества (set) похоже на список, но элементы в нем не имеют определенного порядка, и хранятся только уникальные элементы, что идеально подходит для наших нужд. Только «новые» ссылки должны обходиться и искаться для дополнительных ссылок:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
# Набор для хранения уникальных страниц
pages = set()
def getLinks(pageUrl):
base_url = 'https://ru.wikipedia.org'
html = urlopen(base_url + pageUrl)
bs = BeautifulSoup(html, 'html.parser')
for link in bs.find_all('a', href=re.compile('^(/wiki/)')):
if 'href' in link.attrs:
if link.attrs['href'] not in pages:
# Мы наткнулись на новую страницу
newPage = link.attrs['href']
print(newPage)
pages.add(newPage)
getLinks(newPage)
# Начальный вызов с пустым URL, который трактуется как главная страница Википедии
getLinks('')
Объяснение кода
- Набор
pagesдля хранения уникальных страниц: Набор используется для хранения ссылок на уже посещенные страницы, чтобы избежать их повторного обхода. - Функция
getLinks:- Загружает HTML-код страницы с заданным URL.
- Использует BeautifulSoup для парсинга HTML.
- Находит все ссылки, начинающиеся с
/wiki/, независимо от их местоположения на странице или наличия двоеточий. - Если ссылка не находится в наборе
pages, добавляет ее в набор и вызываетgetLinksрекурсивно для этой новой ссылки.
Сбор данных с сайта
Веб-сканеры были бы довольно скучными, если бы они только переходили с одной страницы на другую. Чтобы сделать их полезными, нужно иметь возможность делать что-то на странице, пока вы находитесь там. Давайте посмотрим, как создать скрапер, который собирает заголовок, первый абзац содержимого и ссылку для редактирования страницы (если доступно).
Как всегда, первый шаг для определения того, как лучше это сделать — изучить несколько страниц с сайта и определить шаблон. Проанализировав несколько страниц Википедии (как статьи, так и не статьи, например, страницу политики конфиденциальности), можно сделать следующие выводы:
- Заголовки: Все заголовки (на всех страницах, независимо от их статуса как страницы статьи, страницы истории изменений или любой другой страницы) имеют заголовки под тегами
h1 → span, и это единственные тегиh1на странице. - Содержимое: Весь текст содержится под тегом
div#bodyContent. Однако, если вы хотите получить только первый абзац текста, лучше использоватьdiv#mw-content-text → p(выбирая только первый тег абзаца). Это верно для всех страниц контента, кроме страниц файлов (например, страница файла), которые не имеют разделов текстового контента. - Ссылки для редактирования: Ссылки для редактирования появляются только на страницах статей. Если они есть, они будут находиться в теге
li#ca-edit, подli#ca-edit → span → a.
Модификация кода
Модифицируя базовый код обхода, можно создать программу, которая будет собирать и выводить данные:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
# Набор для хранения уникальных страниц
pages = set()
def getLinks(pageUrl):
base_url = 'https://ru.wikipedia.org'
html = urlopen(base_url + pageUrl)
bs = BeautifulSoup(html, 'html.parser')
try:
# Получаем заголовок страницы
print(bs.h1.get_text())
# Получаем первый абзац текста
print(bs.find(id='mw-content-text').find_all('p')[0].get_text())
# Получаем ссылку для редактирования, если она существует
edit_link = bs.find(id='ca-edit').find('span').find('a')
if edit_link:
print(base_url + edit_link.attrs['href'])
except AttributeError:
print('На этой странице чего-то не хватает! Продолжаем.')
# Находим и обходим все внутренние ссылки
for link in bs.find_all('a', href=re.compile('^(/wiki/)')):
if 'href' in link.attrs:
if link.attrs['href'] not in pages:
# Мы наткнулись на новую страницу
newPage = link.attrs['href']
print('-'*20)
print(newPage)
pages.add(newPage)
getLinks(newPage)
# Начальный вызов с пустым URL, который трактуется как главная страница Википедии
getLinks('')
Объяснение кода
- Множество
pagesдля хранения уникальных страниц: Используется для хранения ссылок на уже посещенные страницы, чтобы избежать их повторного обхода. - Функция
getLinks:- Загружает HTML-код страницы с заданным URL.
- Использует BeautifulSoup для парсинга HTML.
- Пытается получить и вывести заголовок страницы, первый абзац текста и ссылку для редактирования (если она есть).
- Если какой-либо элемент отсутствует, ловит исключение
AttributeErrorи выводит сообщение о пропущенном элементе. - Находит все внутренние ссылки, начинающиеся с
/wiki/, и рекурсивно вызываетgetLinksдля каждой новой ссылки.
Обработка Перенаправлений
Перенаправления позволяют веб-серверу указать один домен или URL на контент, расположенный в другом месте. Существует два основных типа перенаправлений:
- Серверные перенаправления:
- Эти перенаправления происходят до загрузки страницы, когда URL меняется на стороне сервера. Вам не нужно беспокоиться об этом, если вы используете библиотеку
urllibв Python 3.x, так как она автоматически обрабатывает перенаправления.
- Эти перенаправления происходят до загрузки страницы, когда URL меняется на стороне сервера. Вам не нужно беспокоиться об этом, если вы используете библиотеку
- Клиентские перенаправления:
- Эти перенаправления выполняются после загрузки страницы, часто с сообщением вроде «Вы будете перенаправлены через 10 секунд», когда страница сначала загружается, а затем перенаправляется на новый URL.
Если вы используете библиотеку requests в Python, убедитесь, что установили флаг allow_redirects в значение True, чтобы обрабатывать перенаправления автоматически:
import requests
r = requests.get('http://github.com', allow_redirects=True)
Будьте внимательны: иногда URL страницы, на которой вы оказались, может не совпадать с тем URL, с которого вы начали переход.
Для получения дополнительной информации о клиентских перенаправлениях, которые выполняются с помощью JavaScript или HTML, см. статью Скрейпинг JavaScript.
Краулинг множества сайтов в интернете
Когда Google только начинал в 1996 году, это были всего лишь два студента-магистранта из Стэнфорда с устаревшим сервером и веб-краулером на Python. Теперь, когда вы знаете, как скрапить веб, вы всего лишь на шаг от того, чтобы стать следующим техно-магнатом!
Серьезно, веб-краулеры стоят в центре многих современных веб-технологий, и для их использования вовсе не обязательно иметь большой дата-центр. Для любого анализа данных, который охватывает несколько доменов, нужно строить краулеры, способные интерпретировать и хранить данные с множества страниц в Интернете.
Как и в предыдущем примере, ваши веб-краулеры будут следовать по ссылкам от страницы к странице, создавая карту Интернета. Но на этот раз они не будут игнорировать внешние ссылки; они будут следовать за ними.
Впереди неизведанные территории
Помните, что код из следующего раздела может идти куда угодно в Интернете. Если мы научились чему-то из примера «Шести степеней Википедии», так это тому, что можно легко перейти от сайта вроде http://www.sesamestreet.org/ к чему-то менее приличному всего за несколько переходов.
Дети, спросите у родителей, прежде чем запускать этот код. Для тех, кто имеет чувствительную конституцию или религиозные ограничения, которые могут запретить просмотр контента сомнительного характера, следите за примерами кода, но будьте осторожны при их запуске.
Прежде чем начать писать краулер, который будет следовать за всеми исходящими ссылками без разбора, стоит задать себе несколько вопросов:
- Какую информацию я пытаюсь собрать? Можно ли это сделать, получая данные всего несколько заранее определенных сайтов (это почти всегда проще), или моему краулеру нужно иметь возможность обнаруживать новые сайты, о которых я не знаю?
- Когда мой краулер достигнет конкретного сайта, будет ли он сразу следовать за следующей исходящей ссылкой на новый сайт, или он останется на текущем сайте и будет исследовать его?
- Есть ли условия, при которых я не хотел бы скрапить определенный сайт? Например, интересует ли меня контент только на русском языке?
- Как я защищаю себя от юридических последствий, если мой веб-краулер привлек внимание администратора сайта, на который он попадает?
Гибкий набор функций на Python для веб-скрапинга
Набор гибких функций на Python, который можно использовать для различных типов веб-скрапинга, можно легко написать менее чем за 60 строк кода. Здесь я привожу код, разделенный на несколько частей для удобства обсуждения. Полная рабочая версия доступна в репозитории GitHub для этой книги:
Получение всех внутренних ссылок на странице
from urllib.parse import urlparse
from bs4 import BeautifulSoup
# Получает список всех внутренних ссылок на странице
def getInternalLinks(bs, url):
netloc = urlparse(url).netloc
scheme = urlparse(url).scheme
internalLinks = set()
for link in bs.find_all('a'):
if not link.attrs.get('href'):
continue
parsed = urlparse(link.attrs['href'])
if parsed.netloc == '':
l = f'{scheme}://{netloc}/{link.attrs["href"].strip("/")}'
internalLinks.add(l)
elif parsed.netloc == netloc:
internalLinks.add(link.attrs['href'])
return list(internalLinks)
Функция getInternalLinks принимает объект BeautifulSoup и URL страницы. Этот URL используется только для определения сетевого расположения (netloc) и схемы (обычно http или https) внутреннего сайта, так что можно использовать любой внутренний URL для целевого сайта, не обязательно точный URL объекта BeautifulSoup.
Функция создает множество internalLinks, которое используется для отслеживания всех внутренних ссылок на странице. Она проверяет все теги <a> на наличие атрибута href, который либо не содержит netloc (является относительным URL, например, «/careers/»), либо имеет netloc, совпадающий с URL, переданным в функцию.
Получение всех внешних ссылок на странице
# Получает список всех внешних ссылок на странице
def getExternalLinks(bs, url):
internal_netloc = urlparse(url).netloc
externalLinks = set()
for link in bs.find_all('a'):
if not link.attrs.get('href'):
continue
parsed = urlparse(link.attrs['href'])
if parsed.netloc != '' and parsed.netloc != internal_netloc:
externalLinks.add(link.attrs['href'])
return list(externalLinks)
Функция getExternalLinks работает аналогично getInternalLinks. Она проверяет все теги <a> на наличие атрибута href и ищет те, у которых netloc не совпадает с netloc URL, переданным в функцию.
Получение случайной внешней ссылки
import random
from urllib.request import urlopen
# Получает случайную внешнюю ссылку, начиная с заданной страницы
def getRandomExternalLink(startingPage):
bs = BeautifulSoup(urlopen(startingPage), 'html.parser')
externalLinks = getExternalLinks(bs, startingPage)
if not externalLinks:
print('Нет внешних ссылок, ищем на сайте')
internalLinks = getInternalLinks(bs, startingPage)
return getRandomExternalLink(random.choice(internalLinks))
else:
return random.choice(externalLinks)
Функция getRandomExternalLink использует функцию getExternalLinks, чтобы получить список всех внешних ссылок на странице. Если найдена хотя бы одна ссылка, она выбирает случайную ссылку из списка и возвращает её. Если внешних ссылок нет, функция выбирает случайную внутреннюю ссылку и рекурсивно вызывает саму себя, пока не найдёт внешнюю ссылку.
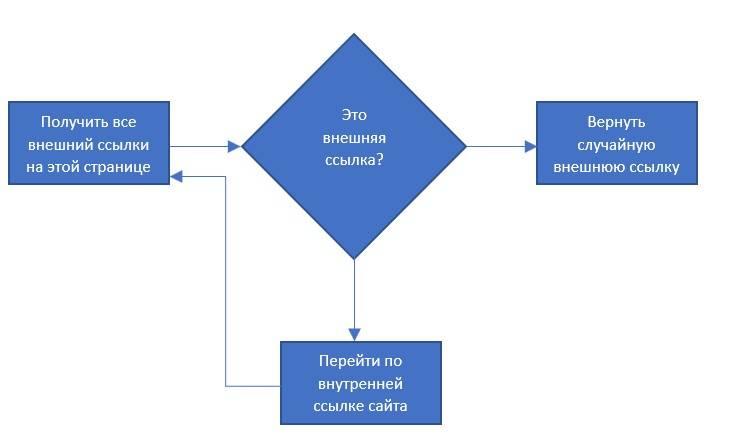
Рекурсивное следование только за внешними ссылками
# Рекурсивно переходит по только внешним ссылкам
def followExternalOnly(startingSite):
externalLink = getRandomExternalLink(startingSite)
print(f'Случайная внешняя ссылка: {externalLink}')
followExternalOnly(externalLink)
Функция followExternalOnly использует getRandomExternalLink, а затем рекурсивно переходит по внешним ссылкам в Интернете. Вы можете вызвать её так:
followExternalOnly('https://www.oreilly.com/')
Эта программа начинает с http://oreilly.com и случайным образом переходит от одной внешней ссылки к другой. Пример вывода может быть следующим:
http://igniteshow.com/
http://feeds.feedburner.com/oreilly/news
http://hire.jobvite.com/CompanyJobs/Careers.aspx?c=q319
Home Page
Не всегда можно найти внешние ссылки на первой странице сайта. В таком случае используется метод, аналогичный тому, что применялся в предыдущем примере краулинга, для рекурсивного поиска по сайту до тех пор, пока не найдётся внешняя ссылка.
Не используйте примеры программ в продакшене!
Примеры программ в этой статье не всегда содержат все необходимые проверки и обработку исключений, которые требуются для готового к продакшн кода. Например, если на сайте, который встречает ваш краулер, не окажется внешних ссылок (хотя это маловероятно, но рано или поздно это случится, если вы будете запускать его достаточно долго), программа продолжит работать до тех пор, пока не достигнет предела рекурсии Python.
Один из простых способов повысить надежность этого краулера — объединить его с кодом обработки исключений для подключения. Это позволит коду выбирать другой URL для перехода в случае ошибки HTTP или исключения сервера при извлечении страницы.
Прежде чем использовать этот код для каких-либо серьезных целей, убедитесь, что вы добавили проверки для обработки потенциальных проблем.
Как можно улучшить код
Приятно, что разбиение задач на простые функции, такие как «найти все внешние ссылки на этой странице», позволяет легко изменить код для выполнения другой задачи краулинга. Например, если ваша цель — обойти весь сайт в поисках внешних ссылок и записывать каждую из них, вы можете добавить следующую функцию:
from urllib.request import urlopen
from bs4 import BeautifulSoup
# Список всех внешних и внутренних ссылок, найденных на сайте
allExtLinks = []
allIntLinks = []
# Собирает список всех внешних URL-адресов, найденных на сайте
def getAllExternalLinks(url):
bs = BeautifulSoup(urlopen(url), 'html.parser')
internalLinks = getInternalLinks(bs, url)
externalLinks = getExternalLinks(bs, url)
for link in externalLinks:
if link not in allExtLinks:
allExtLinks.append(link)
print(link)
for link in internalLinks:
if link not in allIntLinks:
allIntLinks.append(link)
getAllExternalLinks(link)
allIntLinks.append('https://oreilly.com') # Убедитесь, что ссылка на начальную страницу добавлена
getAllExternalLinks('https://www.oreilly.com/')
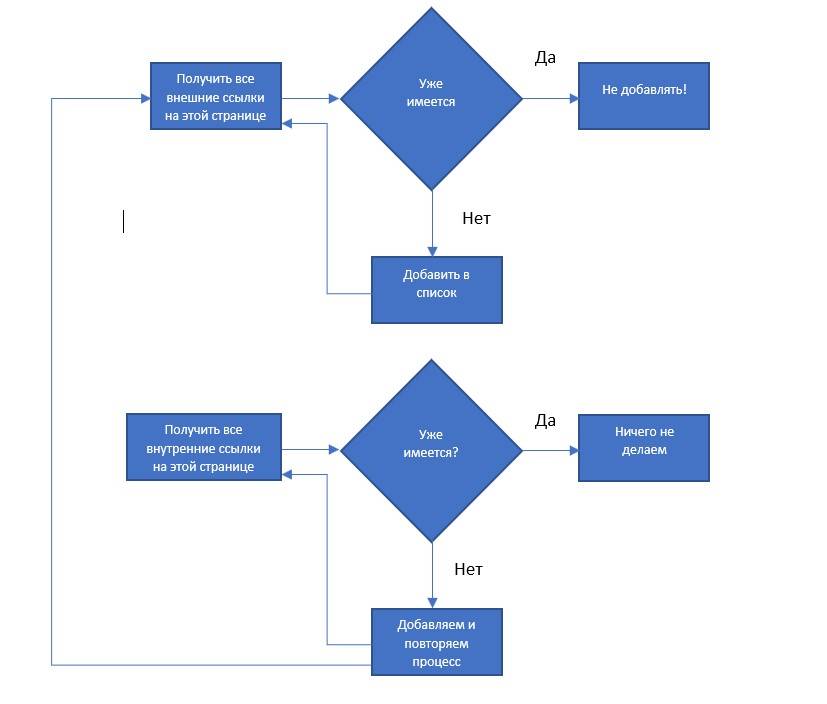
Этот код можно представить как два цикла: один для сбора внутренних ссылок, другой — для сбора внешних ссылок, которые работают вместе. Схема работы такого краулера выглядит как на рисунке
Подготовка к написанию кода
Записывать или рисовать диаграммы того, что должен делать код, перед тем как написать сам код — отличная привычка, которая может сэкономить вам много времени и уменьшить количество ошибок, когда ваши краулеры станут более сложными.
Индивидуальное и групповое обучение «Аналитик данных»
Если вы хотите стать экспертом в аналитике, могу помочь. Запишитесь на мой курс «Аналитик данных» и начните свой путь в мир ИТ уже сегодня!
Контакты
Для получения дополнительной информации и записи на курсы свяжитесь со мной:
Телеграм: https://t.me/Vvkomlev
Email: victor.komlev@mail.ru
Объясняю сложное простыми словами. Даже если вы никогда не работали с ИТ и далеки от программирования, теперь у вас точно все получится! Проверено десятками примеров моих учеников.
Гибкий график обучения. Я предлагаю занятия в мини-группах и индивидуально, что позволяет каждому заниматься в удобном темпе. Вы можете совмещать обучение с работой или учебой.
Практическая направленность. 80%: практики, 20% теории. У меня множество авторских заданий, которые фокусируются на практике. Вы не просто изучаете теорию, а сразу применяете знания в реальных проектах и задачах.
Разнообразие учебных материалов: Теория представлена в виде текстовых уроков с примерами и видео, что делает обучение максимально эффективным и удобным.
Понимаю, что обучение информационным технологиям может быть сложным, особенно для новичков. Моя цель – сделать этот процесс максимально простым и увлекательным. У меня персонализированный подход к каждому ученику. Максимальный фокус внимания на ваши потребности и уровень подготовки.