Что такое веб-скрапинг?
Автоматизированный сбор данных из интернета существует почти столько же времени, сколько и сам интернет. Сегодня общее мнение склоняется в пользу термина «веб-скрапинг», поэтому я буду использовать его в этой статье. Также я буду упоминать программы, которые специализированно обходят множество страниц, как веб-пауки (web crawlers), или называть сами программы веб-скрапинга ботами.
В теории, веб-скрапинг — это практика сбора данных любыми способами, кроме взаимодействия программы с API (или, очевидно, использования веб-браузера человеком). Это чаще всего достигается написанием автоматизированных программ, которые отправляют запросы веб-серверу, запрашивают данные (обычно в виде HTML и других файлов, из которых состоят веб-страницы), а затем анализируют эти данные для извлечения необходимой информации.
На практике веб-скрапинг охватывает широкий спектр программных техник и технологий, таких как анализ данных, парсинг естественного языка и информационная безопасность.
Примечания:
- Веб-скрапинг — это техника извлечения данных с веб-сайтов. Она может быть выполнена с помощью специальных программ, которые симулируют действия пользователя, автоматически переходя по страницам и собирая нужную информацию.
- Веб-паук (Web crawler) — это программа, которая автоматически перемещается по страницам Интернета для индексации данных, используемых поисковыми системами.
- API (Application Programming Interface) — это набор правил и спецификаций, которые позволяют программам взаимодействовать друг с другом. В контексте веб-скрапинга, использование API — это более «чистый» и предпочтительный способ получения данных, поскольку он обычно не связан с парсингом HTML и не нарушает правила сайта.
- HTML (HyperText Markup Language) — это основной язык разметки для создания веб-страниц. Скраперы анализируют HTML, чтобы извлечь нужные данные, например текст, ссылки, информацию о продуктах и т.д.
- Парсинг — это процесс анализа информации с целью извлечения нужных данных. В контексте веб-скрапинга, это обычно означает анализ HTML-кода страницы для получения содержимого.
Зачем нужен веб-скрапинг?
Если вы используете интернет только через браузер, вы упускаете множество возможностей. Хотя браузеры удобны для выполнения JavaScript, отображения изображений и организации объектов в более удобном для восприятия человеком формате (среди прочего), веб-скраперы отлично справляются с сбором и обработкой больших объемов данных быстро. Вместо того чтобы просматривать одну страницу за раз через узкое окно монитора, вы можете просматривать базы данных, охватывающие тысячи или даже миллионы страниц сразу.
Кроме того, веб-скраперы могут зайти туда, куда не могут традиционные поисковые системы. Поиск в Google по запросу «самые дешевые авиабилеты в Москву» приведет к массе рекламы и популярных сайтов для поиска авиабилетов. Google знает только то, что эти веб-сайты говорят на своих страницах контента, но не точные результаты различных запросов, введенных в поисковик авиабилетов. Однако хорошо разработанный веб-скрапер может отслеживать стоимость полета в Москву во времени, на различных веб-сайтах, и сказать вам лучшее время для покупки билета.
Скрапинг или API?
Вы можете спросить: «Разве сбор данных — это не то, для чего предназначены API?» Да, API могут быть замечательными, если вы найдете тот, который подходит вашим целям. Они предназначены для предоставления удобного потока хорошо структурированных данных из одной компьютерной программы в другую. Вы можете найти API для многих типов данных, которые вы хотели бы использовать, таких как твиты в Twitter или страницы в Википедии. В целом, предпочтительнее использовать API (если он существует), чем создавать бота для получения тех же данных. Однако API может не существовать или не быть полезным для ваших целей по нескольким причинам:
- Вы собираете относительно небольшие, конечные наборы данных на большом количестве веб-сайтов без единого API.
- Данные, которые вы хотите, довольно малы или необычны, и создатель не считал нужным создавать для них API.
- Источник не имеет инфраструктуры или технической возможности создать API.
- Данные ценные и/или защищены и не предназначены для широкого распространения.
Даже когда API существует, объем запросов и ограничения скорости, типы данных или формат данных, которые он предоставляет, могут быть недостаточными для ваших целей.
Здесь на помощь приходит веб-скрапинг. С некоторыми исключениями, если вы можете просмотреть данные в браузере, вы можете получить к ним доступ с помощью скрипта на Python. Если вы можете получить к ним доступ в скрипте, вы можете хранить их в базе данных. А если вы можете хранить их в базе данных, вы можете делать практически что угодно с этими данными.
Очевидно, что существует множество крайне практичных применений доступа к практически неограниченным данным: прогнозирование рынка, машинный перевод и даже медицинская диагностика получили огромную выгоду от возможности извлекать и анализировать данные с новостных сайтов, переведенных текстов и здоровьесберегающих форумов соответственно.
Независимо от вашей области, веб-скрапинг почти всегда предоставляет способ более эффективно направлять деловые практики, повышать производительность или даже перейти в совершенно новую область.
Построение скраперов
Основные механизмы веб скрапинга отвечают на вопросы:
- как использовать Python для запроса информации с веб-сервера
- как выполнить базовую обработку ответа сервера
- как начать взаимодействовать с веб-сайтом автоматизированным способом
Как выглядит процесс веб-срапинга:
- Извлечение HTML-данных из доменного имени
- Анализ этих данных для получения целевой информации
- Хранение целевой информации
- При необходимости переход на другую страницу для повторения процесса
Экспресс руководство по созданию веб-скраперов
- Использование Python для запроса информации: Чтобы начать скрапинг, вам нужно научиться отправлять запросы к веб-серверам. Это можно сделать с помощью библиотеки
requestsв Python. Когда вы отправляете запрос на веб-сервер, вы запрашиваете HTML-код страницы, который потом можете анализировать.import requests url = 'https://example.com' response = requests.get(url) html = response.text - Базовая обработка ответа сервера: После получения ответа от сервера важно проверить, был ли запрос успешным. Это можно сделать, проверив статус-код ответа. Статус-код 200 означает, что запрос был успешным.
if response.status_code == 200: print("Запрос успешно выполнен!") else: print("Произошла ошибка при запросе!") - Автоматизированное взаимодействие с веб-сайтом: Для работы с HTML и извлечения нужной информации используется библиотека
BeautifulSoup. Она позволяет легко находить нужные элементы на странице, используя теги, атрибуты и CSS-селекторы.from bs4 import BeautifulSoup soup = BeautifulSoup(html, 'html.parser') title = soup.find('title').text print("Заголовок страницы:", title) - Переход между страницами: Веб-скраперы могут автоматически переходить с одной страницы на другую. Например, если вы анализируете пагинированный список, вы можете использовать
BeautifulSoupдля нахождения ссылки на следующую страницу и затем повторять процесс.next_link = soup.find('a', {'rel': 'next'}) if next_link: next_page_url = next_link['href'] print("Следующая страница:", next_page_url) - Хранение информации: После сбора данных их можно сохранить в файле, базе данных или любом другом хранилище. Например, сохранение данных в CSV-файле:
import csv data = [['Title', title], ['URL', url]] with open('data.csv', 'w', newline='', encoding='utf-8') as file: writer = csv.writer(file) writer.writerows(data)
Как работает интернет
Когда вы вводите URL в адресную строку вашего веб-браузера и нажимаете Enter, интерактивный текст, изображения и медиа появляются как будто по волшебству. То же самое волшебство происходит для миллиардов других людей каждый день. Они посещают те же веб-сайты, используют те же приложения — часто получая медиа и текст, настроенные специально для них.
И эти миллиарды людей используют разные типы устройств и программных приложений, написанных разными разработчиками в разных (часто конкурирующих) компаниях.
Удивительно, но нет всемогущего органа управления интернетом, регулирующего его развитие с какой-либо юридической силой. Вместо этого разные части интернета управляются несколькими разными организациями, которые развивались со временем на довольно стихийной и добровольной основе.
Конечно, выбор не принимать стандарты, которые публикуют эти организации, может привести к тому, что ваши вклады в интернет просто… не будут работать. Если ваш веб-сайт не может быть отображён в популярных веб-браузерах, люди, скорее всего, не станут его посещать. Если данные вашего маршрутизатора не могут быть интерпретированы каким-либо другим маршрутизатором, эти данные будут игнорироваться.
Веб-скрапинг, по сути, является практикой замены веб-браузера на приложение собственного дизайна. Из-за этого важно понимать стандарты и фреймворки, на которых построены веб-браузеры. Как веб-скрапер, вы должны как имитировать, так и иногда подрывать ожидаемые обычаи и практики интернета.
Краткое резюме:
- URL и запросы: Когда вы вводите URL (адрес веб-страницы) в строке браузера и нажимаете Enter, ваш компьютер отправляет запрос на сервер, где хранится эта веб-страница. Этот запрос и ответ на него — основа работы интернета.
- Протоколы: В основе работы интернета лежат различные протоколы. Самые известные из них:
- HTTP (HyperText Transfer Protocol): Протокол передачи гипертекста, используемый для загрузки веб-страниц.
- HTTPS (HTTP Secure): Безопасная версия HTTP, шифрующая данные для безопасной передачи.
- TCP/IP (Transmission Control Protocol/Internet Protocol): Набор коммуникационных протоколов для подключения сетевых устройств в интернете.
- DNS (Domain Name System): Система доменных имен переводит удобные для человека адреса (например,
www.example.com) в IP-адреса, которые используются для маршрутизации в интернете. - Веб-серверы и браузеры: Веб-сервер — это программное обеспечение (и обычно и сервер, на котором оно запущено), которое отвечает на запросы от вашего браузера и отправляет обратно данные, обычно в формате HTML. Веб-браузер интерпретирует эти данные и отображает их в удобной для чтения форме.
- HTML/CSS/JavaScript: Эти технологии используются для создания веб-страниц:
- HTML (HyperText Markup Language): Язык разметки, который используется для создания веб-страниц.
- CSS (Cascading Style Sheets): Язык стилей, который используется для определения внешнего вида и форматирования HTML-документа.
- JavaScript: Язык программирования, который используется для создания интерактивных эффектов внутри веб-страниц.
- Веб-скрапинг: Веб-скрапинг — это процесс использования программ (скраперов) для автоматического сбора данных с веб-страниц. Скраперы делают запросы к веб-страницам, получают HTML-ответы и анализируют эти данные, извлекая нужную информацию.
- Стандарты и соглашения: Нет централизованного управления интернетом, но есть организации, которые разрабатывают стандарты (например, W3C для HTML и CSS). Следование этим стандартам обеспечивает совместимость и доступность содержимого в разных браузерах и устройствах.
Сетевое взаимодействие
О том, как работает компьютерная сеть и как устроен обмен данными в такой сети, можно почитать в нашей статье «Модель взаимодействия открытых систем OSI. Как работает компьютерная сеть?«. Это поможет вам глубоко разобраться в теории и лучше понять работу интернета для написания эффективных веб-скраперов.
Сегодня разберёмся, как компьютеры и смартфоны «общаются» друг с другом через компьютерные сети, используя модель OSI. Это может звучать сложно, но я постараюсь объяснить максимально просто! 🚀
Что такое модель OSI?
Модель OSI (Open Systems Interconnection) — это стандарт, описывающий, как данные передаются от одного компьютера к другому через сеть. Модель состоит из 7 слоёв, каждый из которых выполняет свою уникальную роль.
Как работает модель OSI?
🔹 Физический слой (1-й слой)
Что делает? Передаёт биты данных через физическое устройство (кабели, оптические волокна).
Пример: Передача электрических сигналов по Ethernet-кабелю.
🔹 Канальный слой (2-й слой)
Что делает? Определяет, как данные организованы в пакеты, и управляет доступом к среде передачи данных.
Пример: Ethernet, Wi-Fi (как устройства договариваются о передаче данных).
🔹 Сетевой слой (3-й слой)
Что делает? Определяет маршрут пакетов от отправителя к получателю.
Пример: IP-адресация, маршрутизация пакетов в интернете.
🔹 Транспортный слой (4-й слой)
Что делает? Обеспечивает надёжную передачу данных, контролирует ошибки и управляет потоками данных.
Пример: TCP (устанавливает соединение, гарантирует доставку) и UDP (быстрая, но без гарантий).
🔹 Сеансовый слой (5-й слой)
Что делает? Управляет сессиями связи: устанавливает, управляет и завершает сессии.
Пример: Настройка и поддержка сессий в приложениях.
🔹 Представительский слой (6-й слой)
Что делает? Обеспечивает независимость данных приложения от различий в представлении данных.
Пример: Шифрование, сжатие данных.
🔹 Прикладной слой (7-й слой)
Что делает? Слой, с которым напрямую взаимодействуют пользовательские приложения.
Пример: HTTP для веб-браузеров, FTP для передачи файлов.
Пример работы модели OSI
📧 Представим, что вы отправляете сообщение другу через интернет:
На вашем компьютере: Сообщение начинает свой путь на 7-м слое (прикладном), где оно создаётся в приложении.
Спускаемся вниз по слоям: Сообщение проходит через представительский и сеансовый слои, где оно может быть зашифровано или сжато.
Транспортный слой: Здесь сообщение делится на пакеты, каждый из которых нумеруется для последующей сборки.
Сетевой слой: Определяется маршрут пакетов.
Канальный слой: Устанавливается связь с физическим устройством, данные готовятся к передаче.
Физический слой: Пакеты преобразуются в электрические сигналы и отправляются.
По сети: Данные проходят через маршрутизаторы и коммутаторы, следуя определённому маршруту.
На компьютере друга: Сигналы идут вверх по слоям OSI, восстанавливаясь до исходного сообщения.
Это всего лишь краткое введение в сложный мир сетевых технологий! Для более глубокого понимания переходите по ссылке на полный урок. 💡
HTML
Краткое руководство по языку HTML, вы можете найти в нашей статье. Основная функция веб-браузера — отображение документов HTML (HyperText Markup Language). HTML-документы — это файлы с расширением .html или, реже, .htm.
Как и текстовые файлы, HTML-файлы кодируются с помощью символов plain-text, обычно ASCII. Это означает, что их можно открыть и прочитать с помощью любого текстового редактора.
Пример простого HTML-файла:
<html>
<head>
<title>Простая веб-страница</title>
</head>
<body>
<!-- Этот комментарий не отображается в браузере -->
<h1>Привет, мир!</h1>
</body>
</html>
HTML-файлы — это особый тип файлов XML (Extensible Markup Language). Каждая строка, начинающаяся с < и заканчивающаяся >, называется тегом.
Стандарт XML определяет понятие открывающих или стартовых тегов, таких как <html>, и закрывающих тегов, которые начинаются с </, например </html>. Между стартовыми и закрывающими тегами находится содержимое тегов.
В случаях, когда теги не нуждаются в содержимом, можно использовать самозакрывающиеся теги. Это называется пустыми элементами и выглядит так:
<p />
Теги также могут иметь атрибуты в виде attributeKey=»attribute value», например:
<div class="content">
Lorem ipsum dolor sit amet, consectetur adipiscing elit
</div>
Здесь тег div имеет атрибут class со значением content.
HTML-элемент состоит из стартового тега с опциональными атрибутами, содержимого и закрывающего тега. Элемент также может содержать другие элементы, в этом случае они являются вложенными.
Хотя XML определяет эти основные понятия тегов, содержимого, атрибутов и значений, HTML определяет, какие теги могут быть использованы, что они могут содержать и как они должны интерпретироваться и отображаться браузером.
Например, стандарт HTML определяет использование атрибута class и атрибута id, которые часто используются для организации и контроля отображения HTML-элементов:
<h1 id="main-title">Некоторый заголовок</h1>
<div class="content">
Lorem ipsum dolor sit amet, consectetur adipiscing elit
</div>
Как правило, несколько элементов на странице могут содержать одно и то же значение класса; однако любое значение в поле id должно быть уникальным на этой странице. Таким образом, несколько элементов могут иметь класс content, но только один элемент может иметь id main-title.
Отображение элементов HTML-документа в веб-браузере полностью зависит от того, как веб-браузер, как программное обеспечение, запрограммирован. Если один браузер запрограммирован отображать элемент иначе, чем другой браузер, это приведет к несоответствию в пользовательском опыте.
По этой причине важно согласовать, что именно должны делать HTML-теги, и закрепить это в едином стандарте. Стандарт HTML в настоящее время контролируется Консорциумом Всемирной паутины (W3C). Текущую спецификацию всех HTML-тегов можно найти по адресу: HTML Standard.
Однако формальный стандарт W3C HTML, вероятно, не лучшее место для изучения HTML, если вы никогда с ним не сталкивались. Большая часть веб-скрейпинга включает чтение и интерпретацию сырых HTML-файлов, найденных в Интернете. Если вы никогда не имели дела с HTML, настоятельно рекомендую книгу, такую как «HTML и CSS: Лучшие практики«, чтобы ознакомиться с некоторыми из наиболее распространенных HTML-тегов. Также, я подробно разбирал язык HTML в своей статье на сайте.
CSS
CSS (Cascading Style Sheets) определяет внешний вид HTML-элементов на веб-странице. CSS задает такие свойства, как макет, цвета, позиция, размер и другие, которые превращают скучную HTML-страницу с дефолтными стилями браузера во что-то более привлекательное для современного пользователя.
Используем пример HTML-документа из предыдущего раздела:
<html>
<head>
<title>Простая веб-страница</title>
</head>
<body>
<!-- Этот комментарий не отображается в браузере -->
<h1>Привет, мир!</h1>
</body>
</html>
Соответствующий CSS может выглядеть так:
h1 {
font-size: 20px;
color: green;
}
Этот CSS установит размер шрифта содержимого тега <h1> на 20 пикселей и окрасит текст в зеленый цвет.
Часть h1 в этом CSS называется селектором или CSS-селектором. Этот CSS-селектор указывает, что CSS внутри фигурных скобок будет применен к содержимому любых тегов <h1>.
CSS-селекторы также могут быть написаны для применения стилей только к элементам с определенными атрибутами класса или id. Например, используя следующий HTML:
<h1 id="main-title">Некоторый заголовок</h1>
<div class="content">
Lorem ipsum dolor sit amet, consectetur adipiscing elit
</div>
Соответствующий CSS может быть таким:
h1#main-title {
font-size: 20px;
}
div.content {
color: green;
}
Символ # используется для указания значения атрибута id, а символ . используется для указания значения атрибута класса.
Если значение тега не важно, имя тега можно полностью опустить. Например, этот CSS окрасит содержимое любого элемента с классом content в зеленый цвет:
.content {
color: green;
}
CSS может содержаться как в самом HTML, так и в отдельном CSS-файле с расширением .css. CSS в HTML-файле размещается внутри тегов <style> в заголовке HTML-документа:
<html>
<head>
<style>
.content {
color: green;
}
</style>
...
Чаще всего вы увидите, что CSS импортируется в заголовок документа с помощью тега <link>:
<html>
<head>
<link rel="stylesheet" href="mystyle.css">
...
Как веб-скрейпер, вам не часто придется писать таблицы стилей, чтобы сделать HTML красивым. Однако важно уметь читать и распознавать, как HTML-страница преобразуется CSS, чтобы соотнести то, что вы видите в браузере, с тем, что вы видите в коде.
Например, вы можете быть озадачены, когда HTML-элемент не отображается на странице. Когда вы читаете примененный к элементу CSS, вы видите:
.mystery-element {
display: none;
}
Этот код устанавливает атрибут display элемента в значение none, скрывая его со страницы.
Если вы никогда не сталкивались с CSS ранее, вам, вероятно, не нужно углубленно изучать его для веб-скрейпинга, но вы должны быть знакомы с его синтаксисом и обращать внимание на правила CSS, упомянутые в этой статье.
JavaScript
Когда клиент запрашивает веб-страницу у веб-сервера, сервер выполняет код, создающий эту страницу. Этот код, называемый серверным кодом, может быть простым, например, извлечением статического HTML-файла и его отправкой. Либо это может быть сложное приложение, написанное на Python (лучшем языке), Java, PHP или любом другом популярном серверном языке программирования.
В конечном итоге этот серверный код создает поток данных, который отправляется браузеру и отображается на экране. Но что делать, если вам нужно, чтобы на странице происходили интерактивные действия (например, изменение текста или перетаскивание элемента) без обращения к серверу для выполнения дополнительного кода? Для этого используется клиентский код.
Клиентский код — это любой код, отправленный веб-сервером, но выполняемый браузером клиента. В прежние времена интернета (до середины 2000-х) клиентский код писали на различных языках. Например, вы могли сталкиваться с Java-аплетами и Flash-приложениями. Однако JavaScript стал единственным вариантом для клиентского кода по простой причине: это был единственный язык, поддерживаемый самими браузерами, без необходимости скачивать и обновлять отдельное программное обеспечение (например, Adobe Flash Player) для запуска программ.
JavaScript появился в середине 90-х как новая функция в браузере Netscape Navigator. Он быстро был принят Internet Explorer, став стандартом для обоих основных браузеров того времени.
Несмотря на название, JavaScript почти не имеет ничего общего с Java, языком серверного программирования. За исключением небольшого количества поверхностных синтаксических сходств, это совершенно разные языки.
В 1996 году Netscape (создатель JavaScript) и Sun Microsystems (создатель Java) заключили лицензионное соглашение, позволившее Netscape использовать название «JavaScript», предполагая дальнейшее сотрудничество между двумя языками. Однако это сотрудничество так и не состоялось, и название стало запутанным с тех пор.
Хотя он начинался как скриптовый язык для браузера, которого больше не существует, JavaScript теперь является самым популярным языком программирования в мире. Эта популярность увеличивается благодаря тому, что его также можно использовать на серверной стороне с помощью Node.js. Но его популярность укреплена тем фактом, что это единственный доступный клиентский язык программирования.
JavaScript встраивается в HTML-страницы с помощью тега <script>. JavaScript-код может быть вставлен как содержимое:
<script>
alert('Привет, мир!');
</script>
Либо он может быть указан в отдельном файле с использованием атрибута src:
<a href="http://someprogram.js">http://someprogram.js</a>
В отличие от HTML и CSS, вам, вероятно, не придется читать или писать JavaScript при веб-скрейпинге, но полезно хотя бы немного понять, как он выглядит. Иногда он может содержать полезные данные. Например:
<script>
const data = '{"some": 1, "data": 2, "here": 3}';
</script>
Здесь переменная JavaScript объявляется с помощью ключевого слова const (что означает «константа») и устанавливается в строку формата JSON, содержащую данные, которые можно напрямую парсить веб-скрейпером.
JSON (JavaScript Object Notation) — это текстовый формат, содержащий читаемые данные, легко парсируемый веб-скрейперами и широко распространенный в интернете.
Вы также можете увидеть, как JavaScript делает запрос к другому источнику для получения данных:
<script>
fetch('http://example.com/data.json')
.then((response) => {
console.log(response.json());
});
</script>
Здесь JavaScript создает запрос к http://example.com/data.json и после получения ответа логирует его в консоль (более подробно о «консоли» в следующем разделе).
JavaScript изначально был создан для обеспечения динамической интерактивности и анимации на статичных веб-страницах. Однако сегодня не все динамическое поведение создается с помощью JavaScript. HTML и CSS также имеют функции, позволяющие им изменять содержимое страницы.
Например, CSS-анимация с использованием ключевых кадров позволяет элементам двигаться, изменять цвет, размер или претерпевать другие преобразования при клике или наведении на элемент.
Понимание того, как собраны (часто буквально) движущиеся части веб-сайта, может помочь вам избежать ложных следов при попытке найти данные.
Наблюдение за веб-сайтами с помощью инструментов разработчика
Как лупа ювелира или стетоскоп кардиолога, инструменты разработчика вашего браузера являются неотъемлемой частью практики веб-скрейпинга. Чтобы собирать данные с веб-сайта, вы должны понимать, как он устроен. Инструменты разработчика показывают вам это.
В течение всей статьи мы будем использовать инструменты разработчика, показанные в Google Chrome. Однако инструменты разработчика в Firefox, Microsoft Edge и других браузерах очень похожи друг на друга.
Чтобы получить доступ к инструментам разработчика в меню вашего браузера, используйте следующие инструкции:
Chrome
- Вид → Инструменты разработчика → Инструменты разработчика
Safari
- Safari → Настройки → Дополнительно → Установите галочку «Показывать меню разработчика в строке меню»
Затем, используя меню разработчика: Разработчик → Показать веб-инспектор
Microsoft Edge
- Используя меню: Инструменты → Разработчик → Инструменты разработчика
Firefox
- Инструменты → Инструменты браузера → Инструменты веб-разработчика
Во всех браузерах сочетание клавиш для открытия инструментов разработчика одинаково и зависит от вашей операционной системы:
Mac
- Option + Command + I
Windows
- CTRL + Shift + I
При веб-скрейпинге вы, скорее всего, будете проводить большую часть времени на вкладке «Сеть» (Network) и вкладке «Элементы» (Elements).
Вкладка «Сеть» (Network)
Эта вкладка позволяет отслеживать все сетевые запросы, которые выполняет ваш браузер при загрузке страницы. Здесь вы можете увидеть, какие файлы загружаются, какие данные отправляются и принимаются, а также узнать, какие API-запросы выполняются.
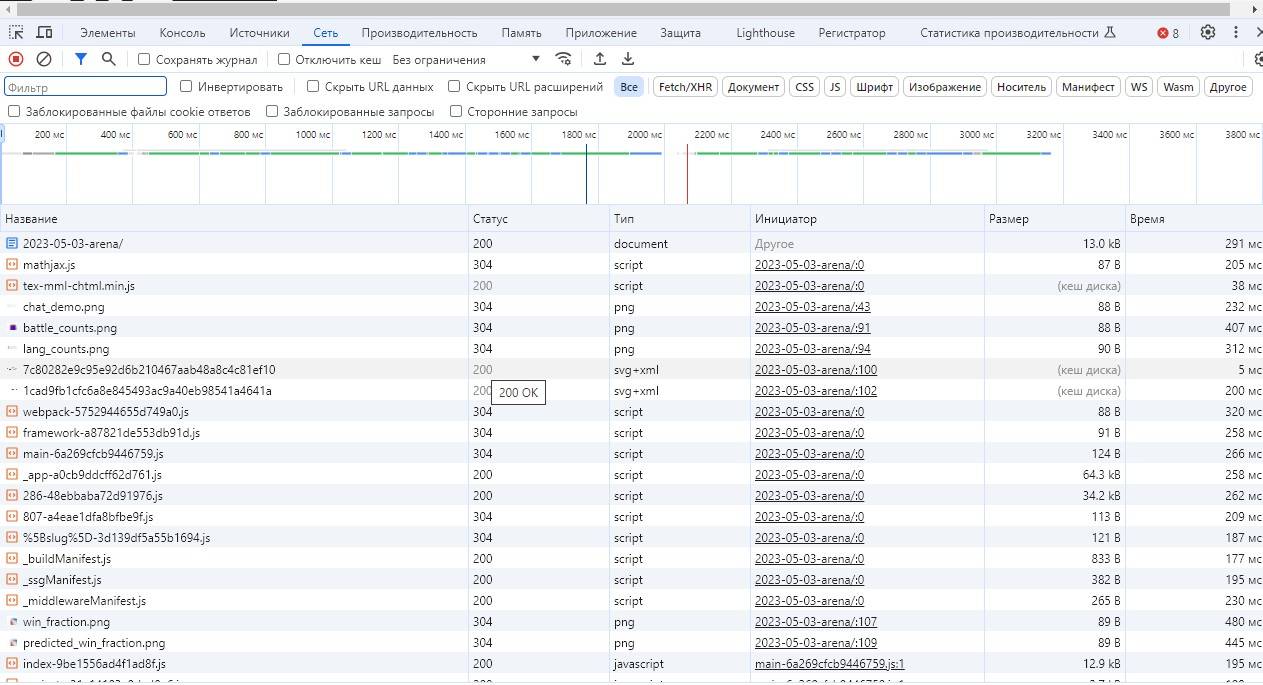
Вкладка «Сеть» показывает все запросы, которые выполняет страница при её загрузке. Если вы никогда раньше не использовали эту вкладку, вас может удивить количество запросов! Для сложных страниц характерно выполнение десятков или даже сотен запросов на загрузку различных ресурсов. В некоторых случаях страницы могут продолжать делать регулярные запросы на протяжении всего времени, пока вы находитесь на них. Например, они могут отправлять данные для программ отслеживания действий или запрашивать обновления.
Ничего не видно на вкладке «Сеть»?
Учтите, что инструменты разработчика должны быть открыты, пока страница выполняет свои запросы, чтобы эти запросы могли быть зафиксированы. Если вы загрузили страницу, не открывая инструменты разработчика, и потом решили проанализировать её, открыв инструменты разработчика, вам, возможно, придется обновить страницу, чтобы снова увидеть выполняемые запросы.
Информация о запросах
Если вы кликнете на отдельный сетевой запрос в вкладке «Сеть», вы увидите всю информацию, связанную с этим запросом. Макет инструмента для анализа сетевых запросов немного отличается в разных браузерах, но в целом позволяет увидеть:
- URL, на который был отправлен запрос
- HTTP-метод, использованный для запроса
- Статус ответа
- Все заголовки и cookies, связанные с запросом
- Отправленные данные (payload)
- Ответ от сервера
Эта информация полезна для написания веб-скрейперов, которые будут имитировать эти запросы для получения тех же данных, которые получает страница.
Вкладка «Элементы» (Elements)
Эта вкладка позволяет вам просматривать структуру HTML-документа, видеть и изменять элементы, а также анализировать и модифицировать CSS-стили. Она особенно полезна для поиска и извлечения нужных данных с веб-страницы.
Используя эти инструменты, вы сможете более эффективно анализировать и извлекать данные с веб-сайтов, что значительно облегчит процесс веб-скрейпинга.
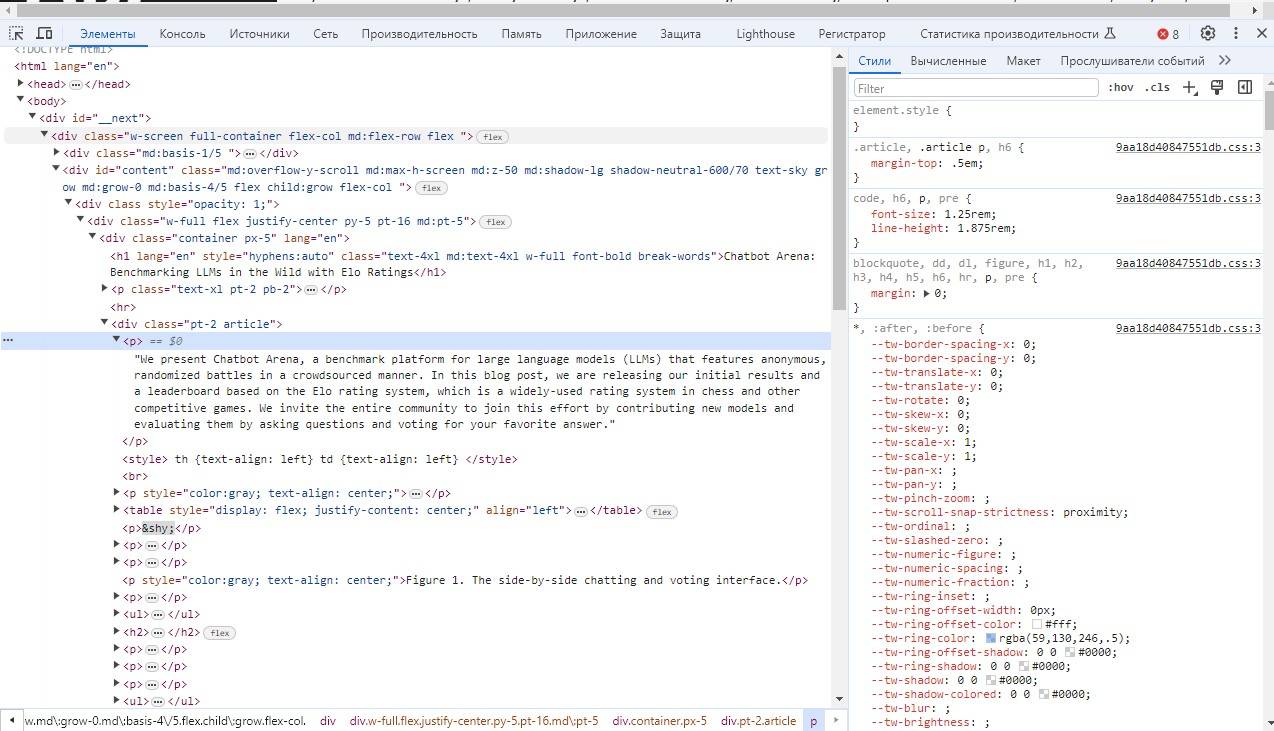
Вкладка «Элементы» используется для изучения структуры и содержимого HTML-файлов. Она очень удобна для анализа конкретных частей данных на странице, чтобы найти HTML-теги, окружающие эти данные, и написать скрейперы для их извлечения.
Когда вы наводите курсор на текст каждого HTML-элемента в вкладке «Элементы», вы увидите, что соответствующий элемент на странице визуально подсвечивается в браузере. Использование этого инструмента — отличный способ исследовать страницы и глубже понять, как они устроены.
Полезные советы
- Обновление страницы: Помните, что чтобы увидеть все сетевые запросы, необходимо открыть инструменты разработчика до загрузки страницы или обновить страницу после их открытия.
- Изучение структуры страницы: Используйте вкладку «Элементы» для анализа HTML и CSS, чтобы лучше понять, как устроены страницы и как извлекать нужные данные.
- Использование сетевых данных: С помощью вкладки «Сеть» вы сможете увидеть, какие запросы выполняет страница, и имитировать их в своем скрейпере.
Законно ли заниматься веб-скрейпингом?
Как осуществлять веб-скрейпинг, не нарушая закон и этические нормы, особенно в контексте российского законодательства?
👉 Развернутый материал доступен по ссылке: Законность и этика веб-скрейпинга
Как избежать юридических проблем при веб-скрейпинге?
🔹 Торговые марки, авторские права, патенты
— Что важно знать? Всегда проверяйте, не нарушаете ли вы права на торговые марки или авторские права, извлекая контент с веб-страниц.
— Пример: Использование логотипов и фирменных названий может требовать разрешения.
🔹 Принцип «добросовестного использования» (Fair Use)
— Что это? Этот принцип позволяет использовать защищённый материал в ограниченных и конкретных случаях без разрешения.
— Пример: Цитирование небольших фрагментов материала в образовательных целях.
🔹 Особенности авторского права в России
— Основные положения: В России авторское право возникает автоматически и действует в течение жизни автора плюс 70 лет после его смерти.
— Важно знать: Необходимо учитывать законодательные рамки при веб-скрейпинге контента.
🔹 Веб-скрейпинг в контексте российского законодательства
— Что следует знать? Особое внимание уделяйте законам, связанным с персональными данными (например, ФЗ-152).
— Совет: Получите разрешение на использование данных, если они содержат персональную информацию.
🔹 Рекомендации для веб-скрейперов в России
— Что рекомендуется? Всегда соблюдайте Условия использования сайта и учитывайте файл robots.txt.
— Пример: Не скрейпите сайты, которые явно запрещают это в своих правилах.
🔹 Авторские права и искусственный интеллект
— Тренды: Учитывайте новые законодательные инициативы, касающиеся использования ИИ для анализа и создания контента.
— Совет: Следите за изменениями в законодательстве об ИИ и авторских правах.
🔹 Нарушение Права на Вещи (Trespass to Chattels)
— Как это связано с веб-скрейпингом? В России аналогичные принципы могут применяться при несанкционированном доступе к серверам.
— Совет: Избегайте чрезмерной нагрузки на серверы при скрейпинге.
🔹 Регулирование активности ваших ботов
— Что нужно делать? Настройте свои скрейпинг боты так, чтобы они не создавали чрезмерную нагрузку на сайты.
— Пример: Ограничьте количество запросов в секунду.
🔹 Файл robots.txt и Условия использования сайта
— Синтаксис протокола исключения роботов: Убедитесь, что ваш скрейпер уважает правила в файле robots.txt.
— Совет: Проверяйте robots.txt и соблюдайте указанные там ограничения.
🔹 Кэш Google и веб-скрейпинг
— Как это использовать? Иногда информацию можно извлечь из кэша поисковых систем, не обращаясь напрямую к сайту.
— Совет: Используйте кэш как альтернативный источник данных, если это возможно.
Этот материал — лишь введение в сложный мир веб-скрейпинга и его законности. Для более глубокого понимания перейдите по ссылке на полную статью.
Применение веб-скрапинга
Хотя веб-скрапинг может быть полезен практически для любого бизнеса, главное — понять, как именно его применить. Подобно искусственному интеллекту или программированию в целом, веб-скрапинг не является волшебной палочкой, которая сразу улучшит ваши показатели. Для эффективного использования веб-скрапинга требуется разработать стратегию и тщательно спланировать процесс. Нужно определить конкретные проблемы, понять, какие данные необходимы для их решения, и разработать алгоритмы, которые позволят вашему скраперу получать эти данные.
Классификация проектов
При планировании проекта по веб-скрапингу важно понять, к какой категории он относится.
- «Широкий» или «Целевой» веб-скрапинг?
- Целевой веб-скрапинг:
- Скрепинг одного сайта или даже набора страниц внутри сайта. Это самый узкий и целевой вид скрапинга.
- Скрепинг фиксированного числа известных сайтов. Это тоже целевой скрапинг, но потребует немного больше времени на написание индивидуального кода для каждого сайта и архитектуры скрапера.
- Широкий веб-скрапинг:
- Скрепинг большого числа неизвестных сайтов с динамическим обнаружением новых целей. Здесь требуется создать краулер, который автоматически определяет и делает предположения о структуре сайтов.
- Целевой веб-скрапинг:
- Разовый или постоянный скрапинг?
- Разовый проект:
- Быстрый и недорогой в написании. Код не обязательно должен быть идеальным. Итог — данные, которые можно передать в формате Excel или CSV, после чего код можно удалить.
- Постоянный проект:
- Требует более устойчивого кода, который легко поддерживать. Также может потребоваться инфраструктура для мониторинга, чтобы обнаруживать ошибки или превышение времени и ресурсов.
- Разовый проект:
- Конечный продукт или анализ данных?
- Простое получение данных:
- Скрапер сохраняет данные в базу в исходном виде или с минимальной обработкой (например, удаление знаков валюты из цен).
- Глубокий анализ данных:
- Может быть неизвестно, какие данные будут важны. В этом случае нужно продумать архитектуру скрапера более тщательно.
- Простое получение данных:
Рекомендации
Рассматривайте, к каким категориям относятся ваши проекты и как их масштабы могут быть изменены для удовлетворения потребностей вашего бизнеса. Это поможет вам лучше планировать и реализовывать проекты по веб-скрапингу, максимально эффективно используя их потенциал.
Веб-скрапинг для электронной коммерции
Подобные запросы обычно поступают от владельцев конкурирующих сайтов или от тех, кто проводит исследования для запуска нового продукта или выхода на рынок. Первая метрика, которая приходит на ум в электронной коммерции, — это «цены». Вы хотите узнать, как ваша цена сравнивается с ценами конкурентов. Однако существует множество других полезных данных, которые стоит собирать.
Многие, но не все продукты, бывают различных размеров, цветов и стилей. Эти вариации могут влиять на стоимость и наличие товара. Полезно отслеживать все доступные вариации для каждого продукта, а также основные списки продуктов. Для каждой вариации вы можете найти уникальный идентификационный код SKU (stock-keeping unit), который уникален для каждой вариации продукта и сайта электронной коммерции (например, у Target будет свой SKU для каждого продукта, отличный от SKU у Walmart, но они будут оставаться неизменными при повторной проверке). Даже если SKU не виден сразу на сайте, его можно найти в HTML-коде страницы или в API на JavaScript, который загружает данные о продукте.
При скрапинге сайтов электронной коммерции также важно записывать количество доступных единиц товара. Как и в случае с SKU, это количество может быть скрыто в HTML или в API сайта. Обязательно отслеживайте, когда продукты отсутствуют на складе! Это поможет оценить спрос на рынке и, возможно, повлиять на ценообразование ваших собственных продуктов, если они есть в наличии.
Когда продукт продается со скидкой, на сайте обычно указаны как цена со скидкой, так и оригинальная цена. Записывайте обе цены отдельно. Отслеживая скидки с течением времени, можно анализировать стратегии продвижения и скидок ваших конкурентов.
Отзывы и рейтинги продуктов также являются полезной информацией для сбора. Конечно, вы не можете напрямую отображать текст отзывов с сайтов конкурентов на своем сайте. Однако анализ данных из этих отзывов может помочь понять, какие продукты популярны или находятся в тренде.
Советы по веб-скрапингу для электронной коммерции
- Сравнение цен: Собирайте данные о ценах на аналогичные продукты у конкурентов, чтобы оценить свою конкурентоспособность.
- Вариации продуктов: Отслеживайте размеры, цвета и стили продуктов, а также их уникальные коды SKU.
- Наличие на складе: Следите за количеством доступных товаров и за тем, когда продукты отсутствуют на складе.
- Анализ скидок: Записывайте как оригинальные, так и скидочные цены, чтобы понимать стратегии скидок конкурентов.
- Отзывы и рейтинги: Анализируйте отзывы и рейтинги, чтобы узнать, какие продукты популярны среди покупателей.
Веб-скрапинг для маркетинга
Управление брендом и маркетинг в интернете часто требуют сбора большого объема данных. Вместо того чтобы самостоятельно искать упоминания в социальных сетях или проводить часы в поиске информации о компании, вы можете использовать веб-скраперы для автоматизации этих задач.
Защита бренда и мониторинг репутации
Злоумышленники могут использовать веб-скраперы для копирования сайтов с целью продажи поддельных товаров или обмана клиентов. Однако веб-скраперы также могут помочь в борьбе с этим, сканируя результаты поисковых систем на предмет мошеннического или неправомерного использования торговых марок и другой интеллектуальной собственности компании. Некоторые компании, такие как MarqVision, предлагают такие веб-скраперы как услугу, позволяя брендам аутсорсить процесс сканирования сети, обнаружения мошенничества и подачи уведомлений о нарушении.
Не все упоминания бренда являются нарушением. Если вашу компанию упоминают для комментариев или отзывов, важно быть в курсе! Веб-скраперы могут собирать и отслеживать общественное мнение и восприятие компании и ее бренда.
Анализ конкурентов
Отслеживая свой бренд в интернете, не забывайте о конкурентах. Вы можете скрапить информацию о людях, которые оставляют отзывы о продуктах конкурентов или упоминают их бренды, чтобы предложить им скидки или рекламные акции.
Социальные медиа
Социальные медиа — важный элемент онлайн-маркетинга. Преимущество скрапинга социальных сетей в том, что существует всего несколько крупных сайтов, для которых можно создать целевые скраперы. Эти сайты содержат миллионы структурированных постов с одинаковыми атрибутами (лайки, репосты, комментарии), которые легко сравнивать.
Однако, получение данных из социальных сетей может быть затруднено. Некоторые сайты, такие как Twitter, предоставляют API, доступные бесплатно или за плату. Другие социальные сети защищают свои данные с помощью технологий и юридических мер. Рекомендуется проконсультироваться с юридическим отделом компании перед скрапингом таких сайтов, как Facebook и LinkedIn.
Отслеживание метрик
Отслеживание метрик (лайков, репостов и комментариев) по постам, связанным с вашим брендом, может помочь выявить тренды и возможности для взаимодействия. Анализ популярности в зависимости от длины контента, включения изображений/медиа и использования языка может показать, что наилучшим образом резонирует с вашей целевой аудиторией.
Работа с микро- и нано-инфлюенсерами
Если привлечение инфлюенсера с сотнями миллионов подписчиков не входит в бюджет вашей компании, рассмотрите вариант работы с микро- или нано-инфлюенсерами — пользователями с небольшими аудиториями, которые могут даже не считать себя инфлюенсерами. Создание веб-скрапера для поиска и таргетинга аккаунтов, которые часто публикуют посты на темы, связанные с вашим брендом, может быть полезным.
Рекомендации по веб-скрапингу для маркетинга
- Защита бренда: Используйте скраперы для обнаружения и борьбы с мошенническим использованием вашего бренда.
- Мониторинг отзывов: Отслеживайте отзывы и упоминания вашей компании для анализа общественного мнения.
- Анализ конкурентов: Скрапьте данные о конкурентах, чтобы предложить их клиентам выгодные предложения.
- Социальные медиа: Используйте скрапинг для анализа активности в социальных сетях и выявления трендов.
- Работа с инфлюенсерами: Найдите микро- и нано-инфлюенсеров для более доступного и целевого маркетинга.
Веб-скрапинг для академических исследований
Хотя многие примеры в этой статье связаны с бизнесом, веб-скрапинг также активно используется в научных исследованиях. Веб-скраперы применяются в медицине, социологии, психологии и многих других областях.
Примеры использования в академической среде
Курсы и программы:
- В Ратгерском университете есть курс «Computational Social Science» («Компьютерные социальные науки»), где студентов учат веб-скрапингу для сбора данных для научных проектов.
- В университете Осло на курсе «Collecting and Analyzing Big Data» («Сбор и анализ больших данных») эта скрапинг включен в учебную программу.
Исследования в области здравоохранения:
- В 2017 году проект, поддерживаемый Национальными институтами здравоохранения США, использовал веб-скрапинг для сбора данных о заключенных в американских тюрьмах, чтобы оценить количество заключенных, инфицированных ВИЧ. Этот проект вызвал обширное этическое обсуждение, взвешивающее пользу исследования и риск нарушения конфиденциальности заключенных. Исследование продолжилось, но перед использованием веб-скрапинга в медицине рекомендуется тщательно рассмотреть этические аспекты проекта.
- Другое исследование в области здравоохранения анализировало сотни комментариев к статьям в газете The Guardian на тему ожирения, исследуя риторику этих комментариев. Хотя это исследование было меньше по масштабу, оно показывает, что веб-скрапинг можно использовать и для проектов, требующих «малых данных» и качественного анализа.
Исследования в области образования:
- В 2016 году было проведено исследование, которое использовало веб-скрапинг для сбора и качественного анализа маркетинговых материалов всех канадских общественных колледжей. Исследователи выяснили, что современные удобства и «нетрадиционные организационные символы» наиболее популярны в продвижении этих учреждений.
Экономические исследования:
- Банк Японии опубликовал статью о применении веб-скрапинга для получения «альтернативных данных» — данных, которые обычно не используются банками, таких как статистика ВВП и финансовые отчеты компаний. В этой статье они отметили, что одним из источников альтернативных данных являются веб-скраперы, которые они используют для корректировки индексов цен.
Рекомендации по использованию веб-скрапинга в исследованиях
- Этика: Всегда учитывайте этические аспекты использования веб-скрапинга, особенно в исследованиях, связанных с медициной и конфиденциальными данными.
- Масштаб исследований: Веб-скрапинг подходит как для крупных исследований с большими данными, так и для проектов с «малыми данными» и качественным анализом.
- Разнообразие данных: Веб-скрапинг позволяет собирать данные из различных источников, что может быть полезно для анализа и принятия решений в различных областях науки.
Создание продукта с помощью веб-скрапинга
У вас есть бизнес-идея, и вам нужна база данных с общедоступной информацией, чтобы воплотить её в жизнь? Не можете найти доступный и удобный источник этой информации? Вам может помочь веб-скрапинг.
Веб-скраперы могут быстро предоставить данные, необходимые для запуска минимально жизнеспособного продукта (MVP). Вот несколько ситуаций, в которых веб-скрапинг может быть наилучшим решением:
- Туристический сайт с списком популярных достопримечательностей и мероприятий:
- В этом случае простая географическая информация не подойдет. Вам нужно знать, что люди хотят увидеть статую Христа-Искупителя, а не просто посетить Рио-де-Жанейро, Бразилия. Справочник бизнесов тоже не подойдет. Хотя люди могут быть заинтересованы в посещении Британского музея, супермаркет Sainsbury’s по соседству не имеет такой же привлекательности. Однако существует множество сайтов с отзывами о путешествиях, которые уже содержат информацию о популярных туристических достопримечательностях.
- Блог с обзорами продуктов:
- Скрапьте список названий продуктов и ключевых слов или описаний, а затем используйте свой любимый генеративный AI для заполнения остальной части контента.
- Говоря об искусственном интеллекте, этим моделям часто нужны данные — и много! Если вы хотите предсказать тренды или генерировать реалистичный текст, веб-скрапинг часто является лучшим способом получить обучающий набор данных для вашего продукта.
- Бизнес-услуги с отраслевыми знаниями:
- Многие бизнес-услуги требуют наличия тщательно охраняемых отраслевых знаний, которые могут быть дорогими или труднодоступными, например, списки поставщиков промышленных материалов, контактная информация экспертов в узких областях или открытые вакансии по компаниям. Веб-скрапинг может собрать эти фрагменты информации из различных источников в интернете, позволяя вам создать всеобъемлющую базу данных с относительно низкими начальными затратами.
Преимущества веб-скрапинга для создания продукта
- Быстрый доступ к данным:
- Веб-скрапинг позволяет быстро собирать данные из различных источников, ускоряя процесс создания вашего продукта.
- Экономичность:
- В отличие от покупки готовых баз данных, веб-скрапинг может быть более доступным вариантом, особенно если вам нужны специфические данные, которые сложно найти в открытом доступе.
- Актуальность информации:
- Скраперы можно настроить на регулярное обновление данных, что обеспечит актуальность вашей базы данных.
- Гибкость:
- Вы можете настроить веб-скраперы для сбора именно той информации, которая нужна для вашего бизнеса, будь то отзывы, цены, контакты или другие данные.
Советы по использованию веб-скрапинга
- Этика и законность: Убедитесь, что вы соблюдаете все юридические нормы и этические стандарты при скрапинге данных.
- Качество данных: Настройте скраперы таким образом, чтобы они собирали чистые и структурированные данные, минимизируя необходимость дальнейшей обработки.
- Автоматизация: Используйте инструменты автоматизации для регулярного обновления вашей базы данных и поддержания её актуальности.
Веб-скрапинг в туристической отрасли
Если вы планируете начать бизнес, связанный с путешествиями, или просто хотите сэкономить на следующем отпуске, туристическая индустрия предоставляет множество возможностей для веб-скрапинга.
Применение веб-скрапинга в туризме
Гостиницы, авиалинии и аренда автомобилей:
- В этих секторах мало продуктовых различий и множество конкурентов. Цены часто похожи и изменяются в зависимости от рыночных условий.
- Крупные сайты, такие как Kayak и Trivago, могут позволить себе платить за API или получать их бесплатно, но все компании начинали с чего-то малого. Веб-скрапинг — отличный способ начать новый агрегатор путешествий, который находит лучшие предложения для пользователей.
Первый проект для обучения:
- Даже если вы не планируете начинать новый бизнес, написание скрапера для туристических сайтов — отличная идея для первого проекта. Объем данных и частые изменения этих данных создают интересные инженерные задачи.
Преимущества и особенности веб-скрапинга туристических сайтов
Актуальность данных:
- Цены на билеты, гостиницы и аренду автомобилей часто меняются. Скрапер может помочь отслеживать эти изменения и находить лучшие предложения.
Средний уровень защиты от скрапинга:
- Туристические сайты хотят быть проиндексированными поисковыми системами и делают свои данные доступными и удобными для пользователей. Однако конкуренция между туристическими сайтами может требовать использования более сложных техник скрапинга.
- Внимание к заголовкам браузера и cookies — хороший первый шаг для обхода защит.
Примеры использования
- Агрегаторы туристических услуг:
- Скрапинг данных с различных сайтов для создания агрегатора, который покажет пользователям лучшие предложения по билетам, гостиницам и аренде автомобилей.
- Мониторинг цен:
- Написание скрапера для отслеживания изменений цен на авиабилеты и гостиницы, чтобы поймать самые выгодные предложения.
- Персональные проекты:
- Использование скрапинга для планирования личных путешествий, экономии на билетах и гостиницах.
Советы по веб-скрапингу туристических сайтов
- Изучение структуры данных:
- Изучите HTML-код и API-ответы целевых сайтов для понимания структуры данных.
- Обход защит:
- Если сайт блокирует ваш скрапер, попробуйте использовать другой сайт с аналогичными данными.
- Обратите внимание на заголовки запросов и cookies, чтобы избежать блокировок.
- Автоматизация:
- Настройте автоматический сбор и обновление данных, чтобы всегда иметь актуальную информацию.
- Этика и законность:
- Убедитесь, что ваши действия соответствуют законам и правилам использования данных целевых сайтов.
Веб-скрапинг для продаж
Веб-скраперы — идеальный инструмент для получения лидов для продаж. Если вы знаете сайт с контактной информацией людей из вашей целевой аудитории, остальное будет несложно. Независимо от того, насколько нишевая ваша область, веб-скрапинг может значительно облегчить процесс сбора данных.
Примеры использования веб-скрапинга в продажах
Сбор целевых аудиторий:
- В моей практике я помогал клиентам собирать списки тренеров молодежных спортивных команд, владельцев фитнес-залов, продавцов косметики и многих других целевых аудиторий.
Рекрутинг:
- В индустрии рекрутинга, которую можно рассматривать как часть продаж, веб-скрапинг используется для сбора профилей кандидатов и объявлений о вакансиях. Из-за строгих анти-скрапинг политик LinkedIn, часто используются плагины, такие как Instant Data Scraper или Dux-Soup, которые помогают рекрутерам просматривать профили кандидатов и собирать данные.
Каталоги компаний:
- Сайты вроде Yelp помогают находить оффлайн-бизнесы по различным атрибутам, таким как стоимость услуг, принимают ли они кредитные карты, предлагают ли доставку или обслуживание кейтеринга, продают ли алкоголь и т.д. Yelp содержит информацию не только о ресторанах, но и о плотниках, розничных магазинах, бухгалтерах, автосервисах и многом другом. Контактная информация на таких сайтах может использоваться для коммерческих предложений.
Директории сотрудников:
- Скрапинг директорий сотрудников или карьерных сайтов может быть ценным источником имен сотрудников и их контактной информации, что помогает делать более персонализированные коммерческие предложения.
Технические аспекты и стратегии
Использование структурированных данных:
- Проверка наличия структурированных данных (например, тэгов Google) на целевых сайтах может помочь построить широкий веб-скрапер, который будет собирать надежную и хорошо структурированную контактную информацию.
Изучение подкапотного кода:
- Анализ исходного кода сайта может дать много полезной информации. Какие системы управления контентом используются? Какие подсказки о серверной инфраструктуре можно найти? Есть ли на сайте чат-бот или аналитическая система? Эти данные могут быть полезны для понимания технологий, которые использует потенциальный клиент, и помогут в продажах и маркетинге.
Советы по веб-скрапингу для продаж
- Этика и законность:
- Убедитесь, что ваш веб-скрапинг соответствует юридическим нормам и этическим стандартам, особенно при работе с личной информацией.
- Качество данных:
- Старайтесь собирать только актуальные и точные данные, чтобы минимизировать количество последующей обработки.
- Автоматизация:
- Используйте инструменты автоматизации для регулярного обновления данных и поддержания их актуальности.
- Защита от анти-скрапинг мер:
- Будьте готовы к обходу мер защиты от скрапинга. Внимание к заголовкам запросов и cookies может помочь обойти блокировки.
Скрапинг результатов поисковых систем (SERP)
Скрапинг страниц результатов поисковых систем (SERP) — это практика извлечения полезных данных непосредственно из результатов поиска, не заходя на сами страницы по ссылкам.
Преимущества скрапинга SERP
Единый формат:
- Результаты поисковых систем имеют известный и постоянный формат. Страницы, на которые ссылаются поисковые системы, имеют разные и неизвестные форматы, что делает работу с ними сложной и трудоемкой.
Экономия времени и ресурсов:
- Поисковые системы используют метаданные, умное программирование и AI, чтобы извлекать краткие описания страниц, статистику и ключевые слова. Используя их результаты, а не пытаясь воссоздать их самостоятельно, вы экономите много времени и денег.
Примеры использования скрапинга SERP
- Сбор данных о спортивных лигах:
- Если вам нужны данные о результатах всех крупных американских спортивных лиг за последние 40 лет, вы можете найти различные источники. Например, сайт NHL предоставляет данные в одном формате, а сайт NFL — в другом. Однако, поисковый запрос в Google, например, «nba standings 2008» или «mlb standings 2004», даст вам результаты в едином формате, с возможностью углубления в отдельные результаты игр и статистику игроков.
- Мониторинг поисковых результатов:
- Вы можете отслеживать, какие сайты появляются и в каком порядке для определенных поисковых запросов. Это поможет мониторить ваш бренд и следить за конкурентами.
- Реклама в поисковых системах:
- Если вы проводите рекламную кампанию в поисковых системах или планируете запустить ее, вы можете отслеживать только рекламные результаты: какие объявления появляются, в каком порядке и как они меняются со временем.
Использование других поисковых сервисов
Не ограничивайтесь основной страницей результатов поиска. Google, например, имеет Google Maps, Google Images, Google Shopping, Google Flights, Google News и другие. Все они являются поисковыми системами для разных типов контента, которые могут быть полезны для вашего проекта.
Понимание работы поисковых систем
Даже если вы не извлекаете данные непосредственно из поисковых систем, полезно знать, как они находят и маркируют данные для отображения в специальных функциях и расширениях результатов поиска. Поисковые системы не пытаются угадать, как отображать данные; они просят разработчиков форматировать контент специально для отображения третьими сторонами, такими как они сами.
Документация по структурированным данным Google
Документацию по структурированным данным Google можно найти здесь. Если вы встретите эти данные при скрапинге веба, вы будете знать, как их использовать. Структурированные данные помогут вам лучше понять, как поисковые системы представляют информацию, и использовать это знание для оптимизации ваших скрапинг-проектов.
Написание вашего первого веб-скрапера
Когда вы только начинаете работать с веб-скрапингом, вам становится ясно, насколько много работы выполняют за нас браузеры. Если отбросить все слои оформления (HTML, CSS), программирования (JavaScript) и отображения изображений, то «голый» веб может выглядеть достаточно сложно и непонятно.
В этой статье мы будем учиться работать с этими «голыми» данными напрямую, без помощи браузера. Мы начнем с самого базового – отправки GET-запроса. GET-запрос – это просто запрос на получение данных с определенной веб-страницы от сервера. Вы узнаете, как получить HTML-код страницы и как извлечь из этого кода нужные данные.
Давайте разберемся подробнее:
- GET-запрос – это ваш способ сказать серверу: «Привет, дай мне данные этой страницы». Это самый распространенный тип запроса в интернете.
- HTML-код страницы – это то, что вы обычно видите в браузере в удобочитаемой форме, но при веб-скрапинге вы будете работать с его исходным кодом.
- Извлечение данных – это процесс выборки только тех данных, которые вам нужны, например, текст статей, ссылки, информация о продуктах и т.д., из всего HTML-кода.
Этот процесс может включать в себя использование специализированных библиотек и инструментов, но основная идея всегда одна – получить нужные данные из общей массы информации.
Следующие шаги будут направлены на то, чтобы научить вас, как это делается на практике, начиная с самых азов.
Установка и использование Jupyter
Если вы еще не использовали Jupyter Notebook, то стоит знать, что это отличный инструмент для организации и работы с множеством маленьких, но связанных между собой фрагментов кода на Python. Каждый фрагмент кода размещается в блоке, который называется ячейкой. Выполнить код в ячейке можно, нажав Shift + Enter или кликнув по кнопке «Run» в верхней части страницы.
Проект Jupyter начался как ответвление от проекта IPython (Interactive Python) в 2014 году. Эти ноутбуки были разработаны для выполнения кода Python прямо в браузере доступным и интерактивным способом, что очень удобно для обучения и презентаций.
Как установить Jupyter Notebook:
- Откройте терминал или командную строку.
- Введите и выполните команду
pip install notebook
Это установит Jupyter Notebook на ваш компьютер.
После установки вы получите доступ к команде jupyter, которая позволяет запустить веб-сервер.
- В терминале перейдите в каталог с файлами:
cd путь/к/каталогу - Запустите Jupyter Notebook, используя команду:
jupyter notebook
- Это команда запустит веб-сервер на порту 8888.
Если у вас открыт веб-браузер, новая вкладка должна открыться автоматически. Если этого не произошло, скопируйте URL, указанный в терминале (вместе с предоставленным токеном), и вставьте его в адресную строку вашего браузера.
- Jupyter Notebook — это интерактивная среда, которая позволяет вам создавать и распространять документы, содержащие живой код, уравнения, визуализации и пояснительный текст.
- Ячейки в Jupyter Notebook могут содержать код или текст (например, markdown для форматирования). Это делает их идеальными для того, чтобы сопроводить код пояснениями и делать заметки.
- Shift + Enter запускает текущую ячейку и переходит к следующей. Если вы хотите запустить код и остаться в текущей ячейке, используйте Ctrl + Enter.
- Интерактивность Jupyter делает его очень удобным для экспериментов: вы можете изменять код и сразу видеть результаты.
Эти особенности делают Jupyter предпочтительным инструментом не только для анализа данных, но и для обучения программированию, так как они позволяют легко визуализировать процесс работы кода и делать обучение более интерактивным и понятным.
Соединение с интернетом
В первом разделе этой статьи мы подробно рассмотрели, как интернет передаёт пакеты данных по проводам от браузера к веб-серверу и обратно. Когда вы открываете браузер, вводите google.com и нажимаете Enter, именно это и происходит — данные в форме HTTP-запроса передаются с вашего компьютера, а веб-сервер Google отвечает HTML-файлом, который представляет данные в корне google.com.
Но где в этом обмене пакетами и фреймами на самом деле участвует веб-браузер? Нигде. Фактически, ARPANET (первая общедоступная сеть с пакетной коммутацией) появилась за по меньшей мере 20 лет до первого веб-браузера, Nexus.
Да, веб-браузер — это полезное приложение для создания этих пакетов информации, которое говорит вашей операционной системе отправлять их и интерпретировать полученные данные как красивые картинки, звуки, видео и текст. Однако веб-браузер — это всего лишь код, и этот код можно разобрать на составные части, переписать, повторно использовать и заставить делать всё, что вы хотите. Веб-браузер может указать процессору отправлять данные приложению, которое управляет вашим беспроводным (или проводным) интерфейсом, но вы можете сделать то же самое на Python всего тремя строками кода:
from urllib.request import urlopen
html = urlopen('https://victor-komlev.ru/')
print(html.read())Эта команда выводит полный HTML-код страницы, расположенной по URL https://victor-komlev.ru/. Точнее, это выводит HTML-файл index.html, который находится в директории <web root>/ на сервере по доменному имени https://victor-komlev.ru/.
Почему важно начать думать об этих адресах как о «файлах», а не «страницах»? Большинство современных веб-страниц имеют множество связанных с ними ресурсных файлов. Это могут быть файлы изображений, файлы JavaScript, файлы CSS или любой другой контент, к которому привязана запрашиваемая вами страница. Когда веб-браузер встречает тег вида <img src="cuteKitten.jpg">, браузер знает, что ему нужно сделать ещё один запрос к серверу, чтобы получить данные по адресу cuteKitten.jpg для полной отрисовки страницы для пользователя.
Конечно, ваш Python-скрипт пока не содержит логики для возврата и запроса нескольких файлов (пока что); он может читать только один HTML-файл, который вы непосредственно запросили.
from urllib.request import urlopenозначает именно то, что кажется: оно смотрит на модуль Python request (который находится в библиотеке urllib) и импортирует только функцию urlopen.
urllib — это стандартная библиотека Python (это значит, что вам не нужно устанавливать что-то дополнительно, чтобы запустить этот пример), и содержит функции для запроса данных через веб, обработки cookies и даже изменения метаданных, таких как заголовки и ваш user agent. Мы будем использовать urllib достаточно часто, поэтому я рекомендую вам прочитать документацию Python для этой библиотеки.
urlopen используется для открытия удалённого объекта через сеть и его чтения. Поскольку это достаточно универсальная функция (она может читать HTML-файлы, файлы изображений или любой другой файловый поток с лёгкостью), мы будем использовать её довольно часто.
- HTTP-запросы — это способ, которым ваш браузер общается с веб-серверами в Интернете. Когда вы вводите адрес в браузер, он отправляет HTTP-запрос на сервер, который отвечает HTML-кодом страницы.
- HTML-файл — это структурированный текстовый документ, который ваш браузер читает и превращает в визуально приятные веб-страницы.
- Изображения и ресурсы — когда ваш браузер получает HTML и видит ссылки на другие файлы (например,
<img src="image.jpg">), он делает дополнительные запросы, чтобы загрузить эти ресурсы и корректно отобразить всю страницу. - urllib и urlopen — это инструменты в Python, которые позволяют вам делать HTTP-запросы прямо из вашего скрипта. Это означает, что вы можете программно запросить веб-страницы и работать с их данными, не открывая браузер.
Введение в BeautifulSoup
Библиотека BeautifulSoup была названа в честь стихотворения Льюиса Кэрролла из «Алисы в Стране чудес». В этой истории стихотворение поётся персонажем по имени Мокрая Черепаха (что само по себе является каламбуром на популярное в викторианскую эпоху блюдо из говядины, имитирующее черепаховый суп).
Как и её литературный аналог из Страны чудес, BeautifulSoup пытается внести смысл в бессмыслицу; она помогает форматировать и организовывать беспорядочный веб, исправляя плохой HTML и предоставляя легко обходимые объекты Python, представляющие структуры XML.
Описание работы с BS4 есть в нашей статье.
Установка BeautifulSoup
Поскольку библиотека BeautifulSoup не входит в стандартную библиотеку Python, её нужно установить. Если вы уже имеете опыт установки библиотек Python, используйте ваш любимый инсталлятор и переходите к следующему разделу, «Запуск BeautifulSoup».
Для тех, кто не устанавливал библиотеки Python (или нуждается в повторении информации), этот общий метод будет использоваться для установки множества библиотек.
Мы будем использовать библиотеку BeautifulSoup 4 (также известную как BS4) на протяжении всей статьи. Полная документация и инструкции по установке BeautifulSoup 4 могут быть найдены на Crummy.com.
Если вы уже работали с Python, вероятно, использовали менеджер пакетов для Python (pip). Если нет, я настоятельно рекомендую установить pip для установки BeautifulSoup и других пакетов Python, используемых в этой статье.
В зависимости от установщика Python, pip может быть уже установлен на вашем компьютере. Чтобы проверить, попробуйте набрать в командной строке:
$ pipЭта команда должна привести к выводу текста помощи pip в вашем терминале. Если команда не распознаётся, вам, возможно, потребуется установить pip. Pip может быть установлен различными способами, например, с помощью apt-get на Linux или brew на macOS. Независимо от вашей операционной системы, вы также можете скачать файл установки pip по адресу https://bootstrap.pypa.io/get-pip.py, сохранить этот файл как get-pip.py и запустить его с Python:
$ python get-pip.pyПри установке python на Windows, у вас может быть не добавлена папка с pip и puthon в переменную окружения PATH. В этом случае, pip не запустится. Как это исправляется, я описал здесь.
Наконец, используйте pip для установки BeautifulSoup:
$ pip install bs4И всё готово! Теперь BeautifulSoup будет распознаваться как библиотека Python на вашем компьютере. Вы можете проверить это, открыв терминал Python и импортировав её:
$ python
>>> from bs4 import BeautifulSoupИмпорт должен завершиться без ошибок.
- BeautifulSoup — это библиотека для парсинга HTML и XML документов. Она создаёт дерево синтаксического разбора для страниц, что делает возможным поиск и изменение структуры и атрибутов документов очень удобным способом.
- Почему BeautifulSoup? Потому что она превращает хаотичный HTML-код, который часто встречается в реальном вебе, в структурированную иерархию данных. Это делает извлечение данных проще и интуитивно понятнее.
- Установка через pip — это стандартный и самый простой способ добавления внешних библиотек в ваш проект на Python.
pipавтоматически скачивает библиотеку из репозитория PyPI и устанавливает её. - Использование BeautifulSoup начинается с импорта:
from bs4 import BeautifulSoup. После этого вы можете использовать объекты BeautifulSoup для разбора HTML-кода, который вы получаете в результате запросов к веб-серверам.
Работа с виртуальными окружениями для организации библиотек
Если вы планируете работать над несколькими проектами на Python, или вам нужен способ легко упаковать проекты вместе со всеми связанными библиотеками, или вы беспокоитесь о возможных конфликтах между установленными библиотеками, вы можете использовать виртуальное окружение Python. Это поможет держать все компоненты изолированными и упростит их управление.
Когда вы устанавливаете библиотеку Python без виртуального окружения, она устанавливается глобально. Обычно это требует прав администратора и делает эту библиотеку доступной для всех пользователей и проектов на компьютере. К счастью, создать виртуальное окружение очень просто:
$ virtualenv scrapingEnvЭта команда создаёт новое окружение с именем scrapingEnv, которое вам нужно активировать для использования:
$ cd scrapingEnv/
$ source bin/activateПосле активации окружения вы увидите название этого окружения в приглашении командной строки, что напомнит вам, что вы работаете именно в нём. Все библиотеки, которые вы устанавливаете, и скрипты, которые запускаете, будут работать в рамках этого виртуального окружения.
Работая в новосозданном окружении scrapingEnv, вы можете установить и использовать, например, библиотеку BeautifulSoup:
(scrapingEnv)ryan$ pip install beautifulsoup4
(scrapingEnv)ryan$ python
>>> from bs4 import BeautifulSoupЧтобы выйти из окружения, используйте команду deactivate. После этого вы больше не сможете иметь доступ к библиотекам, установленным внутри виртуального окружения:
(scrapingEnv)ryan$ deactivate
ryan$ python
>>> from bs4 import BeautifulSoup
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: No module named 'bs4'Отдельное использование виртуальных окружений для каждого проекта также упрощает передачу всего проекта другому человеку. Вы можете просто заархивировать папку с окружением и отправить её. Если у получателя установлена такая же версия Python, ваш код будет работать без необходимости устанавливать какие-либо библиотеки.
Продвинутый парсинг HTML
Когда Микеланджело спросили, как ему удалось создать такой шедевр, как его Давид, он знаменито ответил: «Это просто. Ты просто отсекаешь куски камня, которые не похожи на Давида».
Хотя веб-скрапинг мало чем напоминает скульптуру из мрамора в большинстве других аспектов, вам нужно принять аналогичное отношение, когда дело доходит до извлечения информации, которую вы ищете, из сложных веб-страниц. В этом разделе мы рассмотрим различные техники «отсекания» ненужного контента, пока не доберёмся до информации, которая вам нужна. Сложные HTML-страницы могут пугать на первый взгляд, но просто продолжайте «отсекать»!
Ещё одна порция BeautifulSoup
В предыдущем разделе, вы уже немного познакомились с установкой и использованием BeautifulSoup, а также с выборкой объектов по одному. В этом разделе мы обсудим поиск тегов по атрибутам, работу со списками тегов и навигацию по деревьям разбора.
Практически каждый сайт, с которым вы сталкиваетесь, содержит таблицы стилей (стили CSS). Эти таблицы стилей созданы для того, чтобы веб-браузеры могли преобразовать HTML в красочные и эстетически приятные дизайны для людей. Вы можете думать об этом слое стилей как, по меньшей мере, о чём-то совершенно незначительном для веб-скраперов — но не спешите с выводами! CSS на самом деле огромное благо для веб-скраперов, потому что он требует дифференциации HTML-элементов для их стилизации.
CSS стимулирует веб-разработчиков добавлять теги к HTML-элементам, которые иначе могли бы остаться с одинаковой разметкой. Некоторые теги могут выглядеть так:
<span class="green"></span>Другие выглядят так:
<span class="red"></span>Веб-скраперы могут легко различить эти два тега на основе их класса; например, они могут использовать BeautifulSoup, чтобы выбрать весь красный текст, но ни один зелёный. Поскольку CSS опирается на эти идентифицирующие атрибуты для соответствующего стилизации сайтов, вы почти гарантированно найдёте, что эти атрибуты класса и идентификатора будут в изобилии на большинстве современных веб-сайтов.
Это знание можно использовать для эффективного веб-скрапинга: ищите уникальные идентификаторы или классы, чтобы точно находить нужные данные среди всего разнообразия контента на странице.
Давайте создадим пример веб-скрапера, который будет извлекать данные со страницы по адресу https://victor-komlev.ru/veb-skraping-parsing-dannyh/. На этой странице присутствует код на языках Python и HTML. Вы можете увидеть теги <code>, которые используют соответствующие CSS-классы, в следующем фрагменте исходного кода страницы:
<code class="language-markup"><h1>Hello World</h1></code>
<code class="language-python">print('Hello World')</code> Чтобы извлечь данные со всей страницы и создать объект BeautifulSoup, используйте программу, аналогичную той, что была использована ранее
from urllib.request import urlopen
from bs4 import BeautifulSoup
html = urlopen('https://victor-komlev.ru/veb-skraping-parsing-dannyh/')
bs = BeautifulSoup(html.read(), 'html.parser')Используя этот объект BeautifulSoup, вы можете применить функцию find_all для извлечения списка имен собственных, выбирая только текст внутри тегов <code class="language-python"></code> (функция find_all — это очень гибкая функция, которую вы будете часто использовать далее
nameList = bs.find_all('code', {'class': 'language-python'})
for name in nameList:
print(name.get_text())При запуске этот код должен вывести все примеры кода на Python в тексте в том порядке, в котором они появляются в статье. Как это работает? Ранее вы использовали bs.tagName для получения первого вхождения тега на странице. Теперь вы вызываете bs.find_all(tagName, tagAttributes) для получения списка всех тегов на странице, а не только первого.
После получения списка имен программа перебирает все имена в списке и выводит name.get_text(), чтобы отделить содержимое от тегов. Это позволяет читать данные чистыми и понятными для дальнейшей обработки.
Когда использовать get_text() и когда сохранять теги
Метод get_text() удаляет все теги из документа, с которым вы работаете, и возвращает строку в кодировке Unicode, содержащую только текст. Например, если вы работаете с большим блоком текста, который содержит множество гиперссылок, параграфов и других тегов, все они будут удалены, и у вас останется блок текста без тегов.
Помните, что найти то, что вам нужно, гораздо проще в объекте BeautifulSoup, чем в блоке текста. Вызывать get_text() следует всегда в последнюю очередь, непосредственно перед тем, как вы печатаете, сохраняете или манипулируете вашими итоговыми данными. В общем, вы должны стараться сохранять структуру тегов документа как можно дольше.
Пример использования в контексте веб-скрапинга
Рассмотрим пример, когда вы извлекаете данные с веб-страницы, которая содержит текст с различными тегами, такими как <a>, <p>, <div> и другие.
HTML-код веб-страницы:
<div>
<p>Добро пожаловать на наш <a href="https://victor-komlev.ru/veb-skraping-parsing-dannyh/">сайт</a>. Здесь вы найдете много полезной информации.</p>
<p>Вот <a href="/more-info">ещё текст</a> с информацией.</p>
</div>Сценарий скрапинга без использования get_text():
from urllib.request import urlopen
from bs4 import BeautifulSoup
url = 'https://victor-komlev.ru/veb-skraping-parsing-dannyh/'
html = urlopen(url)
bs = BeautifulSoup(html.read(), 'html.parser')
content = bs.find('div')
print(content)Этот код выводит:
<div>
<p>Добро пожаловать на наш <a href="https://victor-komlev.ru/veb-skraping-parsing-dannyh/">сайт</a>. Здесь вы найдете много полезной информации.</p>
<p>Вот <a href="/more-info">ещё текст</a> с информацией.</p>
</div>Сценарий скрапинга с использованием get_text():
print(content.get_text())Этот код выводит:
Добро пожаловать на наш сайт. Здесь вы найдете много полезной информации.
Вот ещё текст с информацией.Когда сохранять теги
Сохранять теги следует, когда:
- Вам нужно извлечь определённые атрибуты тегов: Например, если вы хотите получить URL-адреса всех ссылок на странице, вам нужно сохранить теги
<a>для доступа к атрибутуhref.links = bs.find_all('a') for link in links: print(link['href']) - Вы анализируете структуру документа: Если ваша задача включает анализ расположения текста в документе или извлечение данных, сгруппированных определённым образом (например, элементы в списках), сохранение тегов поможет вам понять и использовать эту структуру.
for p in bs.find_all('p'): print(p) - Вы изменяете или фильтруете HTML-контент перед дальнейшей обработкой: Иногда вам нужно изменить HTML (например, удалить некоторые теги) перед извлечением текста.
for script in bs(["script", "style"]): script.decompose() # Удаление тегов print(bs.get_text())
Когда использовать get_text()
Используйте get_text(), когда:
- Вам нужен чистый текст для анализа или отображения: Если конечным результатом вашего скрапинга является текст для анализа, отчётов или простого отображения пользователю без HTML-тегов.
- После обработки всех необходимых тегов: Если вы уже извлекли всю нужную информацию (например, URL-адреса, атрибуты тегов) и вам нужно получить оставшийся текст.
- Для упрощения и очистки финального вывода: Когда вы хотите устранить все теги перед сохранением данных или их дальнейшей обработкой.
Помните, что правильный выбор момента для использования get_text() или сохранения тегов сильно зависит от вашей конкретной задачи и структуры данных, с которыми вы работаете.
Использование методов find() и find_all() в BeautifulSoup
Методы find() и find_all() в BeautifulSoup — это две функции, которые вы, скорее всего, будете использовать чаще всего. С их помощью можно легко фильтровать HTML-страницы, чтобы найти списки желаемых тегов или один тег на основе их различных атрибутов.
Эти две функции очень похожи, как видно из их определений в документации BeautifulSoup:
find_all(tag, attrs, recursive, text, limit, **kwargs)find(tag, attrs, recursive, text, **kwargs)
В большинстве случаев, примерно 95% времени, вам нужно будет использовать только первые два аргумента: tag и attrs. Однако давайте рассмотрим все параметры более подробно.
Параметр tag
Этот параметр вы уже видели; вы можете передать строку с именем тега или даже список строк с именами тегов в Python. Например, следующий код возвращает список всех заголовочных тегов в документе:
.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'])Параметр attrs
В отличие от параметра tag, который может быть строкой или итерируемым объектом, параметр attrs должен быть словарём Python с атрибутами и значениями. Он сопоставляет теги, которые содержат любой из этих атрибутов. Например, следующая функция вернёт оба тега span с классами green и red в HTML-документе:
.find_all('span', {'class': ['green', 'red']})Параметр recursive
Этот параметр является булевым. Насколько глубоко вы хотите проникнуть в документ? Если recursive установлен в True, функция find_all ищет теги, соответствующие параметрам, в детях, детях детей и т.д. Если он False, она будет искать только среди тегов верхнего уровня в вашем документе. По умолчанию find_all работает рекурсивно (recursive установлен в True). В общем, это хорошая идея оставить это как есть, если только вы точно не знаете, что вам нужно делать, и производительность является вопросом.
Параметр text
Этот параметр необычен тем, что он сопоставляется с текстовым содержимым тегов, а не с свойствами самих тегов. Например, если вы хотите узнать, сколько раз «the prince» окружён тегами на примере страницы, вы могли бы заменить функцию .find_all() в предыдущем примере следующими строками:
nameList = bs.find_all(text='the prince')
print(len(nameList))Результат этого примера будет 7.
Параметр limit
Этот параметр, конечно, используется только в методе find_all; find эквивалентен вызову find_all с limit равным 1. Вы можете установить этот параметр, если вас интересует получение только первых x элементов со страницы. Имейте в виду, что это дает вам первые элементы на странице в порядке, в котором они встречаются в документе, а не обязательно первые, которые вы хотите.
Дополнительный параметр kwargs
Этот параметр позволяет передать любые дополнительные именованные аргументы, которые вы хотите использовать в методе. Любые дополнительные аргументы, которые find или find_all не распознают, будут использоваться как сопоставители атрибутов тегов. Например:
title = bs.find_all(id='title', class_='text')Код возвращает первый тег с словом «text» в атрибуте класса и «title» в атрибуте id. Обратите внимание, что по соглашению каждое значение для id должно использоваться только один раз на странице. Поэтому на практике строка вида этой может быть не особенно полезной и должна быть эквивалентна использованию функции find:
title = bs.find(id='title')Примеры использования
Давайте рассмотрим несколько практических примеров использования find и find_all в контексте веб-скрапинга.
Пример 1: Извлечение всех заголовков
headers = bs.find_all(['h1', 'h2', 'h3', 'h4', 'h5', 'h6'])
for header in headers:
print(header.get_text())Пример 2: Поиск элементов по классу
# Находит все теги span с классами 'green' или 'red'
spans = bs.find_all('span', {'class': ['green', 'red']})
for span in spans:
print(span.get_text())Пример 3: Ограничение поиска первыми N элементами
# Находит первые 5 тегов 'p' на странице
paragraphs = bs.find_all('p', limit=5)
for p in paragraphs:
print(p.get_text())Пример 4: Работа с текстовым содержимым
# Находит все элементы, содержащие текст "the prince"
prince_texts = bs.find_all(text='the prince')
print(f"Found {len(prince_texts)} occurrences.")Пример 5: Нерекурсивный поиск
# Ищет только среди тегов верхнего уровня
top_level_divs = bs.find_all('div', recursive=False)
for div in top_level_divs:
print(div)В Python слово
classявляется зарезервированным и не может быть использовано как имя переменной или аргумента.
Например, если вы попробуете выполнить следующий вызов, то получите синтаксическую ошибку из-за неправильного использования class:
bs.find_all(class='green')Поэтому, когда вы работаете с библиотекой BeautifulSoup и хотите найти элементы по классу, вам нужно использовать аргумент с именем _class вместо class. Вот как это делается правильно:
bs.find_all(_class='green')Это позволяет избежать конфликта с зарезервированными словами Python и корректно указать, что вы ищете элементы по значению атрибута класса.
Давайте разберём на простом примере. Если вы хотите найти все элементы с классом «green» в HTML-документе, вам нужно сделать следующее:
- Подключить необходимые библиотеки и создать объект BeautifulSoup. Например, если у вас есть HTML-код в переменной
html, вы можете сделать так:from bs4 import BeautifulSoup # предположим, у нас есть переменная html с HTML кодом soup = BeautifulSoup(html, 'html.parser') - Используйте метод
find_allс аргументом_classдля поиска всех элементов с классом «green»:green_elements = soup.find_all(_class='green') - Теперь переменная
green_elementsсодержит список всех элементов, у которых класс «green». Вы можете работать с этим списком, например, выводить содержимое этих элементов:for element in green_elements: print(element.text)
В библиотеке BeautifulSoup есть удобный способ искать теги, основываясь на их атрибутах и значениях атрибутов, который называется параметр attrs. Действительно, следующие две строки кода делают одно и то же:
bs.find(id='text')и
bs.find(attrs={'id': 'text'})Первый вариант записи короче и, возможно, удобнее в использовании для быстрых фильтраций, когда вам нужно найти теги по конкретному атрибуту. Однако, когда фильтры становятся более сложными или когда вам нужно передать в аргументы значения атрибутов в виде списка, может оказаться полезным использовать параметр attrs.
Например, если вы хотите найти все теги, у которых класс может быть равен «red», «blue» или «green», вы можете сделать это так:
bs.find(attrs={'class': ['red', 'blue', 'green']})Этот подход даёт вам больше гибкости, когда дело доходит до более сложных запросов. Вот как можно адаптировать эту информацию для понимания начинающими:
Пример использования параметра attrs
Допустим, у вас есть HTML-документ, и вам нужно найти все элементы, которые имеют класс «red», «blue» или «green». Вот как вы можете это сделать с помощью BeautifulSoup:
- Подключите необходимые библиотеки и создайте объект
BeautifulSoup. Если у вас есть переменнаяhtmlс HTML-кодом, вы можете сделать так:from bs4 import BeautifulSoup # предположим, у нас есть переменная html с HTML кодом soup = BeautifulSoup(html, 'html.parser') - Используйте метод
find_allс параметромattrs, указывая в нём словарь, где ключ — это название атрибута, а значение — список возможных значений этого атрибута:colorful_elements = soup.find_all(attrs={'class': ['red', 'blue', 'green']}) - Теперь переменная
colorful_elementsсодержит список всех элементов, у которых класс «red», «blue» или «green». Вы можете обработать этот список, например, вывести содержимое каждого элемента:for element in colorful_elements: print(element.text)
Почему удобно использовать attrs?
- Гибкость:
attrsпозволяет устанавливать сложные фильтры, включая поиск по нескольким атрибутам одновременно. - Список значений: Если нужно найти элементы, атрибут которых может иметь одно из нескольких значений,
attrsс листом значений — это идеальный выбор. - Читаемость: Когда фильтры становятся сложными, использование
attrsделает код более структурированным и понятным.
Объекты BeautifulSoup
В библиотеке BeautifulSoup существует четыре основных типа объектов, каждый из которых играет свою роль при работе с HTML-документами. Понимание этих объектов поможет вам лучше ориентироваться в процессе веб-скрапинга и более эффективно извлекать нужные данные.
Эти объекты являются основными в библиотеке и представляют собой весь HTML-документ. Примеры использования таких объектов вы уже видели в переменной bs:
from bs4 import BeautifulSoup
html_doc = "<html><head><title>Пример</title></head><body><p>Текст</p></body></html>"
soup = BeautifulSoup(html_doc, 'html.parser')В этом примере soup — это объект BeautifulSoup, который представляет весь HTML-документ.
Объекты Tag
Объекты Tag представляют HTML-теги в документе. Эти объекты можно получать списком или по одному, используя методы find и find_all или обращаясь к тегам напрямую через точку:
# Получение тега title
title_tag = soup.title
print(title_tag) # <title>Пример</title>
# Поиск всех тегов p
all_p_tags = soup.find_all('p')
print(all_p_tags) # [<p>Текст</p>]Объекты NavigableString
Объекты NavigableString используются для представления текста внутри тегов, а не самих тегов. Когда вам нужен именно текст, а не структура HTML, эти объекты приходят на помощь:
# Получение текста из тега title
title_text = title_tag.string
print(title_text) # ПримерЗдесь title_text является объектом NavigableString, который содержит текст «Пример», находящийся внутри тега <title>.
Объекты Comment
Объекты Comment предназначены для работы с HTML-комментариями. Эти объекты позволяют найти и обработать комментарии в HTML-коде:
from bs4 import Comment
html_doc = "<!--Это комментарий--><p>Текст</p>"
soup = BeautifulSoup(html_doc, 'html.parser')
comments = soup.find_all(string=lambda text: isinstance(text, Comment))
print(comments) # ['Это комментарий']В этом примере comments будет содержать текст комментария «Это комментарий», обнаруженного в HTML.
Заключение
Эти четыре типа объектов (BeautifulSoup, Tag, NavigableString, Comment) остаются основными в библиотеке BeautifulSoup с момента её релиза в 2004 году. Знание этих объектов позволяет глубже понять, как устроена работа с HTML-документами при помощи BeautifulSoup и как можно максимально эффективно извлекать нужные данные из веб-страниц.
Каждый из этих объектов имеет своё предназначение и область применения, и правильное использование этих объектов поможет вам создавать более надёжные и гибкие скрипты для веб-скрапинга.
Навигация по дереву в BeautifulSoup
При работе с веб-скрапингом важно не только уметь находить теги по именам и атрибутам с помощью функции find_all, но и уметь перемещаться по структуре HTML-документа, используя его древовидную структуру. Это особенно полезно, когда вам нужно найти теги на основе их расположения в документе.
Ранее вы уже видели, как перемещаться по дереву BeautifulSoup в одном направлении:
bs.tag.subTag.anotherSubTagТеперь давайте рассмотрим, как перемещаться по дереву вверх, вбок и по диагонали.
Пример страницы для скрапинга
В качестве примера возьмем страницу интернет-магазина на http://www.pythonscraping.com/pages/page3.html.

Ниже представлена упрощенная структура HTML этой страницы в виде дерева (некоторые теги опущены для краткости):
HTML
└── body
└── div.wrapper
├── h1
├── div.content
│ └── table#giftList
│ ├── tr
│ │ ├── th
│ │ ├── th
│ │ ├── th
│ │ └── th
│ ├── tr.gift#gift1
│ │ ├── td
│ │ ├── td
│ │ │ └── span.excitingNote
│ │ ├── td
│ │ └── td
│ │ └── img
│ └── ...другие строки таблицы...
└── div.footerВниз по дереву
Вы можете перемещаться по дереву вниз, используя названия тегов:
from bs4 import BeautifulSoup
# Предположим, что `html_doc` - это HTML документ выше
soup = BeautifulSoup(html_doc, 'html.parser')
# Доступ к первому тегу <body>
body = soup.body
# Доступ к первому тегу <div> с классом "wrapper"
wrapper = body.div
# Доступ к <h1> внутри <div class="wrapper">
h1 = wrapper.h1Вверх по дереву
Используйте .parent для перемещения к родительскому тегу:
# От <span class="excitingNote"> вверх к родительскому <td>
span = soup.find('span', {'class': 'excitingNote'})
td = span.parentВбок по дереву
Используйте .next_sibling и .previous_sibling для доступа к соседним тегам:
# Найти следующий <td> после первого <td> в <tr class="gift">
first_td = soup.find('tr', {'class': 'gift'}).td
second_td = first_td.next_sibling.next_sibling # Пропускаем текстовые узлы (переносы строк)По диагонали
Для диагонального перемещения воспользуйтесь комбинацией перемещений вверх и вбок:
# От <span class="excitingNote"> вверх к <td>, затем к следующему <td>
next_td = span.parent.next_sibling.next_siblingРезюме
Навигация по дереву в BeautifulSoup позволяет вам точно находить элементы на странице, основываясь на их взаимном расположении. Такой подход чрезвычайно полезен, когда структура документа сложна или когда необходимо извлечь данные, расположенные в определённом порядке.
Используйте эти методы, чтобы извлекать данные более гибко и точно, особенно когда простых селекторов и методов find_all недостаточно для описания вашего запроса. Эти методы делают ваш скрапинг мощнее и адаптивнее к различным структурам HTML.
Работа с детьми и потомками
В работе с веб-скрапингом и библиотекой BeautifulSoup важно понимать разницу между детьми (children) и потомками (descendants) элемента. Это понятие аналогично семейному древу: дети элемента находятся непосредственно под ним, на один уровень вложенности, в то время как потомки могут находиться на любом уровне ниже.
Дети (Children)
Детьми элемента считаются те теги, которые являются его непосредственными потомками. Например, в HTML-структуре:
<table id="giftList">
<tr><th>Header 1</th><th>Header 2</th></tr>
<tr><td>Row 1, Cell 1</td><td>Row 1, Cell 2</td></tr>
<tr><td>Row 2, Cell 1</td><td>Row 2, Cell 2</td></tr>
</table>Теги <tr> являются детьми <table>, а <th> и <td> являются детьми <tr>.
Чтобы выбрать только детей в BeautifulSoup, используется атрибут .children:
from bs4 import BeautifulSoup
from urllib.request import urlopen
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html, 'html.parser')
# Выбираем <table> по ID 'giftList' и перебираем его детей
for child in bs.find('table', {'id': 'giftList'}).children:
print(child)Этот код выведет все дочерние элементы <tr> таблицы giftList, включая заголовок таблицы.
Потомки (Descendants)
Потомки элемента — это все теги, которые находятся внутри данного элемента на любом уровне вложенности. Так, <th>, <td>, <img>, и <span> являются потомками <table> в предыдущем примере.
Для работы с потомками используются методы .find() и .find_all(), которые по умолчанию работают с потомками:
# Находим все теги <img>, которые являются потомками первого <div> в документе
for img in bs.find('div').find_all('img'):
print(img)Этот код найдёт все теги <img>, которые находятся внутри первого тега <div>.
Различия между Children и Descendants
Если вы хотите увидеть разницу между .children и .descendants, попробуйте следующий код:
# Используем .descendants
for descendant in bs.find('table', {'id': 'giftList'}).descendants:
print(descendant)Этот код выведет абсолютно все теги, тексты и другие объекты, которые находятся внутри <table id="giftList">, включая теги <th>, <td>, текст внутри ячеек, теги <img> и <span>.
Практическое задание
Если вам нужно извлечь только данные из строк таблицы, игнорируя заголовки, можно использовать .children следующим образом:
# Пропускаем первый ребёнок <tr>, так как это заголовки
for sibling in bs.find('table', {'id': 'giftList'}).tr.next_siblings:
print(sibling)Этот код пропустит первый <tr> (заголовки) и выведет только строки с данными.
Заключение
Понимание разницы между детьми и потомками в BeautifulSoup поможет вам создавать более точные и эффективные скрипты для веб-скрапинга. Используйте .children когда вам нужны непосредственные потомки, и .descendants (или .find_all) когда вам нужны все вложенные теги на любом уровне. Это сделает ваш код более понятным и предсказуемым.
Работа со смежными элементами (сиблингами) в BeautifulSoup
При анализе HTML-таблиц и других последовательных структур данных важно уметь перемещаться не только вверх и вниз по дереву документа, но и вбок — между смежными элементами, или «сиблингами». BeautifulSoup предоставляет удобные функции для работы со смежными элементами, такие как next_siblings и previous_siblings.
Использование next_siblings
Функция next_siblings позволяет перебрать всех смежных элементов, которые идут после указанного элемента, но не включает сам элемент. Это особенно полезно для извлечения данных из таблиц, где есть строка заголовков, за которой следуют строки данных.
Рассмотрим следующий пример:
from urllib.request import urlopen
from bs4 import BeautifulSoup
# Открываем URL и создаем объект BeautifulSoup
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html, 'html.parser')
# Находим первую строку таблицы (заголовки) и перебираем всех ее смежных элементов
for sibling in bs.find('table', {'id': 'giftList'}).tr.next_siblings:
print(sibling)Как это работает и почему пропускается заголовок?
- Здесь
bs.find('table', {'id': 'giftList'}).trнаходит первую строку<tr>таблицы, которая является строкой заголовков. .next_siblingsперебирает все следующие строки<tr>, но не включает саму строку заголовков, потому что объекты не могут быть сиблингами сами себе.
Таким образом, код выводит все строки продуктов из таблицы товаров, исключая первую строку с заголовками.
Совет: Будьте конкретны в выборке
Хотя можно использовать bs.table.tr или bs.tr для выбора первой строки таблицы, лучше быть максимально точным:
bs.find('table', {'id': 'giftList'}).trЭто делает ваш код более надежным и устойчивым к изменениям в разметке страницы. Даже если на странице одна таблица, лучше использовать все доступные атрибуты для выборки.
Использование previous_siblings и previous_sibling
previous_siblings: Позволяет перебирать всех смежных элементов, которые идут до указанного элемента. Это может быть полезно, если вы можете легко выбрать последний тег в списке сиблингов и хотите получить все предыдущие теги.previous_siblingиnext_sibling: Возвращают один смежный элемент (не список), который находится непосредственно до или после указанного элемента. Это полезно, когда вам нужен только один конкретный смежный элемент.
Пример previous_sibling и next_sibling
# Находим первый <td> в первой строке данных и получаем следующий <td>
first_td = bs.find('table', {'id': 'giftList'}).tr.next_siblings.next_sibling
print(first_td)
# Находим последний <td> в таблице и получаем предыдущий <td>
last_td = bs.find('table', {'id': 'giftList'}).tr.previous_siblings.previous_sibling
print(last_td)Работа с родительскими элементами в BeautifulSoup
При веб-скрапинге часто приходится извлекать данные, идя вглубь документа — от родительских элементов к дочерним или смежным. Однако иногда возникает необходимость найти родительский элемент для определённого тега, что также может быть важно для успешного извлечения информации.
Зачем нужно найти родителя?
В некоторых случаях данные, которые нужно извлечь, расположены не в самом элементе, а в его родителе или рядом с ним. Тогда приходят на помощь функции .parent и .parents.
Пример: нахождение цены продукта
Рассмотрим задачу, где нужно найти цену товара, представленного изображением на странице. В структуре HTML цена и изображение товара могут быть расположены в соседних ячейках таблицы.
Вот HTML-структура, с которой мы работаем:
<tr>
<td>...</td>
<td>...</td>
<td>$15.00</td>
<td>
<img src="../img/gifts/img1.jpg">
</td>
</tr>Цель
Нужно определить цену товара ($15.00), изображение которого находится в теге <img src="../img/gifts/img1.jpg">.
Решение
- Найти
<img>: Сначала найдем тег<img>, который содержит атрибутsrcс определённым путем. - Перейти к Родителю
<img>: Это тег<td>, содержащий изображение. - Найти Соседний Тег
<td>: Перейдем к предыдущему смежному тегу<td>, который содержит цену. - Извлечь Текст: Получим текст этого тега, который является ценой товара.
Код
from urllib.request import urlopen
from bs4 import BeautifulSoup
# Загружаем HTML-документ
html = urlopen('http://www.pythonscraping.com/pages/page3.html')
bs = BeautifulSoup(html, 'html.parser')
# Находим <img> с определенным src и переходим к родительскому <td>
# Затем переходим к предыдущему смежному <td> и извлекаем его текст
price = bs.find('img', {'src': '../img/gifts/img1.jpg'}).parent.previous_sibling.get_text()
print(price)Объяснение
bs.find('img', {'src': '../img/gifts/img1.jpg'}): Находим тег<img>с атрибутомsrc, равным"../img/gifts/img1.jpg"..parent: Переходим к родительскому элементу этого<img>, это<td>, в котором находится изображение..previous_sibling: От этого<td>переходим к предыдущему смежному<td>, содержащему цену..get_text(): Извлекаем текст из этого<td>, который является ценой$15.00.
Визуализация Процесса
<tr>
<td>...</td>
<td>...</td>
<td>$15.00</td> <--- Этот текст нам нужен
<td>
<img src="../img/gifts/img1.jpg"> <--- Начинаем отсюда
</td>
</tr>Дополнительные советы
- Будьте Внимательны: Перед использованием
.parentи.previous_siblingубедитесь, что элементы существуют, чтобы избежать ошибок. - Используйте
.parents: Если нужно подняться выше по дереву,.parentsпозволяет перебирать всех предков элемента, пока не найдете нужный.
Индивидуальное и групповое обучение «Аналитик данных»
Если вы хотите стать экспертом в аналитике, могу помочь. Запишитесь на мой курс «Аналитик данных» и начните свой путь в мир ИТ уже сегодня!
Контакты
Для получения дополнительной информации и записи на курсы свяжитесь со мной:
Телеграм: https://t.me/Vvkomlev
Email: victor.komlev@mail.ru
Объясняю сложное простыми словами. Даже если вы никогда не работали с ИТ и далеки от программирования, теперь у вас точно все получится! Проверено десятками примеров моих учеников.
Гибкий график обучения. Я предлагаю занятия в мини-группах и индивидуально, что позволяет каждому заниматься в удобном темпе. Вы можете совмещать обучение с работой или учебой.
Практическая направленность. 80%: практики, 20% теории. У меня множество авторских заданий, которые фокусируются на практике. Вы не просто изучаете теорию, а сразу применяете знания в реальных проектах и задачах.
Разнообразие учебных материалов: Теория представлена в виде текстовых уроков с примерами и видео, что делает обучение максимально эффективным и удобным.
Понимаю, что обучение информационным технологиям может быть сложным, особенно для новичков. Моя цель – сделать этот процесс максимально простым и увлекательным. У меня персонализированный подход к каждому ученику. Максимальный фокус внимания на ваши потребности и уровень подготовки.