JavaScript традиционно является наказанием для веб-пауков. В какой-то момент в древней истории интернета вы могли быть уверены, что запрос, который вы отправляли на веб-сервер, извлекал те же данные, которые видел пользователь в своем веб-браузере, когда делал тот же запрос.
В предыдущем разделе вы рассмотрели один из способов решения этой проблемы: использование Selenium для автоматизации браузера и получения данных. Это легко сделать. Это работает практически всегда. Проблема в том, что когда у вас есть «молоток» такой мощный и эффективный, как Selenium, каждая проблема веб-скрапинга начинает выглядеть как гвоздь.
В этом разделе вы рассмотрите полное получение данных без JavaScript (нет необходимости выполнять его или даже загружать!) и непосредственно перейдете к источнику данных: к API, которые их генерируют.
Краткое введение в API
Хотя бесчисленное количество книг, выступлений и руководств было написано о тонкостях REST, GraphQL, JSON и XML API, в их основе лежит простая концепция. API определяет стандартизированный синтаксис, который позволяет одному программному обеспечению обмениваться данными с другим программным обеспечением, даже если они написаны на разных языках или имеют иной структуру.
Этот раздел сосредотачивается на веб-API (в частности, API, которые позволяют веб-серверу общаться с браузером) и использует термин API для обозначения именно этого типа. Но стоит иметь в виду, что в других контекстах API также является общим термином, который может использоваться, например, для обеспечения связи между программой на Java и программой на Python, запущенными на одной машине. API не всегда должен быть «через интернет» и не обязательно включает в себя какие-либо веб-технологии.
Веб-API чаще всего используются разработчиками, которые используют хорошо рекламируемые и задокументированные общедоступные службы. Например, ESPN предоставляет API для информации об атлетах, счетах игр и многого другого. У Google есть десятки API в разделе разработчиков для переводов текста, аналитики и геолокации.
Документация для этих API обычно описывает маршруты или конечные точки как URL-адреса, которые можно запросить с переменными параметрами, либо в пути URL, либо как GET-параметры.
Например, следующий URL предоставляет pathparam в качестве параметра в маршруте: http://example.com/the-api-route/pathparam А это предоставляет pathparam в качестве значения для параметра param1: http://example.com/the-api-route?param1=pathparam
Оба способа передачи переменных данных в API часто используются, хотя, как и многие темы в компьютерной науке, философский спор о том, когда и где следует передавать переменные через путь или через параметры, продолжается.
Ответ от API обычно возвращается в формате JSON или XML. JSON в наше время намного популярнее, чем XML, но вы все еще можете увидеть некоторые XML-ответы. Многие API позволяют вам изменить тип ответа, обычно с помощью еще одного параметра для определения желаемого типа ответа.
Вот пример ответа API в формате JSON: {«user»:{«id»: 123, «name»: «Ryan Mitchell», «city»: «Boston»}}
Вот пример ответа API в формате XML: <user><id>123</id><name>Ryan Mitchell</name><city>Boston</city></user>
FreeGeoIP предоставляет простой и удобный API, который преобразует IP-адреса в реальные физические адреса. Вы можете попробовать простой запрос API, введя следующее в свой браузер: http://freegeoip.net/json/50.78.253.58
Это должно вызвать следующий ответ: {«ip»:»50.78.253.58″,»country_code»:»US»,»country_name»:»United States», «region_code»:»MA»,»region_name»:»Massachusetts»,»city»:»Boston», «zip_code»:»02116″,»time_zone»:»America/New_York»,»latitude»:42.3496, «longitude»:-71.0746,»metro_code»:506}
Обратите внимание, что запрос содержит параметр json в пути. Вы можете запросить ответ в формате XML или CSV, изменив этот параметр соответственно: http://freegeoip.net/xml/50.78.253.58 http://freegeoip.net/csv/50.78.253.58
Методы HTTP и API
В предыдущем разделе вы рассмотрели API, сделавший GET-запрос к серверу для получения информации. Существует четыре основных способа (или метода) запроса информации с веб-сервера через HTTP:
- GET
- POST
- PUT
- DELETE
Технически существует больше четырех методов (такие как HEAD , OPTIONS и CONNECT ), но они редко используются в API, и маловероятно, что вы когда-либо увидите их. Большинство API ограничивают себя этими четырьмя методами, или даже подмножеством из них. Обычно API используют только GET , либо GET и POST .
GET — это то, что вы используете, когда посещаете веб-сайт через адресную строку браузера. GET — это метод, который вы используете, когда делаете вызов по адресу http://freegeoip.net/json/50.78.253.58. Вы можете представить себе GET как запрос: «Привет, веб-сервер, пожалуйста, получи/получи для меня эту информацию.» Запрос GET по определению не вносит изменений в информацию в базе данных сервера. Ничего не сохраняется; ничего не модифицируется. Информация только читается.
POST — это то, что вы используете, когда заполняете форму или отправляете информацию, предположительно, на бэкенд-скрипт на сервере. Каждый раз, когда вы входите на веб-сайт, вы делаете POST-запрос с вашим именем пользователя и (надеюсь) зашифрованным паролем. Если вы делаете POST-запрос с API, вы говорите: «Пожалуйста, сохраните эту информацию в вашей базе данных.»
PUT — используется реже при взаимодействии с веб-сайтами, но время от времени используется в API. Запрос PUT используется для обновления объекта или информации. Например, API может требовать POST-запроса для создания нового пользователя, но может потребоваться PUT-запрос, если вы хотите обновить адрес электронной почты этого пользователя.
DELETE используется, как вы могли подумать, для удаления объекта. Например, если вы отправите DELETE-запрос по адресу http://myapi.com/user/23, он удалит пользователя с ID 23. Методы DELETE редко встречаются в общедоступных API, которые в основном созданы для распространения информации или позволяют пользователям создавать или публиковать информацию, а не позволяют пользователям удалять эту информацию из их баз данных.
В отличие от GET-запросов, POST , PUT и DELETE-запросы позволяют отправлять информацию в теле запроса, помимо URL или маршрута, откуда вы запрашиваете данные.
Как и ответ, который вы получаете от веб-сервера, эти данные в теле обычно форматируются как JSON или, менее распространенно, как XML, и формат этих данных определяется синтаксисом API.
Например, если вы используете API, которое создает комментарии к блоговым постам, вы можете сделать PUT-запрос по адресу http://example.com/comments?post=123 с следующим телом запроса:
{"title": "Отличный пост о API!", "body": "Очень информативно. Действительно помогло мне с трудной технической задачей, с которой я столкнулся. Спасибо за то, что вы потратили время, чтобы написать такой подробный блог-пост о PUT-запросах!", "author": {"name": "Райан Митчелл", "website": "http://pythonscraping.com", "company": "O'Reilly Media"}}Обратите внимание, что ID блогового поста ( 123 ) передается в качестве параметра в URL, а контент для нового комментария передается в теле запроса. Параметры и данные могут передаваться как в параметре, так и в теле. Какие параметры требуются и где они передаются, определяется синтаксисом API.
Форматы ответов API
Как вы видели в примере FreeGeoIP в начале главы, важной особенностью API является их хорошо отформатированные ответы. Самые распространенные типы форматирования ответов — это расширяемый язык разметки (XML) и нотация объектов JavaScript (JSON).
В последние годы JSON стал намного популярнее, чем XML, по нескольким основным причинам. Во-первых, файлы JSON обычно меньше по размеру, чем хорошо спроектированные файлы XML. Сравните, например, следующие данные XML, которые составляют 98 символов:
<user><firstname>Ryan</firstname><lastname>Mitchell</lastname><username>Kludgist</username></user>
Теперь посмотрите на те же данные в формате JSON:
{"user":{"firstname":"Ryan","lastname":"Mitchell","username":"Kludgist"}}
Это всего лишь 73 символа, или на целых 36% меньше, чем эквивалентный XML.
Конечно, можно возразить, что XML можно отформатировать так:
<user firstname="ryan" lastname="mitchell" username="Kludgist"></user>
Но это считается плохой практикой, потому что это не поддерживает глубокое вложение данных. Тем не менее, это все равно требует 71 символа, примерно такой же длины, как эквивалентный JSON.
Еще одна причина, по которой JSON быстро становится более популярным, чем XML, — это изменение в веб-технологиях. В прошлом было более распространено использование скриптов на стороне сервера, таких как PHP или .NET, на стороне приема API. В настоящее время вероятно, что фреймворк, такой как Angular или Backbone, будет отправлять и получать вызовы API. Технологии на стороне сервера в значительной степени нейтральны по отношению к форме, в которой поступают их данные. Но JavaScript-библиотеки, такие как Backbone, находят JSON легче для обработки.
Хотя API обычно считаются имеющими либо XML-ответ, либо JSON-ответ, возможно все. Тип ответа API ограничен только воображением программиста, создавшего его. CSV — еще один типичный выходной формат ответа (как видно в примере FreeGeoIP). Некоторые API могут даже быть разработаны для создания файлов. Может быть сделан запрос к серверу для создания изображения с определенным текстом, наложенным на него, или запрос на конкретный файл XLSX или PDF.
Некоторые API вообще не возвращают ответа. Например, если вы делаете запрос к серверу для создания нового комментария к блогу, он может вернуть только HTTP-код ответа 200, что означает «Я опубликовал комментарий, все отлично!». Другие могут вернуть минимальный ответ вроде этого:
{"success": true}
Если произошла ошибка, вы можете получить ответ вроде этого:
{"error": {"message": "Произошло что-то очень плохое"}}
Или, если API не настроено особенно хорошо, вы можете получить неанализируемый стек вызовов или какой-то простой английский текст. При запросе к API обычно разумно сначала проверить, действительно ли ответ, который вы получаете, является JSON (или XML, или CSV, или каким бы то ни было форматом ответа, который вы ожидаете).
Разбор JSON
В этом разделе вы рассмотрели различные типы API и их функционирование, а также просматривали образцы JSON-ответов от этих API. Теперь давайте посмотрим, как разбирать и использовать эту информацию.
В начале раздела вы видели пример использования IP-адреса freegeoip.net, который преобразует IP-адреса в физические адреса: http://freegeoip.net/json/50.78.253.58 Вы можете взять вывод этого запроса и использовать функции парсинга JSON в Python для его декодирования:
import json
from urllib.request import urlopen
def getCountry(ipAddress):
response = urlopen('http://freegeoip.net/json/'+ipAddress).read().decode('utf-8')
responseJson = json.loads(response)
return responseJson.get('country_code')
print(getCountry('50.78.253.58'))
Этот код выводит код страны для IP-адреса 50.78.253.58.
Библиотека для парсинга JSON, используемая здесь, является частью стандартной библиотеки Python. Просто напишите import json в начале, и вы готовы к работе! В отличие от многих языков, которые могут парсить JSON в специальный объект JSON или узел JSON, Python использует более гибкий подход и преобразует объекты JSON в словари, массивы JSON в списки, строки JSON в строки и так далее. Таким образом, крайне легко получить доступ и изменить значения, хранящиеся в JSON.
Ниже приведен быстрый пример того, как библиотека JSON Python обрабатывает значения, которые могут встречаться в строке JSON:
import json
jsonString = '{"arrayOfNums":[{"number":0},{"number":1},{"number":2}], "arrayOfFruits":[{"fruit":"apple"},{"fruit":"banana"}, {"fruit":"pear"}]}'
jsonObj = json.loads(jsonString)
print(jsonObj.get('arrayOfNums'))
print(jsonObj.get('arrayOfNums')[1])
print(jsonObj.get('arrayOfNums')[1].get('number') + jsonObj.get('arrayOfNums')[2].get('number'))
print(jsonObj.get('arrayOfFruits')[2].get('fruit'))
Вот вывод:
[{'number': 0}, {'number': 1}, {'number': 2}]
{'number': 1}
3
pear
Строка 1 — это список словарных объектов, строка 2 — словарный объект, строка 3 — целое число (сумма целых чисел, полученных из словарей), а строка 4 — строка.
Недокументированные API
До сих пор в этой главе мы обсуждали только API, которые имеют документацию. Их разработчики предполагают, что они будут использованы публично, публикуют информацию о них и предполагают, что другие разработчики будут использовать эти API. Но подавляющее большинство API вообще не имеют опубликованной документации.
Но зачем создавать API без какой-либо публичной документации? Как упоминалось в начале раздела, все это связано с JavaScript.
Традиционно веб-серверы динамических сайтов имели несколько задач при запросе пользователем страницы:
- Обрабатывать GET-запросы от пользователей, запрашивающих страницу веб-сайта
- Извлекать данные из базы данных, которые отображаются на этой странице
- Форматировать данные в HTML-шаблон для страницы
- Отправлять этот отформатированный HTML пользователю
По мере того как фреймворки JavaScript становились более распространенными, многие задачи по созданию HTML, которые раньше выполнялись сервером, переместились в браузер. Сервер мог отправить заранее сформированный HTML-шаблон в браузер пользователя, но отдельные запросы Ajax могли быть выполнены для загрузки контента и размещения его на соответствующих местах в этом HTML-шаблоне. Все это происходило на стороне браузера/клиента.
Это изначально была проблема для веб-скраперов. Они были привыкли делать запрос для HTML-страницы и получать в ответ ровно то, что запрашивали — HTML-страницу со всем содержимым на месте. Вместо этого они теперь получали HTML-шаблон без какого-либо контента.
Для решения этой проблемы использовался Selenium. Теперь веб-скрапер программиста мог стать браузером, запросить HTML-шаблон, выполнить любой JavaScript, дать всем данным загрузиться на своем месте, и только потом сканировать страницу для получения данных. Поскольку весь HTML был загружен, это по сути была решенная ранее проблема — проблема парсинга и форматирования существующего HTML.
Однако, поскольку вся система управления контентом (которая ранее находилась только на веб-сервере) по существу переместилась в клиентский браузер, даже самые простые веб-сайты могли раздуться до нескольких мегабайт контента и десятков HTTP-запросов. Кроме того, при использовании Selenium загружаются все «лишние» данные, которые не обязательно нужны пользователю. Запросы к службам отслеживания, загрузка боковых рекламных баннеров, вызовы служб отслеживания для боковых рекламных баннеров. Изображения, CSS, данные о сторонних шрифтах — все это нужно загружать. Это может показаться замечательным, когда вы используете браузер для просмотра веб-сайтов, но если вы пишете веб-скрапер, который должен работать быстро, собирать определенные данные и нагружать веб-сервер как можно меньше, вы можете загружать в сто раз больше данных, чем вам нужно.
Но есть и положительная сторона всего этого JavaScript, Ajax и современной веб-технологии: поскольку серверы больше не форматируют данные в HTML, они часто действуют как тонкие оболочки вокруг самих баз данных. Эта тонкая оболочка просто извлекает данные из базы данных и возвращает их на страницу через API.
Конечно, эти API не предназначены для использования кем-либо или чем-либо, кроме самой веб-страницы, поэтому разработчики оставляют их недокументированными и предполагают (или надеются), что никто на них не обратит внимания. Но они существуют.
Например, веб-сайт The New York Times загружает все свои результаты поиска с помощью JSON. Если вы посетите ссылку
https://query.nytimes.com/search/sitesearch/#/python
это покажет недавние новостные статьи по запросу «python». Если вы парсите эту страницу с помощью urllib или библиотеки Requests, вы не найдете никаких результатов поиска. Они загружаются отдельно через вызов API:
https://query.nytimes.com/svc/add/v1/sitesearch.json?q=python&spotlight=true&facet=true
Если бы вы загрузили эту страницу с помощью Selenium, вы бы сделали около 100 запросов и передали бы 600–700 кб данных при каждом поиске. Используя API напрямую, вы делаете только один запрос и передаете приблизительно только 60 кб красиво оформленных данных, которые вам нужны.
Нахождение недокументированных API
Вы уже использовали инспектор Chrome в предыдущих главах, чтобы изучить содержимое HTML-страницы, но теперь вы будете использовать его для немного другой цели: чтобы изучить запросы и ответы вызовов, которые используются для построения этой страницы.
Для этого откройте окно инспектора Chrome и перейдите на вкладку «Network», как показано на рисунке
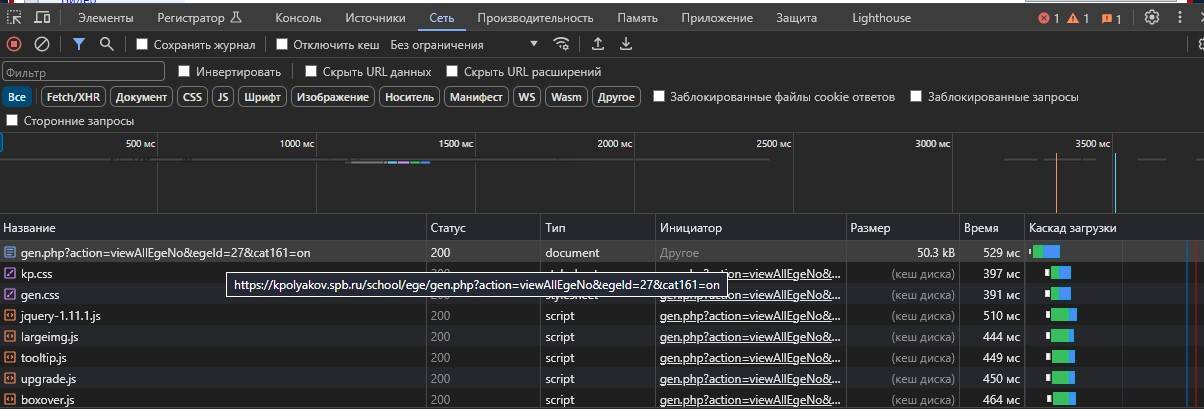
Обратите внимание, что вам нужно открыть это окно до загрузки страницы. Оно не отслеживает сетевые вызовы, когда закрыто.
Пока страница загружается, вы увидите строку, появляющуюся в реальном времени, когда ваш браузер делает запрос обратно к веб-серверу за дополнительной информацией для отображения страницы. Это может включать в себя вызов API.
Нахождение недокументированных API может потребовать немного работы детектива (чтобы избежать этой работы детектива, см. «Автоматическое нахождение и документирование API»), особенно с большими сайтами с большим количеством сетевых вызовов. Однако, в целом, вы узнаете их, когда увидите.
Вызовы API обычно имеют несколько характеристик, которые полезны для их обнаружения в списке сетевых вызовов:
- Они часто содержат JSON или XML. Вы можете отфильтровать список запросов, используя поле поиска/фильтрации.
- С GET-запросами URL будет содержать передаваемые им параметры. Это будет полезно, например, если вы ищете вызов API, который возвращает результаты поиска или загружает данные для конкретной страницы. Просто отфильтруйте результаты с помощью термина поиска, идентификатора страницы или другой идентифицирующей информации.
- Они обычно будут типа XHR.
API могут не всегда быть очевидными, особенно на больших сайтах с множеством функций, которые могут выполнять сотни вызовов при загрузке одной страницы. Однако обнаружение «иголки в стоге сена» становится намного проще, если немного попрактиковаться.
Документирование API
После того как вы обнаружили вызов API, часто полезно документировать его, особенно если ваши скрейперы будут сильно полагаться на этот вызов. Вам может потребоваться загрузить несколько страниц на веб-сайте, отфильтровав целевой вызов API во вкладке сети консоли инспектора. Таким образом, вы сможете увидеть, как меняется вызов от страницы к странице, и определить поля, которые он принимает и возвращает.
Каждый вызов API можно идентифицировать и задокументировать, обратив внимание на следующие поля:
- Используемый метод HTTP
- Входные данные
- Параметры пути
- Заголовки (включая куки)
- Содержимое тела (для вызовов PUT и POST)
- Выходные данные
- Заголовки ответа (включая установленные куки)
- Тип тела ответа
- Поля тела ответа
Автоматический поиск и документирование API
Поиск и документирование API могут показаться несколько трудоемкими и алгоритмическими задачами. Это в основном потому, что так оно и есть. Хотя некоторые веб-сайты могут пытаться затруднить определение того, как браузер получает свои данные, что делает задачу немного сложнее, поиск и документирование API в основном являются программной задачей.
Загляните в репозиторий GitHub по адресу https://github.com/REMitchell/apiscraper, который пытается автоматизировать часть этой задачи.
Для этого используются Selenium, ChromeDriver и библиотека BrowserMob Proxy для загрузки страниц, сканирования страниц в пределах домена, анализа сетевого трафика, происходящего во время загрузки страницы, и организации этих запросов в читаемые вызовы API.
Для запуска этого проекта требуются несколько компонентов. Во-первых, само программное обеспечение.
Клонируйте проект apiscraper из GitHub. Клонированный проект должен содержать следующие файлы:
- apicall.py
Содержит атрибуты, определяющие вызов API (путь, параметры и т. д.), а также логику определения того, являются ли два вызова API одинаковыми. - apiFinder.py
Основной класс сканирования. Используется webservice.py и consoleservice.py для запуска процесса поиска API. - browser.py
Содержит всего три метода — initialize, get и close, но включает относительно сложную функциональность для связи сервера BrowserMob Proxy и Selenium. Прокручивает страницы, чтобы убедиться, что вся страница загружена, сохраняет файлы HTTP Archive (HAR) в соответствующем месте для обработки. - consoleservice.py
Обрабатывает команды из консоли и запускает основной класс APIFinder. - harParser.py
Анализирует файлы HAR и извлекает вызовы API. - html_template.html
Предоставляет шаблон для отображения вызовов API в браузере. - README.md
Страница readme в Git. - Загрузите двоичные файлы BrowserMob Proxy с https://bmp.lightbody.net/ и поместите извлеченные файлы в каталог проекта apiscraper.
На момент написания этого текста текущая версия BrowserMob Proxy — 2.1.4, поэтому этот скрипт предполагает, что двоичные файлы находятся в browsermob-proxy-2.1.4/bin/browsermob-proxy относительно корневого каталога проекта. Если это не так, вы можете указать другой каталог во время выполнения или (возможно, проще) изменить код в apiFinder.py.
Загрузите ChromeDriver и поместите его в каталог проекта apiscraper.
Вам нужно будет установить следующие библиотеки Python:
- tldextract
- selenium
- browsermob-proxy
Когда все будет сделано, вы будете готовы начать сбор вызовов API.
Ввод
python consoleservice.py -hпредложит вам список опций для начала работы.
Вы можете искать вызовы API, сделанные на одной странице для одного поискового запроса. Например, вы можете искать страницу на http://target.com для API, возвращающего данные о продукте, чтобы заполнить страницу продукта:
$ python consoleservice.py -u https://www.target.com/p/rogue-one-a-star-wars-\
story-blu-ray-dvd-digital-3-disc/-/A-52030319 -s "Rogue One: A Star Wars Story"
Скрипт вернет информацию, включая URL, для API, которое возвращает данные о продукте для этой страницы:
URL: https://redsky.target.com/v2/pdp/tcin/52030319
METHOD: GET
AVG RESPONSE SIZE: 34834
SEARCH TERM CONTEXT: c":"786936852318","product_description":{"title":
"Rogue One: A Star Wars Story (Blu-ray + DVD + Digital) 3 Disc",
"long_description":...
С помощью флага -i можно сканировать несколько страниц (по умолчанию только одну страницу), начиная с предоставленного URL. Это может быть полезно для поиска всего сетевого трафика по определенным ключевым словам или, опустив флаг поискового запроса -s, собирая весь трафик API, который возникает при загрузке каждой страницы.
Все собранные данные хранятся в виде файла HAR по умолчанию в каталоге /har в корневом каталоге проекта, хотя этот каталог можно изменить с помощью флага -d.
Если URL не предоставлен, вы также можете передать каталог предварительно собранных файлов HAR для поиска и анализа.
Этот проект предоставляет множество других функций, включая следующие:
- Удаление ненужных параметров (удаление параметров GET или POST, которые не влияют на возвращаемое значение вызова API)
- Несколько форматов вывода API (командная строка, HTML, JSON)
- Различие между параметрами пути, указывающими на отдельный маршрут API, и параметрами пути, которые действуют просто как GET-параметры для того же маршрута API
Также планируется дальнейшее развитие, поскольку мы продолжаем использовать его для веб-скрапинга и сбора API.
Комбинирование API и других источников данных
Хотя основная цель многих современных веб-приложений заключается в том, чтобы взять существующие данные и форматировать их более привлекательным образом, я бы поспорил, что это не всегда интересно. Если вы используете API как единственный источник данных, лучшее, что вы можете сделать, — это просто скопировать базу данных кого-то другого, которая уже существует и, по сути, уже опубликована. Гораздо интереснее объединить два или более источников данных или использовать API как инструмент для анализа данных, полученных с помощью скрапинга, с новой перспективы.
Давайте рассмотрим пример того, как данные из API можно использовать совместно с веб-скрапингом, чтобы определить, какие части мира вносят наибольший вклад в Википедию.
Если вы провели много времени на Википедии, вы, вероятно, сталкивались с страницей истории правок статьи, на которой отображается список недавних правок. Если пользователи выполняют вход на Википедию при редактировании, их имя пользователя отображается. Если они не выполняют вход, их IP-адрес записывается, как показано на рисунке.
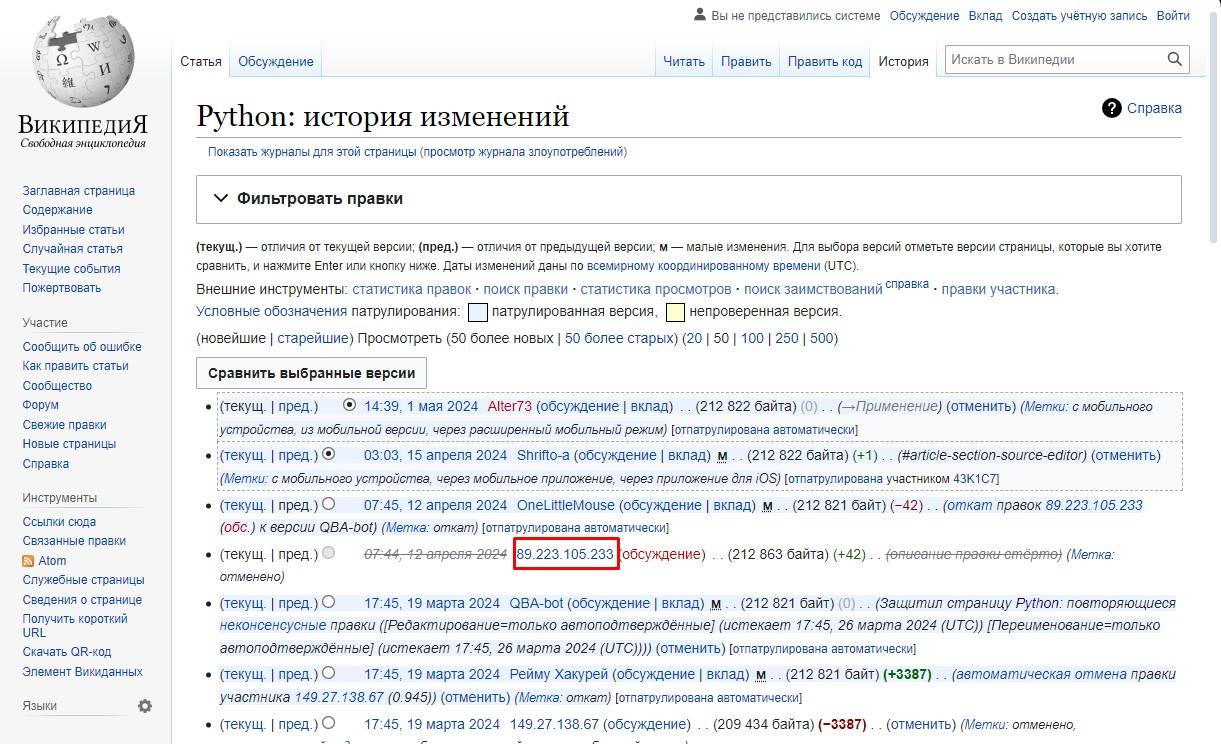
IP-адрес, указанный на странице истории, — 89.223.105.233. Используя API freegeoip.net, этот IP-адрес принадлежит Москва, Россия на момент написания этого текста (IP-адреса иногда могут смещаться географически).
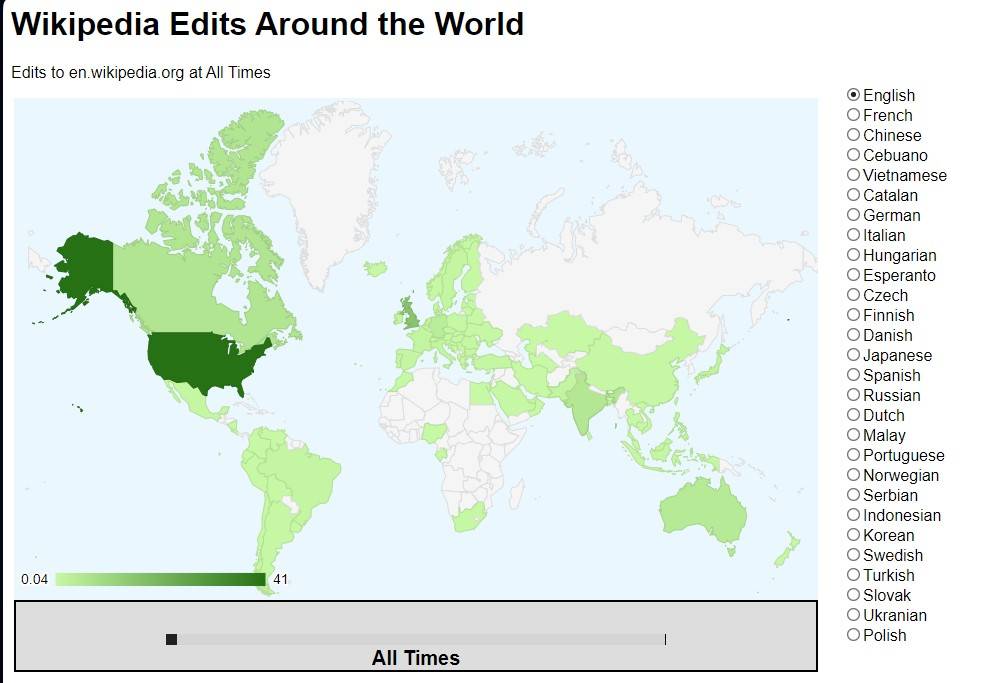
Эта информация сама по себе не так интересна, но что, если бы вы могли собрать много географических данных о правках в Википедии и местах их происхождения? Несколько лет назад я сделал именно это и использовал библиотеку GeoChart от Google для создания интересной диаграммы, которая показывает, откуда поступают правки на англоязычной Википедии, а также на Википедиях, написанных на других языках.
Создание базового скрипта, который сканирует Википедию, ищет страницы истории правок, а затем ищет IP-адреса на этих страницах истории, несложно. С использованием измененного кода из раздела «Написание веб пауков», следующий скрипт делает именно это:
from urllib.request import urlopen
from bs4 import BeautifulSoup
import json
import datetime
import random
import re
random.seed(datetime.datetime.now())
def getLinks(articleUrl):
html = urlopen('http://en.wikipedia.org{}'.format(articleUrl))
bs = BeautifulSoup(html, 'html.parser')
return bs.find('div', {'id':'bodyContent'}).findAll('a', href=re.compile('^(/wiki/)((?!:).)*$'))
def getHistoryIPs(pageUrl):
# Format of revision history pages is:
# http://en.wikipedia.org/w/index.php?title=Title_in_URL&action=history
pageUrl = pageUrl.replace('/wiki/', '')
historyUrl = 'http://en.wikipedia.org/w/index.php?title={}&action=history'.format(pageUrl)
print('history url is: {}'.format(historyUrl))
html = urlopen(historyUrl)
bs = BeautifulSoup(html, 'html.parser')
# finds only the links with class "mw-anonuserlink" which has IP addresses
# instead of usernames
ipAddresses = bs.findAll('a', {'class':'mw-anonuserlink'})
addressList = set()
for ipAddress in ipAddresses:
addressList.add(ipAddress.get_text())
return addressList
links = getLinks('/wiki/Python_(programming_language)')
while(len(links) > 0):
for link in links:
print('-'*20)
historyIPs = getHistoryIPs(link.attrs['href'])
for historyIP in historyIPs:
print(historyIP)
newLink = links[random.randint(0, len(links)-1)].attrs['href']
links = getLinks(newLink)
Эта программа использует две основные функции: getLinks (которая также использовалась в главе 3) и новую getHistoryIPs, которая ищет содержимое всех ссылок с классом mw-anonuserlink (указывающих на анонимного пользователя с IP-адресом, а не именем пользователя) и возвращает его в виде набора.
Этот код также использует несколько произвольный (но эффективный с точки зрения этого примера) шаблон поиска для статей, из которых нужно извлечь истории версий. Он начинает с извлечения историй всех статей Википедии, на которые ссылается стартовая страница (в данном случае статья о языке программирования Python). Затем случайным образом выбирается новая стартовая страница, и извлекаются все страницы истории версий статей, на которые ссылается эта страница. Этот процесс продолжается до тех пор, пока не будет найдена страница без ссылок.
Теперь, когда у вас есть код, который извлекает IP-адреса в виде строки, вы можете объединить это с функцией getCountry из предыдущего раздела, чтобы определить страны, соответствующие этим IP-адресам. Вы немного измените getCountry, чтобы учитывать недопустимые или неправильно сформированные IP-адреса, которые приведут к ошибке 404 Not Found (на момент написания этого текста FreeGeoIP не разрешает IPv6, что может вызвать такую ошибку):
def getCountry(ipAddress):
try:
response = urlopen('http://freegeoip.net/json/{}'.format(ipAddress)).read().decode('utf-8')
except HTTPError:
return None
responseJson = json.loads(response)
return responseJson.get('country_code')
links = getLinks('/wiki/Python_(programming_language)')
while(len(links) > 0):
for link in links:
print('-'*20)
historyIPs = getHistoryIPs(link.attrs["href"])
for historyIP in historyIPs:
country = getCountry(historyIP)
if country is not None:
print('{} is from {}'.format(historyIP, country))
newLink = links[random.randint(0, len(links)-1)].attrs['href']
links = getLinks(newLink)
Вот пример вывода:
-------------------
history url is: http://en.wikipedia.org/w/index.php?title=Programming_
paradigm&action=history
68.183.108.13 is from US
86.155.0.186 is from GB
188.55.200.254 is from SA
108.221.18.208 is from US
141.117.232.168 is from CA
76.105.209.39 is from US
182.184.123.106 is from PK
212.219.47.52 is from GB
72.27.184.57 is from JM
49.147.183.43 is from PH
209.197.41.132 is from US
174.66.150.151 is from US
Этот код выполняет поиск историй правок для всех страниц Википедии, связанных с языком программирования Python, а затем определяет страну, соответствующую каждому IP-адресу из этих историй правок.
Больше про API
Этот раздел продемонстрировал несколько способов, которыми современные API обычно используются для доступа к данным в сети, и как эти API могут использоваться для создания быстрых и мощных веб-скреперов. Если вы хотите создавать API вместо того, чтобы просто использовать их, или если вы хотите узнать больше о теории их построения и синтаксисе, я рекомендую книгу «RESTful Web APIs» Леонарда Ричардсона, Майка Амундсена и Сэма Руби (O’Reilly).
Эта книга предоставляет крепкий обзор теории и практики использования API в сети. Кроме того, Майк Амундсен имеет увлекательную видеосерию «Designing APIs for the Web» (O’Reilly), которая учит, как создавать собственные API — полезное знание, если вы решите сделать свои скрапированные данные доступными для общественности в удобном формате.
Хотя некоторые могут сожалеть о всеобщем использовании JavaScript и динамических веб-сайтов, что делает устаревшими традиционные практики «забери и распарси HTML-страницу», я, например, приветствую наших новых роботов. Поскольку динамические веб-сайты все меньше полагаются на HTML-страницы для человеческого потребления и все больше на строго форматированные файлы JSON для обработки HTML, это приносит пользу всем, кто пытается получить чистые, хорошо отформатированные данные.
Веб больше не является собранием HTML-страниц с случайными мультимедийными и CSS-украшениями. Это собрание сотен типов файлов и форматов данных, мчащихся сотнями за раз, чтобы формировать страницы, которые вы потребляете через свой браузер. Настоящий трюк часто заключается в том, чтобы смотреть за пределами страницы перед вами и получать данные у их источника.
Индивидуальное и групповое обучение «Аналитик данных»
Если вы хотите стать экспертом в аналитике, могу помочь. Запишитесь на мой курс «Аналитик данных» и начните свой путь в мир ИТ уже сегодня!
Контакты
Для получения дополнительной информации и записи на курсы свяжитесь со мной:
Телеграм: https://t.me/Vvkomlev
Email: victor.komlev@mail.ru
Объясняю сложное простыми словами. Даже если вы никогда не работали с ИТ и далеки от программирования, теперь у вас точно все получится! Проверено десятками примеров моих учеников.
Гибкий график обучения. Я предлагаю занятия в мини-группах и индивидуально, что позволяет каждому заниматься в удобном темпе. Вы можете совмещать обучение с работой или учебой.
Практическая направленность. 80%: практики, 20% теории. У меня множество авторских заданий, которые фокусируются на практике. Вы не просто изучаете теорию, а сразу применяете знания в реальных проектах и задачах.
Разнообразие учебных материалов: Теория представлена в виде текстовых уроков с примерами и видео, что делает обучение максимально эффективным и удобным.
Понимаю, что обучение информационным технологиям может быть сложным, особенно для новичков. Моя цель – сделать этот процесс максимально простым и увлекательным. У меня персонализированный подход к каждому ученику. Максимальный фокус внимания на ваши потребности и уровень подготовки.