До сих пор данные, с которыми вы работали, в основном были в виде чисел или подсчитываемых значений. В большинстве случаев вы просто сохраняли данные без проведения какого-либо анализа после факта. В этой главе предпринимается попытка рассмотреть сложную тему английского языка.
Как Google узнает, что вы ищете, когда вводите «милый котенок» в его поисковой запрос? Благодаря тексту, который окружает изображения милых котят. Как YouTube знает, какой определенный скетч Монти Пайтона показать, когда вы вводите «мертвый попугай» в его строку поиска? Благодаря заголовку и описанию, сопровождающему каждое загруженное видео.
Фактически, даже ввод терминов типа «мертвая птица монти пайтон» сразу выводит тот же самый скетч «Мертвый Попугай», хотя сама страница не содержит никаких упоминаний о словах «мертвая» или «птица». Google знает, что «хот дог» — это еда, и что «кипящий щенок» — совершенно другая вещь. Как? Всё это статистика!
Хотя вам может показаться, что анализ текста не имеет ничего общего с вашим проектом, понимание концепций, лежащих в его основе, может быть крайне полезным для всех видов машинного обучения, а также для более общей способности моделировать реальные проблемы в вероятностных и алгоритмических терминах.
Например, музыкальный сервис Shazam может определить аудио как содержащее определенную запись песни, даже если это аудио содержит фоновый шум или искажение. Google работает над автоматической подписью изображений, основанной только на самом изображении.
Сравнивая известные изображения, скажем, хот догов с другими изображениями хот догов, поисковик постепенно учится, как выглядит хот дог, и наблюдает эти закономерности в дополнительных изображениях, которые ему показывают.
Слияние и обобщение данных
В разделе «Очистка данных» вы изучили разбиение текстового содержимого на n-граммы, или наборы фраз из n слов. На базовом уровне это можно использовать для определения наиболее часто используемых наборов слов и фраз в разделе текста. Кроме того, это можно использовать для создания естественно звучащих сводок данных, возвращаясь к исходному тексту и извлекая предложения вокруг некоторых из этих наиболее популярных фраз.
Одним из образцов текста, который вы будете использовать для этого, является вступительное слово девятого президента Соединенных Штатов Уильяма Генри Харрисона. Президентство Харрисона установило два рекорда в истории этого офиса: один — за самое длинное вступительное слово и другой — за самое короткое время пребывания в офисе, 32 дня.
С небольшим изменением n-граммы, использованной для поиска кода в «Очистке данных», вы можете создать код, который ищет наборы 2-грамм и возвращает объект Counter со всеми 2-граммами:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import re
import string
from collections import Counter
def cleanSentence(sentence):
sentence = sentence.split(' ')
sentence = [word.strip(string.punctuation+string.whitespace) for word in sentence]
sentence = [word for word in sentence if len(word) > 1 or (word.lower() == 'a' or word.lower() == 'i')]
return sentence
def cleanInput(content):
content = content.upper()
content = re.sub('\n', ' ', content)
content = bytes(content, "UTF-8")
content = content.decode("ascii", "ignore")
sentences = content.split('. ')
return [cleanSentence(sentence) for sentence in sentences]
def getNgramsFromSentence(content, n):
output = []
for i in range(len(content)-n+1):
output.append(content[i:i+n])
return output
def getNgrams(content, n):
content = cleanInput(content)
ngrams = Counter()
ngrams_list = []
for sentence in content:
newNgrams = [' '.join(ngram) for ngram in getNgramsFromSentence(sentence, 2)]
ngrams_list.extend(newNgrams)
ngrams.update(newNgrams)
return(ngrams)
content = str(urlopen('http://pythonscraping.com/files/inaugurationSpeech.txt').read(), 'utf-8')
ngrams = getNgrams(content, 2)
print(ngrams)
Вывод содержит, среди прочего:
Counter({'OF THE': 213, 'IN THE': 65, 'TO THE': 61, 'BY THE': 41,
'THE CONSTITUTION': 34, 'OF OUR': 29, 'TO BE': 26, 'THE PEOPLE': 24,
'FROM THE': 24, 'THAT THE': 23,...
Из этих 2-грамм «конституция» кажется вполне популярной темой в выступлении, но «of the», «in the» и «to the» не кажутся особенно заметными. Как можно автоматически избавиться от нежелательных слов единым способом?
К счастью, есть люди, которые тщательно изучают различия между «интересными» и «незначимыми» словами, и их работа может помочь нам в этом. Марк Дэвис, профессор лингвистики в Бригам Янгском университете, ведет «Корпус современного американского английского языка«, коллекцию из более чем 450 миллионов слов из последних десятилетий популярных американских публикаций.
Список 5 000 наиболее часто встречающихся слов доступен бесплатно, и, к счастью, этого более чем достаточно для того, чтобы выступить в качестве базового фильтра и отсеять наиболее общие 2-граммы. Даже только первые 100 слов значительно улучшают результаты при добавлении функции isCommon:
def isCommon(ngram):
commonWords = ['THE', 'BE', 'AND', 'OF', 'A', 'IN', 'TO', 'HAVE', 'IT', 'I',
'THAT', 'FOR', 'YOU', 'HE', 'WITH', 'ON', 'DO', 'SAY', 'THIS', 'THEY',
'IS', 'AN', 'AT', 'BUT', 'WE', 'HIS', 'FROM', 'THAT', 'NOT', 'BY',
'SHE', 'OR', 'AS', 'WHAT', 'GO', 'THEIR', 'CAN', 'WHO', 'GET', 'IF',
'WOULD', 'HER', 'ALL', 'MY', 'MAKE', 'ABOUT', 'KNOW', 'WILL', 'AS',
'UP', 'ONE', 'TIME', 'HAS', 'BEEN', 'THERE', 'YEAR', 'SO', 'THINK',
'WHEN', 'WHICH', 'THEM', 'SOME', 'ME', 'PEOPLE', 'TAKE', 'OUT', 'INTO',
'JUST', 'SEE', 'HIM', 'YOUR', 'COME', 'COULD', 'NOW', 'THAN', 'LIKE',
'OTHER', 'HOW', 'THEN', 'ITS', 'OUR', 'TWO', 'MORE', 'THESE', 'WANT',
'WAY', 'LOOK', 'FIRST', 'ALSO', 'NEW', 'BECAUSE', 'DAY', 'MORE', 'USE',
'NO', 'MAN', 'FIND', 'HERE', 'THING', 'GIVE', 'MANY', 'WELL']
for word in ngram:
if word in commonWords:
return True
return False
Код производит следующие 2-граммы, которые были найдены более двух раз в тексте:
Counter({'UNITED STATES': 10, 'EXECUTIVE DEPARTMENT': 4,
'GENERAL GOVERNMENT': 4, 'CALLED UPON': 3, 'CHIEF MAGISTRATE': 3,
'LEGISLATIVE BODY': 3, 'SAME CAUSES': 3, 'GOVERNMENT SHOULD': 3,
'WHOLE COUNTRY': 3,...
Две первые позиции в списке — «Соединенные Штаты» и «исполнительное управление», что можно ожидать от вступительного слова президента.
Важно отметить, что вы используете список общих слов относительно современного времени для фильтрации результатов, что может быть не совсем уместно, учитывая, что текст был написан в 1841 году. Однако, поскольку вы используете только первые 100 или около того слов в списке — которые, как можно предположить, более стабильны с течением времени, чем, скажем, последние 100 слов — и получаете удовлетворительные результаты, вы вероятно можете сэкономить себе усилия по поиску или созданию списка наиболее распространенных слов из 1841 года (хотя такое усилие может быть интересным).
Теперь, когда из текста были извлечены некоторые ключевые темы, как это помогает вам писать текстовые резюме? Один из способов — найти первое предложение, содержащее каждый «популярный» n-грамм, с теорией, что первый пример даст удовлетворительный обзор содержания текста. Первые пять наиболее популярных 2-грамм дают следующие моменты:
- Конституция Соединенных Штатов — это инструмент, содержащий данную власть различным подразделениям, составляющим правительство.
- Таков был исполнительный орган, созданный Конституцией.
- Генеральное правительство не вмешивалось в резервированные права Штатов.
- Призванный из уединения, которое я считал, что будет продолжаться до конца моей жизни, чтобы занять должность главы исполнительной власти этой великой и свободной нации, я обращаюсь к вам, граждане, чтобы принять клятвы, которые предписывает конституция как необходимую квалификацию для выполнения своих обязанностей; и в соответствии с обычаем, существующим с момента создания нашего правительства, и тем, что я считаю вашими ожиданиями, я приступаю к представлению краткого изложения принципов, которые будут направлять меня в исполнении обязанностей, которые мне предстоит выполнить.
- Прессы, необходимые правительству, никогда не должны использоваться для «оправдания виновных или украшения преступления».
Конечно, это может не быть опубликовано в «Конспектах по Cliff» в ближайшее время, но учитывая, что оригинальный документ состоит из 217 предложений, и четвертое предложение («Призванный из уединения…») довольно хорошо сжимает основную тему, это не так уж плохо для первого прохода.
При более длинных блоках текста или более разнообразных текстах может иметь смысл использовать 3-граммы или даже 4-граммы при извлечении «самых важных» предложений из текста. В данном случае только один 3-грамм используется несколько раз, и это «исключительная металлическая валюта» — вряд ли определяющая фраза для вступительной речи президента. При более длинных отрывках текста использование 3-грамм может быть уместным.
Другой подход — искать предложения, содержащие самые популярные n-граммы. Они, конечно, склонны быть более длинными предложениями, поэтому если это станет проблемой, можно искать предложения с самым высоким процентом слов, которые являются популярными n-граммами, или создать свою собственную метрику оценки, комбинируя несколько техник.
Модели Маркова
Вы, возможно, слышали о генераторах текста на основе модели Маркова. Они стали популярными для развлекательных целей, как в приложении «Это может быть мой следующий твит!», а также используются для создания реалистичных спам-писем, чтобы обмануть системы обнаружения.
Все эти генераторы текста основаны на модели Маркова, которая часто используется для анализа больших наборов случайных событий, где одно дискретное событие следует за другим дискретным событием с определенной вероятностью. Например, вы можете построить модель Маркова погодной системы, как показано на рисунке.
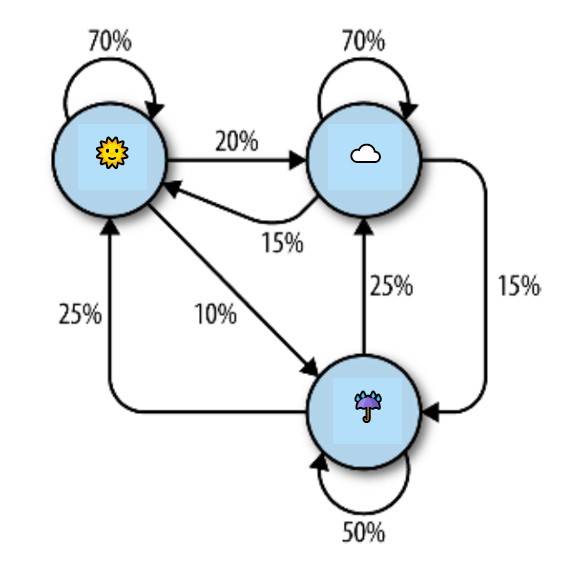
На этом рисунке каждый солнечный день имеет 70% вероятность, что следующий день также будет солнечным, с вероятностью 20% следующий день будет облачным и всего 10% вероятностью дождя. Если день дождливый, то существует 50% вероятность дождя на следующий день, 25% вероятность солнца и 25% вероятность облаков. Вы можете заметить несколько свойств в этой модели Маркова:
- Все проценты, ведущие от любого узла, должны составлять ровно 100%. Независимо от того, насколько сложна система, всегда должна быть вероятность в 100%, что она может перейти куда-то еще на следующем шаге.
- Хотя существует всего три возможности для погоды в любое данное время, вы можете использовать эту модель для создания бесконечного списка состояний погоды.
- Только состояние текущего узла, на котором вы находитесь, влияет на то, куда вы пойдете дальше. Если вы находитесь на солнечном узле, не имеет значения, были ли предыдущие 100 дней солнечными или дождливыми — вероятность солнца на следующий день точно такая же: 70%.
- Некоторые узлы могут быть труднее достичь, чем другие. Математика за этим достаточно сложная, но довольно легко понять, что «дождливый» (с менее чем «100%» стрелок, указывающих на него) является намного менее вероятным состоянием в этой системе в любой момент времени, чем «солнечный» или «облачный».
Очевидно, что это простая система, и модели Маркова могут быть произвольно большими. Алгоритм ранжирования страниц Google основан частично на модели Маркова, где веб-сайты представлены как узлы, а входящие/исходящие ссылки представлены как связи между узлами. «Вероятность» попадания на определенный узел представляет собой относительную популярность сайта. Иными словами, если бы наша погодная система представляла собой крайне маленький интернет, то «дождливый» имел бы низкий ранг страницы, а «облачный» — высокий ранг страницы.
С учетом всего этого, вернемся к более конкретному примеру: анализу и написанию текста. Снова используя речь о вступлении Уильяма Генри Харрисона, проанализированную в предыдущем примере, вы можете написать следующий код, который генерирует произвольно длинные цепи Маркова (с длиной цепи, установленной на 100), основываясь на структуре его текста:
from urllib.request import urlopen
from random import randint
def wordListSum(wordList):
sum = 0
for word, value in wordList.items():
sum += value
return sum
def retrieveRandomWord(wordList):
randIndex = randint(1, wordListSum(wordList))
for word, value in wordList.items():
randIndex -= value
if randIndex <= 0:
return word
def buildWordDict(text):
# Удаляем переводы строк и кавычки
text = text.replace('\n', ' ')
text = text.replace('"', '')
# Убеждаемся, что знаки пунктуации обрабатываются как отдельные "слова",
# чтобы они были включены в цепь Маркова
punctuation = [',', '.', ';', ':']
for symbol in punctuation:
text = text.replace(symbol, ' {} '.format(symbol))
words = text.split(' ')
# Фильтруем пустые слова
words = [word for word in words if word != '']
wordDict = {}
for i in range(1, len(words)):
if words[i-1] not in wordDict:
# Создаем новый словарь для этого слова
wordDict[words[i-1]] = {}
if words[i] not in wordDict[words[i-1]]:
wordDict[words[i-1]][words[i]] = 0
wordDict[words[i-1]][words[i]] += 1
return wordDict
text = str(urlopen('http://pythonscraping.com/files/inaugurationSpeech.txt').read(), 'utf-8')
wordDict = buildWordDict(text)
# Генерируем цепь Маркова длиной 100
length = 100
chain = ['I']
for i in range(0, length):
newWord = retrieveRandomWord(wordDict[chain[-1]])
chain.append(newWord)
print(' '.join(chain))
Результат этого кода меняется каждый раз при его выполнении, но вот пример нелепого текста, который он создает:
"Я искренне верю в Главного магистрата, чтобы сделать все необходимые жертвы и угнетение средств, которые могли возникнуть у меня в распоряжении демократических требований к ним, утешительно было бы лучшей политической властью в горячем приветствии каждого другого дополнения законодательства, по интересам, которые нарушают это Правительство, сравните наших аборигенных соседей с народом их осуществления. Последний также подвержен максиме Конституции, не слишком много зла, споры оставили, чтобы предать. Максима, которая иногда может быть беспристрастной и предотвратить принятие или"Итак, что происходит в этом коде?
Функция buildWordDict принимает строку текста, которая была получена из интернета. Затем она производит некоторую очистку и форматирование, удаляя кавычки и ставя пробелы вокруг других знаков пунктуации, чтобы они эффективно рассматривались как отдельные слова. После этого она создает двумерный словарь — словарь словарей — который имеет следующую форму:
{слово_а :
{слово_б : 2, слово_в : 1, слово_д : 1},
слово_е : {слово_б : 5, слово_д : 2},…}
В этом примере словаря «слово_а» было найдено четыре раза, два экземпляра из которых были за ним последовательными «слово_б», один экземпляр был за ним «слово_в», и один экземпляр был за ним «слово_д». «Слово_е» было зафиксировано семь раз, пять раз за «слово_б» и дважды за «слово_д».
Если бы мы нарисовали модель узла этого результата, то узел, представляющий слово_а, имел бы 50% стрелок, указывающих на «слово_б» (которое следовало за ним два из четырех раз), 25% стрелок, указывающих на «слово_в» и 25% стрелок, указывающих на «слово_д».
После того как этот словарь создан, его можно использовать в качестве таблицы поиска, чтобы увидеть, куда идти дальше, независимо от того, на каком слове в тексте вы находитесь. Используя пример словаря словарей, вы можете в данный момент находиться на «слове_е», что означает, что вы передадите словарь {слово_б : 5, слово_д: 2} функции retrieveRandomWord. Эта функция, в свою очередь, выбирает случайное слово из словаря, взвешенное по количеству его вхождений.
Начиная с случайного стартового слова (в этом случае всегда присутствует «Я»), вы можете легко пройти по цепи Маркова, генерируя столько слов, сколько захотите.
Эти цепи Маркова обычно улучшаются в своей «реалистичности», по мере того, как собирается больше текста, особенно из источников с похожими стилями письма. Хотя в этом примере использовались 2-граммы для создания цепи (где предыдущее слово предсказывает следующее), можно использовать 3-граммы или n-граммы более высокого порядка, где два или более слов предсказывают следующее слово. Хотя это развлекательно и отлично используется для мегабайтов текста, которые вы могли накопить во время сканирования веб-страниц, приложения, подобные этим, могут затруднить видение практической стороны цепей Маркова.
Как упоминалось ранее в этом разделе, цепи Маркова моделируют, как веб-сайты связаны друг с другом. Большие коллекции этих ссылок в виде указателей могут формировать веб-подобные графики, которые полезны для хранения, отслеживания и анализа. Таким образом, цепи Маркова являются основой как для мышления о сканировании веб-страниц, так и для того, как ваш сканер веб-страниц может думать.
6 степеней Википедии. Заключение
В заключении раздела про скрейперы, вы создали скрейпер, который собирает ссылки с одной статьи Википедии на следующую, начиная с статьи о Кевине Бэйконе, а в разделе «Базы данных» сохраняете эти ссылки в базе данных. Зачем я это снова упоминаю? Потому что оказывается, проблема выбора пути ссылок, который начинается на одной странице и заканчивается на целевой странице (т.е. нахождение цепочки страниц между https://en.wikipedia.org/wiki/Kevin_Bacon и https://en.wikipedia.org/wiki/Eric_Idle), то же самое, что и поиск цепи Маркова, где и первое слово, и последнее слово определены.
Эти типы проблем являются проблемами направленных графов, где A → B не обязательно означает, что B → A. Слово «футбол» может часто следовать за словом «игрок», но вы обнаружите, что слово «игрок» намного реже следует за словом «футбол». Хотя статья о Кевине Бэйконе на Википедии ссылается на статью о его родном городе, Филадельфии, статья о Филадельфии не отвечает на это, не содержа ссылку обратно на него.
В отличие от этого, изначальная игра «Шесть степеней от Кевина Бэйкона» представляет собой проблему ненаправленного графа. Если Кевин Бэйкон снялся в фильме «Линии жизни» с Джулией Робертс, то Джулия Робертс обязательно снялась в этом фильме с Кевином Бэйконом, поэтому отношение идет в обе стороны (оно не имеет «направления»). Проблемы ненаправленных графов обычно встречаются реже в информатике, чем направленные графовые проблемы, и обе они вычислительно сложны для решения.
Хотя над такими проблемами было проведено много работы и существует множество их вариаций, одним из лучших и наиболее распространенных способов найти кратчайшие пути в направленном графе — и, таким образом, найти пути между статьей Википедии о Кевине Бэйконе и всеми другими статьями Википедии — является поиск в ширину.
Поиск в ширину выполняется сначала путем поиска всех ссылок, которые напрямую связаны с начальной страницей. Если эти ссылки не содержат целевую страницу (страницу, которую вы ищете), то второй уровень ссылок — страницы, на которые ссылается страница, на которую ссылается начальная страница — ищется. Этот процесс продолжается до тех пор, пока не будет достигнут предел глубины (в данном случае 6) или не будет найдена целевая страница.
Полное решение поиска в ширину с использованием таблицы ссылок, описанное в разделе «Базы данных», выглядит следующим образом:
import pymysql
conn = pymysql.connect(host='127.0.0.1', unix_socket='/tmp/mysql.sock',
user='', passwd='', db='mysql', charset='utf8')
cur = conn.cursor()
cur.execute('USE wikipedia')
def getUrl(pageId):
cur.execute('SELECT url FROM pages WHERE id = %s', (int(pageId)))
return cur.fetchone()[0]
def getLinks(fromPageId):
cur.execute('SELECT toPageId FROM links WHERE fromPageId = %s',
(int(fromPageId)))
if cur.rowcount == 0:
return []
return [x[0] for x in cur.fetchall()]
def searchBreadth(targetPageId, paths=[[1]]):
newPaths = []
for path in paths:
links = getLinks(path[-1])
for link in links:
if link == targetPageId:
return path + [link]
else:
newPaths.append(path + [link])
return searchBreadth(targetPageId, newPaths)
nodes = getLinks(1)
targetPageId = 28624
pageIds = searchBreadth(targetPageId)
for pageId in pageIds:
print(getUrl(pageId))
Функция getUrl — вспомогательная функция, которая извлекает URL из базы данных по идентификатору страницы. Аналогично, getLinks принимает fromPageId, представляющий целочисленный идентификатор текущей страницы, и извлекает список всех целочисленных идентификаторов страниц, на которые она ссылается.
Основная функция searchBreadth рекурсивно строит список всех возможных путей от страницы поиска и останавливается, когда находит путь, достигший целевой страницы:
- Она начинается с единственного пути, [1], представляющего путь, в котором пользователь остается на целевой странице с идентификатором 1 (Кевин Бэкон) и не следует по ссылкам.
- Для каждого пути в списке путей (на первом проходе есть только один путь, поэтому этот шаг краток), она получает все ссылки, исходящие из страницы, представленной последней страницей в пути.
- Для каждой из этих исходящих ссылок проверяется, совпадает ли она с targetPageId. Если совпадение есть, этот путь возвращается.
- Если совпадения нет, новый путь добавляется в новый список (теперь более длинный) путей, состоящий из старого пути + новой исходящей ссылки страницы.
- Если targetPageId вообще не найден на этом уровне, происходит рекурсия и searchBreadth вызывается с тем же targetPageId и новым, более длинным списком путей.
После нахождения списка идентификаторов страниц, содержащих путь между двумя страницами, каждый идентификатор преобразуется в его фактический URL и выводится.
Результат для поиска ссылки между страницей о Кевине Бэйконе (идентификатор страницы 1 в этой базе данных) и страницей о Эрике Айдле (идентификатор страницы 28624 в этой базе данных) выглядит следующим образом:
/wiki/Kevin_Bacon
/wiki/Primetime_Emmy_Award_for_Outstanding_Lead_Actor_in_a_Miniseries_or_a_Movie
/wiki/Gary_Gilmore
/wiki/Eric_Idle
Вывод переводится в следующие отношения ссылок: Кевин Бэйкон → Премия «Эмми» → Гари Гилмор → Эрик Айдл.
Дополнительно к решению проблем шести степеней и моделированию того, какие слова обычно следуют за какими другими словами в предложениях, направленные и ненаправленные графы могут быть использованы для моделирования различных ситуаций, встречающихся при парсинге веб-страниц.
- Какие веб-сайты ссылается на другие веб-сайты?
- Какие исследовательские статьи цитируют другие исследовательские статьи?
- Какие продукты обычно показываются вместе с какими другими продуктами на сайте розничной торговли? Какова сила этой связи?
- Является ли связь взаимной?
Распознание этих фундаментальных типов отношений может быть чрезвычайно полезным для создания моделей, визуализаций и прогнозов на основе данных, полученных в результате парсинга.
Natural Language Toolkit
До сих пор этот раздел в основном сосредоточен на статистическом анализе слов в текстовых корпусах. Какие слова наиболее популярны? Какие слова необычны? Какие слова вероятно следуют за какими другими словами? Как они группируются вместе? То, чего вам не хватает, это понимание, по мере возможности, что эти слова представляют собой.
Natural Language Toolkit (NLTK) — это набор библиотек Python, предназначенных для идентификации и маркировки частей речи, найденных в естественных текстах на английском языке. Его разработка началась в 2000 году, и за последние 15 лет десятки разработчиков по всему миру внесли свой вклад в проект. Хотя функциональность, которую он предоставляет, огромна (целые книги посвящены NLTK), этот раздел фокусируется только на нескольких его применениях.
Установка и настройка
Модуль nltk можно установить так же, как и другие модули Python, либо загрузив пакет через веб-сайт NLTK напрямую, либо используя любое количество сторонних установщиков с ключевым словом «nltk». Для полных инструкций по установке см. веб-сайт NLTK.
После установки модуля рекомендуется загрузить его предустановленные репозитории текста, чтобы можно было легче опробовать его функции. Введите это в командной строке Python:
>>> import nltk
>>> nltk.download()
Код открывает загрузчик NLTK (см. Рисунок).
Рекомендуется установить все доступные пакеты при первой попытке использования корпуса NLTK. Вы всегда можете легко удалить пакеты в любое время.
Статистический анализ текста с помощью nltk
NLTK отлично подходит для генерации статистической информации о количестве слов, частоте слов и разнообразии слов в разделах текста. Если вам нужен относительно простой расчет (например, количество уникальных слов в разделе текста), то импортирование nltk может быть излишним — это большой модуль. Однако, если вам нужно провести относительно обширный анализ текста, у вас под рукой есть функции, которые предоставят вам практически любую метрику, которую вы захотите.
Анализ с NLTK всегда начинается с объекта Text. Объекты Text можно создавать из простых строк Python следующим образом:
from nltk import word_tokenize
from nltk import Text
tokens = word_tokenize('Вот немного не очень интересного текста')
text = Text(tokens)
Входными данными для функции word_tokenize может быть любая текстовая строка Python. Если у вас нет под рукой длинных строк, но вы все еще хотите поиграть с функциями, в NLTK уже есть несколько книг, которые можно использовать с помощью функции import:
from nltk.book import *
Код загружает девять книг:
*** Introductory Examples for the NLTK Book ***
Loading text1, ..., text9 and sent1, ..., sent9
Type the name of the text or sentence to view it.
Type: 'texts()' or 'sents()' to list the materials.
text1: Moby Dick by Herman Melville 1851
text2: Sense and Sensibility by Jane Austen 1811
text3: The Book of Genesis
text4: Inaugural Address Corpus
text5: Chat Corpus
text6: Monty Python and the Holy Grail
text7: Wall Street Journal
text8: Personals Corpus
text9: The Man Who Was Thursday by G . K . Chesterton 1908Объектами Text можно манипулировать так же, как обычные массивы Python, как если бы они содержали слова текста. Используя это свойство, вы можете подсчитать количество уникальных слов в тексте и сравнить его с общим количеством слов (помните, что набор Python содержит только уникальные значения):
>>> len(text6)/len(set(text6))
7.833333333333333
Предыдущий пример показывает, что каждое слово в сценарии в среднем использовалось примерно восемь раз. Вы также можете поместить текст в объект частотного распределения, чтобы определить некоторые из самых распространенных слов и частоты для различных слов:
>>> from nltk import FreqDist
>>> fdist = FreqDist(text6)
>>> fdist.most_common(10)
[(':', 1197), ('.', 816), ('!', 801), (',', 731), ("'", 421), ('[', 3
19), (']', 312), ('the', 299), ('I', 255), ('ARTHUR', 225)]
>>> fdist["Grail"]
34
Поскольку это сценарий, могут появиться некоторые артефакты того, как он написан. Например, «ARTHUR» во всех заглавных буквах появляется часто, потому что он появляется перед каждой репликой короля Артура в сценарии. Кроме того, двоеточие (:) появляется перед каждой строкой, действуя в качестве разделителя между именем персонажа и его репликой. Используя этот факт, мы видим, что в фильме 1 197 строки!
То, что мы называли 2-граммами в предыдущих главах, в NLTK называется биграммами (время от времени вы также можете слышать, что 3-граммы называют тримерами, но я предпочитаю 2-граммы и 3-граммы вместо биграмм или триграмм). Вы можете создавать, искать и перечислять 2-граммы очень легко:
>>> from nltk import bigrams
>>> bigrams = bigrams(text6)
>>> bigramsDist = FreqDist(bigrams)
>>> bigramsDist[('Sir', 'Robin')]
18
Для поиска 2-грамм «Sir Robin» вам нужно разбить их на кортеж («Sir», «Robin»), чтобы соответствовать способу представления 2-грамм в распределении частот. Существует также модуль для тримеров, который работает абсолютно так же. Для общего случая вы также можете импортировать модуль ngrams:
>>> from nltk import ngrams
>>> fourgrams = ngrams(text6, 4)
>>> fourgramsDist = FreqDist(fourgrams)
>>> fourgramsDist[('father', 'smelt', 'of', 'elderberries')]
1
Здесь функция ngrams вызывается для разделения объекта текста на n-граммы любого размера, управляемого вторым параметром. В этом случае текст разбивается на 4-граммы. Затем вы можете показать, что фраза «father smelt of elderberries» встречается в сценарии ровно один раз. Распределения частот, объекты текста и n-граммы также могут быть перебраны и обработаны в цикле. Например, следующий код выводит все 4-граммы, начинающиеся с слова «coconut»:
from nltk.book import *
from nltk import ngrams
fourgrams = ngrams(text6, 4)
for fourgram in fourgrams:
if fourgram[0] == 'coconut':
print(fourgram)
Библиотека NLTK имеет огромный набор инструментов и объектов, разработанных для организации, подсчета, сортировки и измерения больших объемов текста. Хотя мы едва задели их возможности, большинство этих инструментов хорошо разработаны и работают довольно интуитивно для кого-то, кто знаком с Python
Лексикографический анализ с помощью nltk
До сих пор вы сравнивали и категоризировали все слова, с которыми встречались, исходя только из их значения по отдельности. Не существует различий между омонимами или контекстом, в котором используются слова. Хотя некоторые люди могут склоняться к тому, чтобы отбросить омонимы как редко встречающиеся проблемы, вы можете удивиться, насколько часто они встречаются.
Большинство носителей языка, вероятно, не всегда осознают, что слово является омонимом, не говоря уже о том, чтобы подумать о том, что оно может быть спутано с другим словом в другом контексте. «Он был объективен в достижении своей цели написать объективную философию, в основном используя глаголы в объектном падеже» легко понимается человеком, но может заставить веб-скрейпер подумать, что одно и то же слово используется четыре раза и привести его к тому, что он просто отбрасывает всю информацию о значении каждого слова.
Кроме того, помимо выявления частей речи, может быть полезно различать слово, используемое одним способом от другого. Например, вы можете захотеть искать названия компаний, состоящих из общих слов, или анализировать мнения о компании. «Продукция ACME хороша» и «Продукция ACME неплоха» могут иметь то же основное значение, даже если одно предложение использует «хорошо», а другое — «плохо».
NLTK по умолчанию использует популярную систему маркировки частей речи, разработанную Университетом Пенсильвании в рамках проекта Penn Treebank. Хотя некоторые из меток имеют смысл (например, CC — союз-связка), другие могут вызывать путаницу (например, RP — частица). Вот ссылка для ознакомления с метками, упоминаемыми в этом разделе:
- CC: союз-связка (Coordinating conjunction)
- CD: количественное числительное (Cardinal number)
- DT: определитель (Determiner)
- EX: существительное «there» (Existential «there»)
- FW: иностранное слово (Foreign word)
- IN: предлог, подчинительный союз (Preposition, subordinating conjunction)
- JJ: прилагательное (Adjective)
- JJR: сравнительная форма прилагательного (Adjective, comparative)
- JJS: превосходная форма прилагательного (Adjective, superlative)
- LS: маркер элемента списка (List item marker)
- MD: модальный глагол (Modal)
- NN: существительное в единственном числе или масса (Noun, singular or mass)
- NNS: существительное во множественном числе (Noun, plural)
- NNP: собственное существительное, единственное число (Proper noun, singular)
- NNPS: собственное существительное, множественное число (Proper noun, plural)
- PDT: предопределитель (Predeterminer)
- POS: притяжательный падеж (Possessive ending)
- PRP: личное местоимение (Personal pronoun)
- PRP$: притяжательное местоимение (Possessive pronoun)
- RB: наречие (Adverb)
- RBR: сравнительная форма наречия (Adverb, comparative)
- RBS: превосходная форма наречия (Adverb, superlative)
- RP: частица (Particle)
- SYM: символ (Symbol)
- TO: «to» (TO)
- UH: междометие (Interjection)
- VB: глагол, основная форма (Verb, base form)
- VBD: глагол, прошедшее время (Verb, past tense)
- VBG: глагол, герундий или причастие настоящего времени (Verb, gerund or present participle)
- VBN: глагол, причастие прошедшего времени (Verb, past participle)
- VBP: глагол, форма настоящего времени для всех лиц, кроме третьего лица единственного числа (Verb, non-third-person singular present)
- VBZ: глагол, форма настоящего времени третьего лица единственного числа (Verb, third person singular present)
- WDT: вопросительный определитель (wh-determiner)
- WP: вопросительное местоимение (Wh-pronoun)
- WP$: притяжательное вопросительное местоимение (Possessive wh-pronoun)
- WRB: вопросительное наречие (Wh-adverb)
Помимо измерения языка, NLTK может помочь в поиске значения слов на основе контекста и своих обширных словарей. На базовом уровне NLTK может идентифицировать части речи:
>>> from nltk.book import *
>>> from nltk import word_tokenize
>>> text = word_tokenize('Strange women lying in ponds distributing swords'\
'is no basis for a system of government.')
>>> from nltk import pos_tag
>>> pos_tag(text)
[('Strange', 'NNP'), ('women', 'NNS'), ('lying', 'VBG'), ('in', 'IN')
, ('ponds', 'NNS'), ('distributing', 'VBG'), ('swords', 'NNS'), ('is'
, 'VBZ'), ('no', 'DT'), ('basis', 'NN'), ('for', 'IN'), ('a', 'DT'),
('system', 'NN'), ('of', 'IN'), ('government', 'NN'), ('.', '.')]
Каждое слово разделено на кортеж, содержащий само слово и метку, идентифицирующую часть речи (см. предыдущий сайдбар для получения дополнительной информации о этих метках). Хотя это может показаться простым поиском, сложность, необходимая для выполнения этой задачи правильно, становится очевидной на следующем примере:
>>> text = word_tokenize('The dust was thick so he had to dust')
>>> pos_tag(text)
[('The', 'DT'), ('dust', 'NN'), ('was', 'VBD'), ('thick', 'JJ'), ('so
', 'RB'), ('he', 'PRP'), ('had', 'VBD'), ('to', 'TO'), ('dust', 'VB')]
Обратите внимание, что слово «dust» используется дважды в предложении: сначала как существительное, а затем как глагол. NLTK правильно идентифицирует оба случая использования на основе их контекста в предложении.
NLTK идентифицирует части речи, используя контекстно-свободную грамматику, определенную английским языком. Контекстно-свободные грамматики — это наборы правил, которые определяют, какие вещи могут следовать за какими другими в упорядоченных списках. В данном случае они определяют, какие части речи могут следовать за какими другими частями речи. Каждый раз, когда встречается двусмысленное слово, такое как «dust», применяются правила контекстно-свободной грамматики, и выбирается соответствующая часть речи, которая соответствует этим правилам.
NLTK можно обучить создавать совершенно новые контекстно-свободные грамматики, например, на иностранном языке. Если вы вручную размечаете большие участки текста на этом языке, используя соответствующие метки Penn Treebank, вы можете передать их обратно в NLTK и обучить его правильно размечать другие тексты, с которыми он может столкнуться. Этот тип обучения является необходимым компонентом любой машинного обучения, о котором мы поговорим далее, когда будем обучать скрейперы распознавать символы CAPTCHA.
Зачем нужно знать, является ли слово глаголом или существительным в данном контексте? Может показаться интересным в научной лаборатории по компьютерным наукам, но как это помогает в веб-скрапинге? Частая проблема при веб-скрапинге связана с поиском. Вы можете скрейпить текст с сайта и хотите искать его по слову «google», но только тогда, когда оно используется как глагол, а не как собственное имя. Или вы можете искать только упоминания компании Google и не хотите полагаться на правильное использование заглавных букв, чтобы найти эти упоминания. В этом случае функция pos_tag может быть чрезвычайно полезной:
from nltk import word_tokenize, sent_tokenize, pos_tag
sentences = sent_tokenize('Google is one of the best companies in the world.'\
' I constantly google myself to see what I\'m up to.')
nouns = ['NN', 'NNS', 'NNP', 'NNPS']
for sentence in sentences:
if 'google' in sentence.lower():
taggedWords = pos_tag(word_tokenize(sentence))
for word in taggedWords:
if word[0].lower() == 'google' and word[1] in nouns:
print(sentence)
Этот код печатает только предложения, которые содержат слово «google» (или «Google») как существительное, а не как глагол. Конечно, вы можете быть более конкретными и требовать, чтобы печатались только упоминания Google с меткой «NNP» (собственное имя), но даже NLTK иногда ошибается, и может быть хорошо оставить себе немного гибкости в зависимости от применения.
Большая часть неоднозначности естественного языка может быть разрешена с использованием функции pos_tag из NLTK. Поиск текста не только по экземплярам вашего целевого слова или фразы, но и по экземплярам вашего целевого слова или фразы плюс его метке может значительно повысить точность и эффективность поиска вашего скрапера.
Дополнительные ресурсы
Обработка, анализ и понимание естественного языка с использованием машин – одна из самых сложных задач в компьютерных науках, и на эту тему было написано бесчисленное количество книг и научных статей. Я надеюсь, что описание здесь вдохновит вас на мысли за пределами традиционного веб-скрапинга, или хотя бы даст некоторое начальное направление о том, с чего начать при выполнении проекта, который требует анализа естественного языка.
Существует множество отличных ресурсов по введению в обработку языка искусственного и Python’s Natural Language Toolkit. В частности, книга Стивена Берда, Юэна Кляйна и Эдварда Лопера «Natural Language Processing with Python» (O’Reilly) представляет собой как всесторонний, так и вводный подход к теме.
Кроме того, книга Джеймса Пустежовски и Эмбер Стаббс «Natural Language Annotations for Machine Learning» (O’Reilly) предоставляет немного более продвинутое теоретическое руководство.
Для реализации изученных уроков вам потребуется знание Python; рассмотренные темы идеально сочетаются с Natural Language Toolkit для Python.
Работа с русским языком в nltk
обработка естественного русского языка имеет свои особенности, но многие инструменты и методы, используемые для анализа английского языка, также применимы и к русскому. Давайте рассмотрим некоторые основные задачи обработки русского текста и соответствующие им примеры с использованием библиотеки Natural Language Toolkit (NLTK) для Python:
- Токенизация: Разбиение текста на отдельные слова или фразы.
from nltk.tokenize import word_tokenize text = "Мама мыла раму и готовила ужин." tokens = word_tokenize(text, language='russian') print(tokens) # ['Мама', 'мыла', 'раму', 'и', 'готовила', 'ужин', '.']
- Частеречная разметка: Определение частей речи каждого слова в тексте.
from nltk import pos_tag from nltk.tokenize import word_tokenize text = "Мама мыла раму и готовила ужин." tokens = word_tokenize(text, language='russian') tagged_words = pos_tag(tokens, lang='rus') print(tagged_words) # [('Мама', 'NOUN'), ('мыла', 'VERB'), ('раму', 'NOUN'), ('и', 'CONJ'), ('готовила', 'VERB'), ('ужин', 'NOUN'), ('.', 'PUNCT')]
- Лемматизация: Приведение слова к его нормальной форме (лемме).
from pymystem3 import Mystem text = "Мама мыла раму и готовила ужин." mystem = Mystem() lemmas = mystem.lemmatize(text) print(''.join(lemmas)) # 'мама мыть рама и готовить ужин\n'
- Анализ синтаксиса: Изучение структуры предложения и взаимосвязей между словами.
from nltk.parse import DependencyGraph text = "Мама мыла раму и готовила ужин." parsed_text = "1 Мама мама NOUN _ Animacy=Anim|Case=Nom|Gender=Fem|Number=Sing 2 nsubj _ _\n2 мыла мыть VERB _ Aspect=Imp|Gender=Fem|Mood=Ind|Number=Sing|Tense=Past|VerbForm=Fin|Voice=Act 0 root _ _\n3 раму рама NOUN _ Animacy=Inan|Case=Acc|Gender=Fem|Number=Sing 2 obj _ _\n4 и и CCONJ _ _ 5 cc _ _\n5 готовила готовить VERB _ Aspect=Imp|Gender=Fem|Mood=Ind|Number=Sing|Tense=Past|VerbForm=Fin|Voice=Act 2 conj _ _\n6 ужин ужин NOUN _ Animacy=Inan|Case=Acc|Gender=Masc|Number=Sing 5 obj _ _\n7 . . PUNCT _ _ 2 punct _ _\n" dep_graph = DependencyGraph(parsed_text) print(dep_graph.tree()) # (мыла (Мама) (раму) (и (готовила (ужин)))))
Это лишь небольшой обзор того, как можно использовать NLTK и другие инструменты для обработки естественного русского языка. Учтите, что для работы с русским текстом могут потребоваться специализированные библиотеки, такие как pymystem3 для лемматизации.
Индивидуальное и групповое обучение «Аналитик данных»
Если вы хотите стать экспертом в аналитике, могу помочь. Запишитесь на мой курс «Аналитик данных» и начните свой путь в мир ИТ уже сегодня!
Контакты
Для получения дополнительной информации и записи на курсы свяжитесь со мной:
Телеграм: https://t.me/Vvkomlev
Email: victor.komlev@mail.ru
Объясняю сложное простыми словами. Даже если вы никогда не работали с ИТ и далеки от программирования, теперь у вас точно все получится! Проверено десятками примеров моих учеников.
Гибкий график обучения. Я предлагаю занятия в мини-группах и индивидуально, что позволяет каждому заниматься в удобном темпе. Вы можете совмещать обучение с работой или учебой.
Практическая направленность. 80%: практики, 20% теории. У меня множество авторских заданий, которые фокусируются на практике. Вы не просто изучаете теорию, а сразу применяете знания в реальных проектах и задачах.
Разнообразие учебных материалов: Теория представлена в виде текстовых уроков с примерами и видео, что делает обучение максимально эффективным и удобным.
Понимаю, что обучение информационным технологиям может быть сложным, особенно для новичков. Моя цель – сделать этот процесс максимально простым и увлекательным. У меня персонализированный подход к каждому ученику. Максимальный фокус внимания на ваши потребности и уровень подготовки.